[DE] ML on Big data: MLlib
Pipeline的最终目的就是学会Spark MLlib,这里先瞧瞧做到心里有数:知道之后要学什么,怎么学。
首要问题
一、哪些机器学习算法可以并行实现?
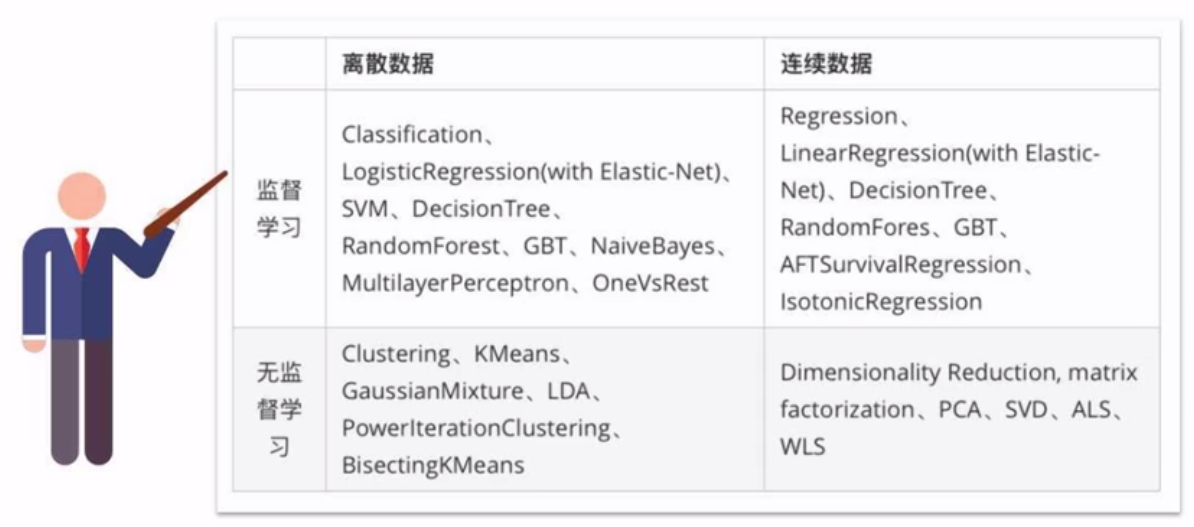
四类算法:分类、回归、聚类、协同过滤
以及特征提取、降维、数据流管理功能。
后者可以与Spark SQL完美结合,支持的算法如下:
二、何为机器学习流水线?
Spark SQL中的DataFrame作为数据集。
Transformer: 打上标签。
Estimator: 训练数据的算法。
parameter: 参数。
最后,通过接口将各个Transformer组装起来构成”数据流“。
>>> pipeline = Pipeline(stags=[stage1,stage2,stage3])
构建文本分类流水线
构建评估器
Tokenizer ----> HashingTF ----> Logistic Regression
参考:[ML] Naive Bayes for Text Classification
tokenizer = Tokenizer(inputCol = "text", outputCol = "words")
hashingTF = HashingTF(inputCol = tokenizer.getOutputCol(), outputCol = "feature")
lr = LogisticRegression(maxIter = 10, regParam = 0.001) # 得到一个评估器
pipeline = Pipeline(stages = [tokenizer, hashingTF, lr])
训练转换器
model = pipeline.fit(training)
测试模型
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"]) # 测试过程
prediction = moel.transform(test) # 展示测试结果
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():
rid, text, prob, prediction = row
print(...)
MLlib的算法教程
一、大数据文件加载
文件格式解析
part-00178-88b459d7-0c3a-4b84-bb5c-dd099c0494f2.c000.snappy.parquet
加载文件
1. 连接spark
2. 创建dataframe
2.1. 从变量创建
2.2. 从变量创建
2.3. 读取json
2.4. 读取csv
2.5. 读取MySQL
2.6. 从pandas.dataframe创建
2.7. 从列式存储的parquet读取
2.8. 从hive读取
3. 保存数据
3.1. 写到csv
3.2. 保存到parquet
3.3. 写到hive
3.4. 写到hdfs
3.5. 写到mysql
注意,这里的 “users.parquet” 是个文件夹!
# 读取example下面的parquet文件
file = r"D:\apps\spark-2.2.0-bin-hadoop2.7\examples\src\main\resources\users.parquet"
df = spark.read.parquet(file)
df.show()
查询数据
Spark2.1.0+入门:读写Parquet(DataFrame)(Python版)
>>> parquetFileDF = spark.read.parquet("file:///usr/local/spark/examples/src/main/resources/users.parquet"
>>> parquetFileDF.createOrReplaceTempView("parquetFile")
>>> namesDF = spark.sql("SELECT * FROM parquetFile")
>>> namesDF.rdd.foreach(lambda person: print(person.name))
Alyssa
Ben
二、AWS S3 文件处理
大文件一般都放在S3中,如何在本地远程处理呢?
其实AWS已经提供了方案:Amazon EMR
三、MLlib算法学习
Welcome to Spark Python API Docs!
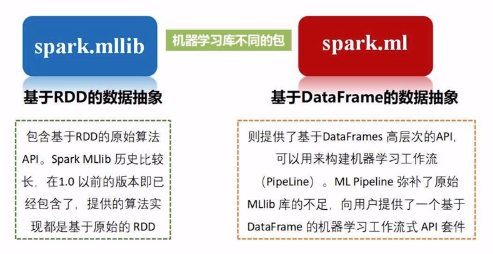
Spark MLlib是Spark中专门用于处理机器学习任务的库,但在最新的Spark 2.0中,大部分机器学习相关的任务已经转移到Spark ML包中。
两者的区别在于MLlib是基于RDD源数据的,而ML是基于DataFrame的更抽象的概念,可以创建包含从数据清洗到特征工程再到模型训练等一系列机器学习工作。
所以,未来在用Spark处理机器学习任务时,将以Spark ML为主。
End.
[DE] ML on Big data: MLlib的更多相关文章
- [AI] 深度数据 - Data
Data Engineering Data Pipeline Outline [DE] How to learn Big Data[了解大数据] [DE] Pipeline for Data Eng ...
- [AWS] 01 - What is Amazon EMR
[DE] ML on Big data: MLlib 关于 Amazon EMR 发布版本 利用 Amazon EMR 分析大数据 Amazon Athena 是一种交互式查询服务,让您能够轻松使用标 ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- Spark的MLlib和ML库的区别
机器学习库(MLlib)指南 MLlib是Spark的机器学习(ML)库.其目标是使实际的机器学习可扩展和容易.在高层次上,它提供了如下工具: ML算法:通用学习算法,如分类,回归,聚类和协同过滤 特 ...
- [ML] LIBSVM Data: Classification, Regression, and Multi-label
数据库下载:LIBSVM Data: Classification, Regression, and Multi-label 一.机器学习模型的参数 模型所需的参数格式,有些为:LabeledPoin ...
- spark:ML和MLlib的区别
ML和MLlib的区别如下: ML是升级版的MLlib,最新的Spark版本优先支持ML. ML支持DataFrame数据结构和Pipelines,而MLlib仅支持RDD数据结构. ML明确区分了分 ...
- [DE] Pipeline for Data Engineering
How to build an ML pipeline for Data Science 垃圾信息分类 Ref:Develop a NLP Model in Python & Deploy I ...
- 【Repost】A Practical Intro to Data Science
Are you a interested in taking a course with us? Learn about our programs or contact us at hello@zip ...
- 使用 Spark MLlib 做 K-means 聚类分析[转]
原文地址:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/ 引言 提起机器学习 (Machine Lear ...
随机推荐
- 【JS档案揭秘】第四集 关于this的讨论到此为止
网上关于this的指向问题的博客文章很多,但大多数都是复制粘贴,也不能用简洁的语言讲清楚,而是不停地写一些示例,看得人云里雾里. 这一集,我只给出结论,以及判定的通用方法,至于是否确实如我所讲,大家可 ...
- Selenium+java - 手把手一起搭建一个最简单自动化测试框架
写在前面 我们刚开始做自动化测试,可能写的代码都是基于原生写的代码,看起来特别不美观,而且感觉特别生硬. 来看下面一段代码,如下图所示: 从上面图片代码来看,具体特征如下: driver对象在测试类中 ...
- Visual Studio 中 Build、Rebuild 、 Clean 之间的区别是什么?
今天翻看c-sharpcorner技术网站看到了这样一篇小记,标题为:What Is The Difference Between Build, Rebuild And Clean In Visual ...
- 神经网络 OCR 参考
1. https://blog.csdn.net/u010159842/article/details/87271554 2. https://blog.csdn.net/weixin_4286104 ...
- 9043Markdown常用用法
1.标题 1.1 方法一:==和--标记 =和-标记语法格式如下: 我是标题一 == 我是标题二 -- 组成: 1标题文字:我是标题一 2回车换行 3标记:== (为一级标题)--(为二级标题) 效果 ...
- GPU服务器安装NVIDIA驱动以及CUDA
1.安装系统 系统版本: ubuntu16.04.05 LTS 分区要求: /boot 1024M swap 64G / 剩余空间
- Liunx学习总结(七)--系统状态查看和统计
sar命令 sar 是一个非常强大的性能分析工具,它可以获取系统的 cpu/等待队列/磁盘IO/内存/网络等性能指标.功能多的必然结果是选项多,应用复杂,但只要知道一些常用的选项足以. 语法 sar ...
- .NET平台下,钉钉微应用开发之:获取userid
工作需求,开发钉钉微应用和小程序,之前有接触过支付宝小程序和生活号的开发,流程没有很大的差别,这里记录下我用ASP.NET MVC实现钉钉微应用的开发,并实现获取用户的userid.小弟我技术有限,本 ...
- Badboy - 导出脚本,用于JMeter并发测试
参考: http://leafwf.blog.51cto.com/872759/1141011 http://www.51testing.com/html/00/130600-1367743.html ...
- [2018CCPC吉林赛区(重现赛)- 感谢北华大学] 补题记录 躁起来
1007 High Priestess 埃及分数 1008 Lovers 线段树维护取膜意义下的区间s和. 每个区间保存前缀lazy和后缀lazy. #include <iostream> ...