利用 python 分析基金,合理分析数据让赚钱赢在起跑线!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 白玉无冰
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
你不理财,财不理你!python 也能帮你理财?
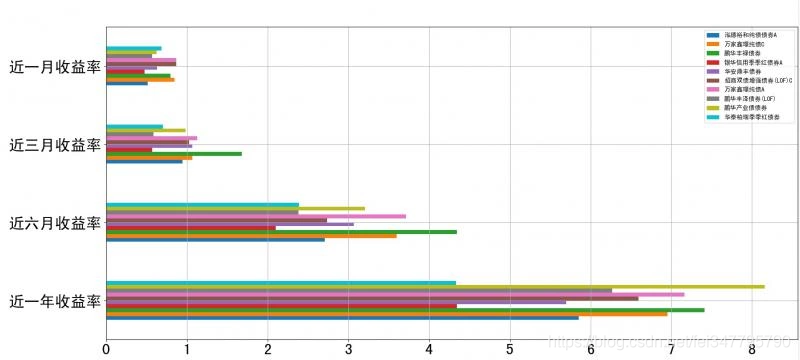
效果预览
累计收益率走势图
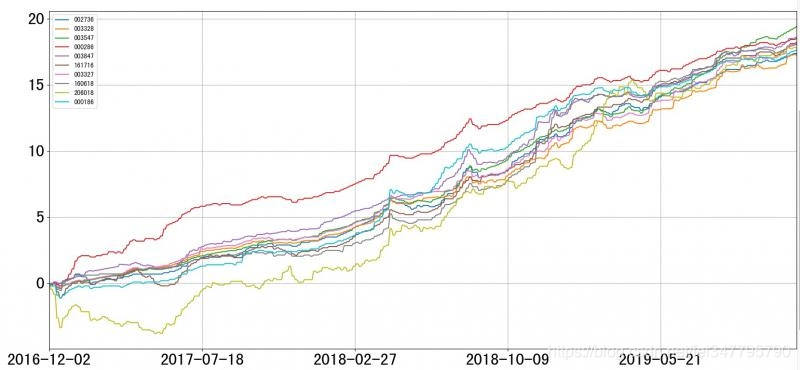
基本信息结果

如何使用:
python3 + 一些第三方库
import requests
import pandas
import numpy
import matplotlib
import lxml
配置 config.json 。code 配置基金代码, useCache 是否使用缓存。
{
"code":[
"",
"",
"",
],
"useCache":true
}
运行 fund_analysis.py
实现原理
数据获取:
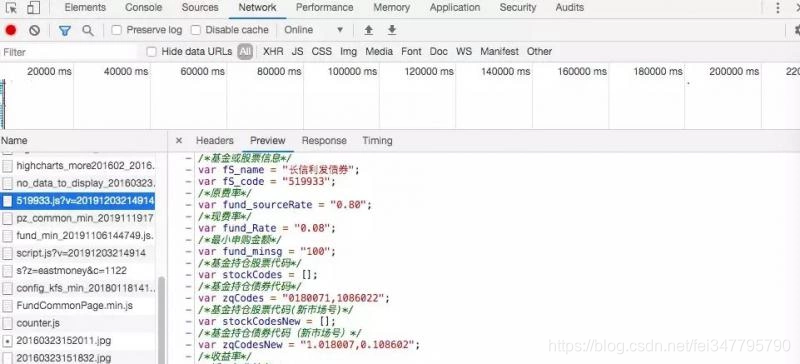
从天天基金网里点开一个基金,在 chrome 开发者工具观察加载了的文件。依次查找发现了一个 js 文件,里面含有一些基金的基本信息。这是一个 js 文件。
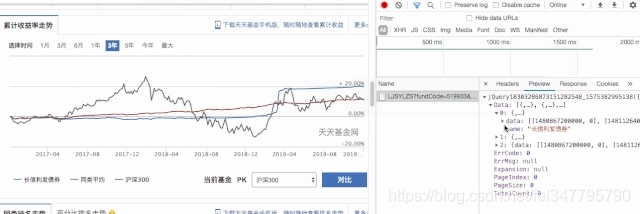
获取累计收益率信息需要在页面做些操作,点击累计收益里的3年,观察开发者工具的请求,很容易找到这个数据源是如何获取的。这是个 json 数据。
基金费率表在另一个页面,我们多找几次可以找到信息源地址。这是个 html 数据。
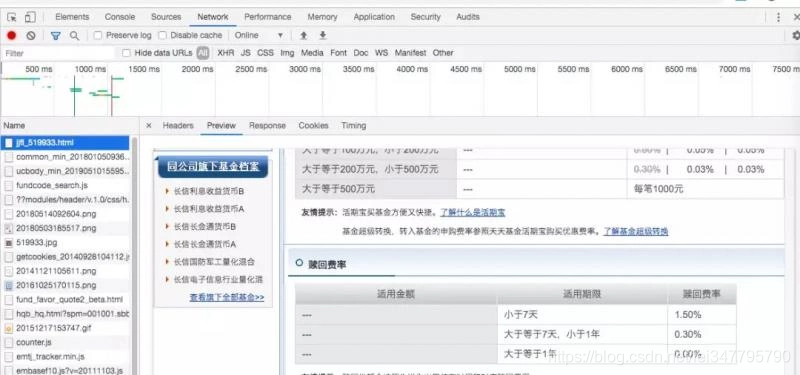
接着通过对 Hearders 的分析,用 request 模拟浏览器获取数据(这里不清楚的话可以参考之前的文章)。最后将其保存在本地作为缓冲使用。以累计收益率信息 json 为例子,主要代码如下。
filePath = f'./cache/{fundCode}.json'
requests_url='http://api.fund.eastmoney.com/pinzhong/LJSYLZS'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'Accept': 'application/json' ,
'Referer': f'http://fund.eastmoney.com/{fundCode}.html',
}
params={
'fundCode': f'{fundCode}',
'indexcode': '',
'type': 'try',
}
requests_page=requests.get(requests_url,headers=headers,params=params)
with open(filePath, 'w') as f:
json.dump(requests_page.json(), f)
数据分析:
对于 基本信息的 js 文件,读取文件后作为字符串,通过正则表达式获取需要的数据。
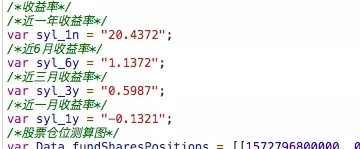
例如获取一年收益率可以用以下代码获取。
syl_1n=re.search(r'syl_1n\s?=\s?"([^\s]*)"',data).group(1);
对于 累计收益率 json 数据,直接用 json 解析,找到需要数据进行筛选加工处理。

采用了 all_data基金代码 = 累计收益率 的格式存储,再通过 pandas 的 DataFrame 进行向上填充空数据。
df = DataFrame(all_data).sort_index().fillna(method='ffill')
对于 基金费率表 html 数据,采用 xpath 解析。xpath 路径可以直接用 chrome 获取。
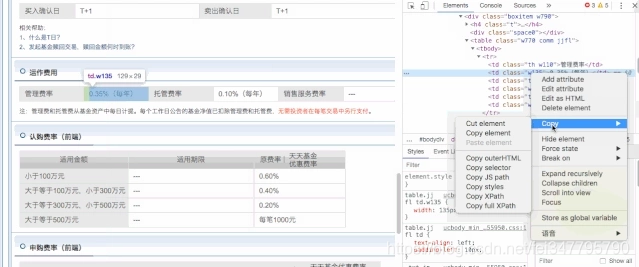
对于管理费率可以参考以下代码。
selector = lxml.html.fromstring(data);
# 管理费率
mg_rate=selector.xpath('/html/body/div[1]/div[8]/div[3]/div[2]/div[3]/div/div[4]/div/table/tbody/tr/td[2]/text()')[0]
数据存储:
使用 DataFrame 中的 plot 可以快速画图,使用 to_excel 保存在 Excel 表中。可以参考以下代码。
# 保存数据
fig,axes = plt.subplots(2, 1)
# 处理基本信息
df2 = DataFrame(all_data_base)
df2.stack().unstack(0).to_excel(f'result_{time.time()}.xlsx',sheet_name='out')
df2.iloc[1:5,:].plot.barh(ax=axes[0],grid=True,fontsize=25)
# 处理收益
df=DataFrame(all_data).sort_index().fillna(method='ffill')
df.plot(ax=axes[1],grid=True,fontsize=25)
fig.savefig(f'result_{time.time()}.png')
小结
数据的获取主要采用了爬虫的基本方法,使用的是 requests 库。而数据的解析和保存主要运用的是正则表达式、xpath解析库以及 pandas 数据处理库。
对于一个基金的分析远远不止于这些数据(例如持仓分布,基金经理信息等),这里只是做个引子,希望能给大家一个思路,如果你有想法或者不懂的地方,欢迎留言或私信交流!
利用 python 分析基金,合理分析数据让赚钱赢在起跑线!的更多相关文章
- 用 python 分析基金!让赚钱赢在起跑线!
你不理财,财不理你!python 也能帮你理财? 效果预览 累计收益率走势图 基本信息结果 如何使用: python3 + 一些第三方库 import requests import pandas i ...
- 利用python进行微信好友分析
欢迎python爱好者加入:学习交流群 667279387 本文主要利用python对个人微信好友进行分析并把结果输出到一个html文档当中,主要用到的python包为itchat,pandas,py ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- 利用python将mysql中的数据导入excel
Python对Excel的读写主要有xlrd.xlwt.xlutils.openpyxl.xlsxwriter几种. 如下分别利用xlwt和openpyxl将mysql数据库中查询的数据保存到exce ...
- 爬虫学习笔记(1)-- 利用Python从网页抓取数据
最近想从一个网站上下载资源,懒得一个个的点击下载了,想写一个爬虫把程序全部下载下来,在这里做一个简单的记录 Python的基础语法在这里就不多做叙述了,黑马程序员上有一个基础的视频教学,可以跟着学习一 ...
- 利用Python读取外部数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素.利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析.数 ...
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- 推荐一个利用 python 生成 pptx 分析报告的工具包:reportgen
reportgen v0.1.8 更新介绍 这段时间,我对 reportgen 进行了大工程量的修改和更新.将之前在各个文章中出现的函数进行了封装,同时也对现有工具包的一些逻辑进行了调整. 1.rep ...
- Python股票分析系列——基础股票数据操作(一).p3
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第3部分.在本教程中,我们将使用我们的股票数据进一步分解一些基本的数据操作和可视化.我们将要使用 ...
随机推荐
- 迈布-----UE4AI自动巡逻与攻击
这个行为树给我恶心的都想吐,我用的是4.24,跟着官网做达不到那个效果,跟着视频做也达不到那个效果,跟我弄的非常不耐烦,最后终于在今天整出来了.有的地方用了一下我自己的逻辑.//诸位依靠教程的,一定得 ...
- 3、看源码MVC中的Controllr的Json方法
无论ViewResult还是JsonResult都继承ActionResult,ActionResult里只有一个方法ExecuteResult 1.Controllr的Json方法 实际上是new ...
- Redis—数据备份与恢复
https://www.cnblogs.com/shizhengwen/p/9283973.html https://blog.csdn.net/w2393040183/article/details ...
- 群晖NAS再再折腾
问题 最近电信把我的公网地址收回去了,之前做好的网络端口映射失效了,在公司已经不能愉快地访问家里的网络.原先网络结构示意图如下: (直接访问方案网络结构图) 只需要对电信光猫(也是个路由器)和家用 ...
- python 打飞机项目 (实战一)
第一步定义 main 函数: # -*- coding=utf-8 -*- import pygame,time from Plane import Plane from pygame.locals ...
- Python 之列表切片的四大常用操作
最近在爬一个网站的文档的时候,老师要求把一段文字切割开来,根据中间的文本分成两段 故学习了一段时间的切片操作,现把学习成果po上来与大家分享 1.何为切片? 列表的切片就是处理列表中的部分元素,是把整 ...
- 【译】如何使用docker-compose安装anchore
如何使用docker-compose安装anchore,本篇译自Install with Docker Compose. Preface 在本节中,您将学习如何启动和运行独立的Anchore引擎安装, ...
- 精通awk系列(10):awk筛选行和处理字段的示例
回到: Linux系列文章 Shell系列文章 Awk系列文章 awk数据筛选示例 筛选行 # 1.根据行号筛选 awk 'NR==2' a.txt # 筛选出第二行 awk 'NR>=2' a ...
- C#中转换运算符explicit、implicit、operator、volatile研究
C#中的这个几个关键字:explicit.implicit与operator,估计好多人的用不上,什么情况,这是什么?字面解释:explicit:清楚明白的;易于理解的;(说话)清晰的,明确的;直言的 ...
- 在Electron中最快速预加载脚本
背景 在Electron打开新窗口的时候,提前加载一段JavaScript脚本,以此内置一些属性或接口给被打开的页面.之所以要以注入方式,而不是页面自己引用,原因是不想麻烦页面自行引用,不想修改旧有的 ...