NameNode数据存储
HDFS架构图
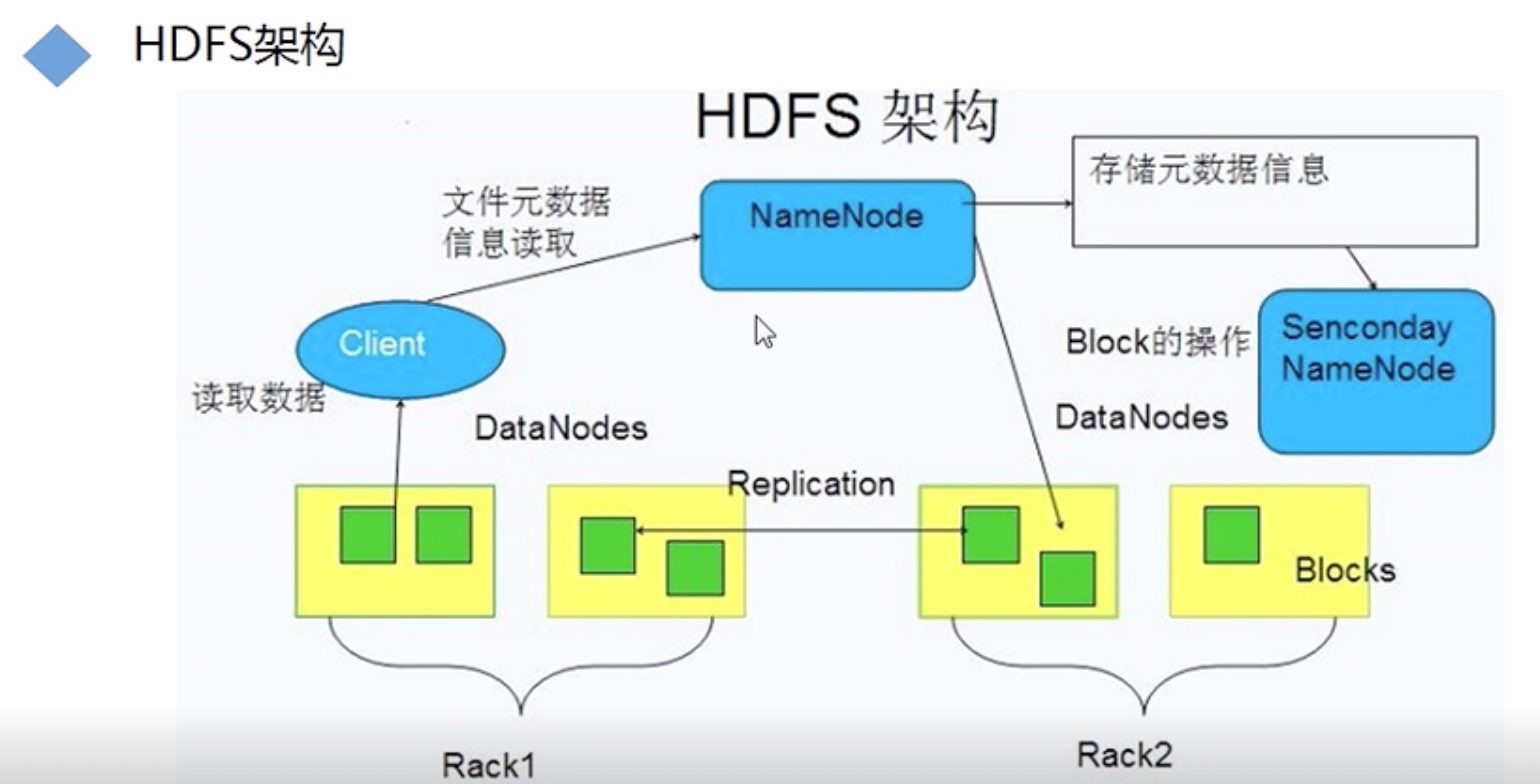
HDFS原理
1) 三大组件
NameNode、 DataNode 、SecondaryNameNode
2)NameNode
存储元数据(文件名、创建时间、大小、权限、文件与block块映射关系)
3)DataNode
存储真实的数据信息
4)SecondaryNameNode
合并edits日志文件和fsimage镜像文件进行合并
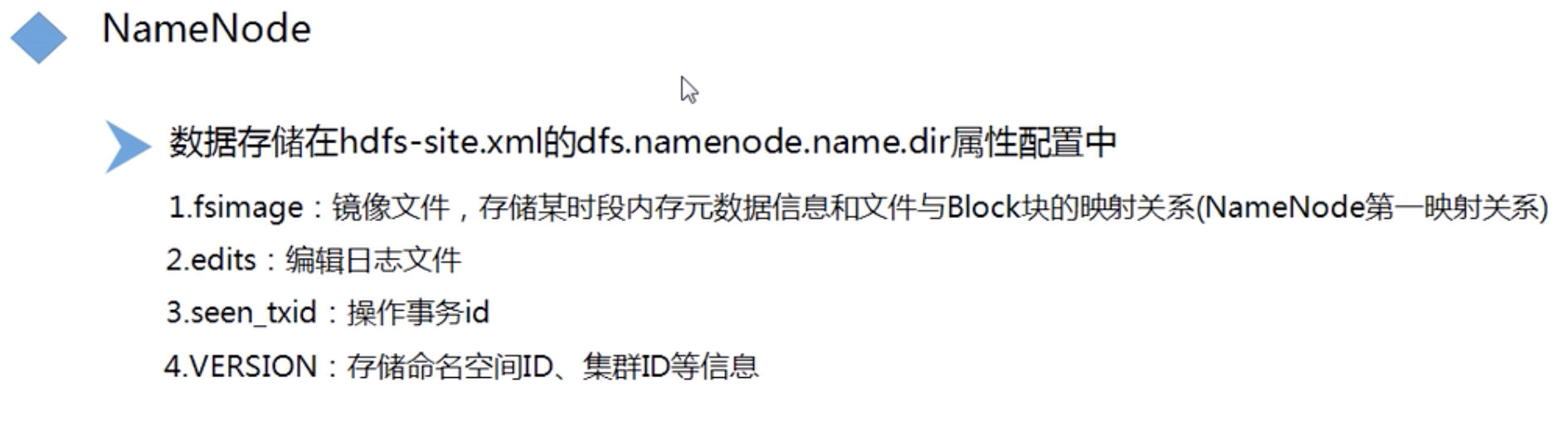
详细信息如下:
其中fsimage_0000000000000000000000属于镜像文件
see_txid操作事务id
其中fsimage_0000000000000000000000.md5属于校验和
VERSION属于版本号,详细信息如下:
(1)dfs.namenode.name.dir file://{$hadoop.tmp.dir}/dfs/name
hadoop.tmp.dir /tmp/hadoop-${user.name}
多次格式化的问题:
hdfs格式化会改变VERSION文件中的clusterID, 首次格式化时datanode和namenode会产生相同的clusterID;
如果重新执行格式化,namenode的clusterID改变,就会愈datanode的cluseterID不一致,如果重启或者读写hdfs,就会挂掉
(2)dfs.datanode.data.dir file://${hadoop.tmp.dir}/dfs/data
hadoop.tmp.dir /tmp/hadoop-${user.name}
例:/tmp/hadoop-root/dfs目录下:
name、data、namesecondary
(3)dfs.namenode.checkpoint.dir file://{hadoop.tmp.dir}/dfs/namesecondary
tmp/hadoop-${user.name}/dfs/name或者 tmp/hadoop-${user.name}/dfs/data下的datanode和namenode信息在系统
在重启时,会被清空处理。为了防止数据丢失,接下来我们更改路径存储,以namenode为例:
配置hdfs信息如下:将namenode数据存储在data/name下面
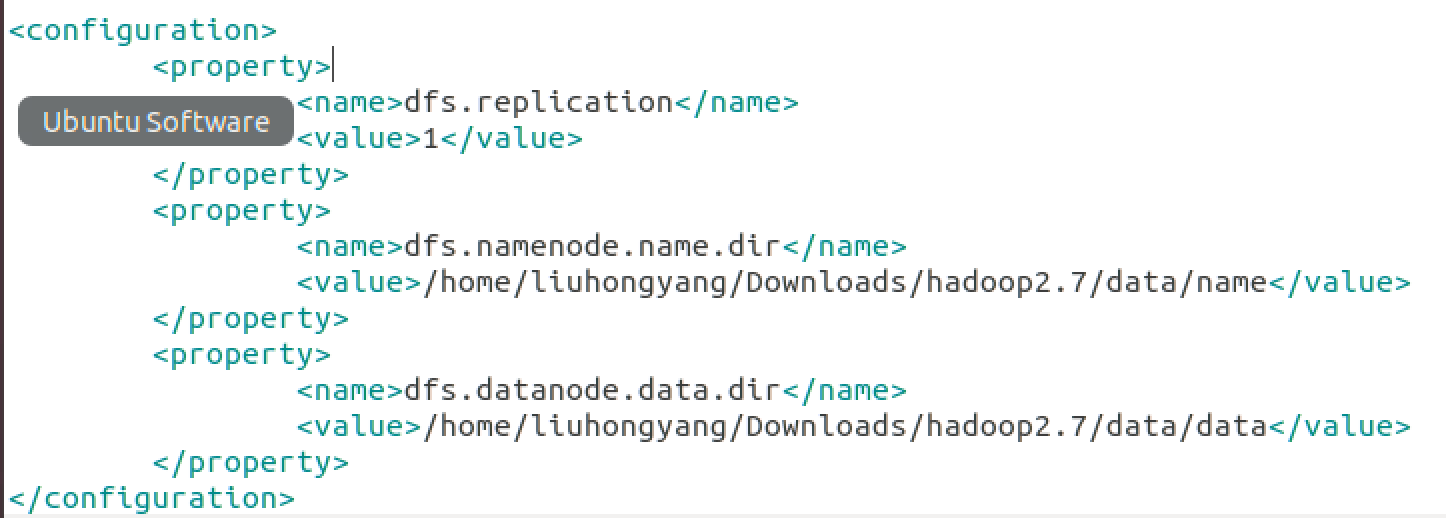
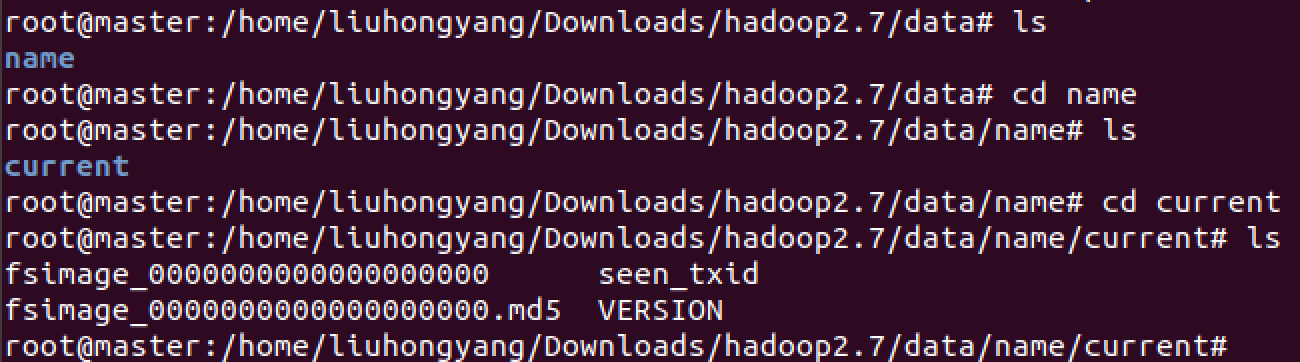
在执行格式化之前,查询data下的目录信息:

进行格式化:
hdfs namenode -format -force
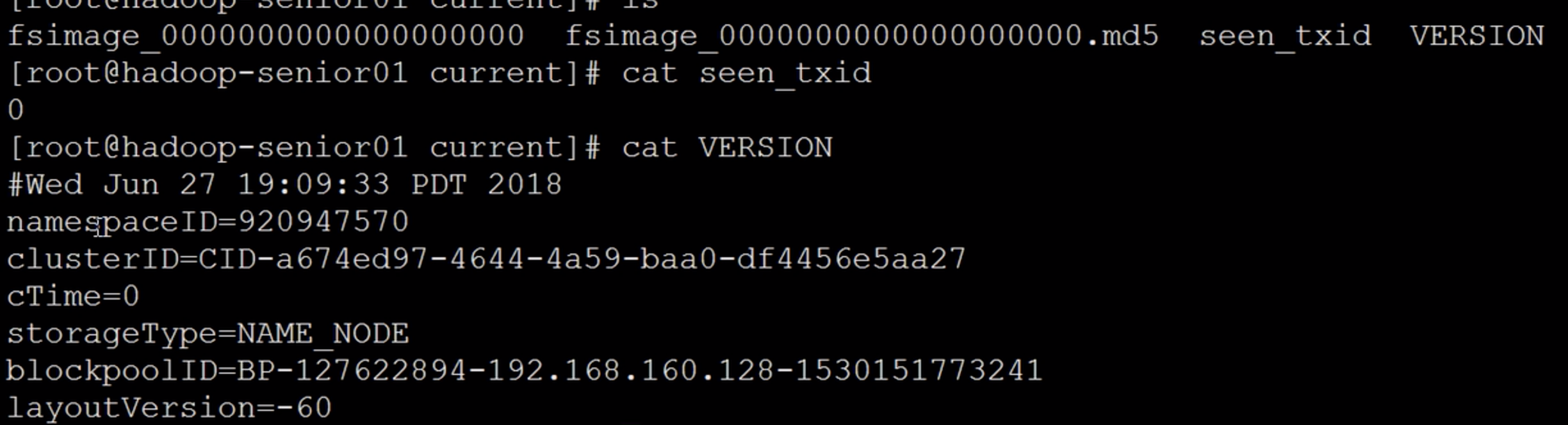
格式化之后,在data/name/current下查看name信息
NameNode数据存储的更多相关文章
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- [HDFS_add_2] SecondaryNameNode 滚动 NameNode 数据流程
0. 说明 在 将 SecondaryNameNode 配置到 s105 节点上 的基础上进行 SecondaryNameNode 滚动 NameNode 数据流程 分析 1. SecondaryNa ...
- 网易大数据之数据存储:HDFS
一.HDFS基础架构 1.HDFS特点:水平扩展.高容错性.廉价硬件.开源生态系统 2.Hadoop生态圈 1).分布式存储系统(HDFS),2).资源管理框架(YARN),3).批处理框架(MapR ...
- 大数据存储的进化史 --从 RAID 到 Hdfs
我们都知道现在大数据存储用的基本都是 Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdfs. 我们先来 ...
- 【solr】SolrCloud中索引数据存储于HDFS
SolrCloud中索引数据存储于HDFS 本人最近使用SolrCloud存储索引日志条件,便于快速索引,因为我的索引条件较多,每天日志记录较大,索引想到将日志存入到HDFS中,下面就说说怎么讲sol ...
- BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一.引言 时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势: 越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库, ...
- 大数据软件安装之Hadoop(Apache)(数据存储及计算)
大数据软件安装之Hadoop(Apache)(数据存储及计算) 一.生产环境准备 1.修改主机名 vim /etc/sysconfig/network 2.修改静态ip vim /etc/udev/r ...
- Kooboo CMS技术文档之三:切换数据存储方式
切换数据存储方式包括以下几种: 将文本内容存储在SqlServer.MySQL.MongoDB等数据库中 将站点配置信息存储在数据库中 将后台用户信息存储在数据库中 将会员信息存储在数据库中 将图片. ...
- Android之数据存储的五种方法
1.Android数据存储的五种方法 (1)SharedPreferences数据存储 详情介绍:http://www.cnblogs.com/zhangmiao14/p/6201900.html 优 ...
随机推荐
- Spring IoC源码解析之invokeBeanFactoryPostProcessors
一.Bean工厂的后置处理器 Bean工厂的后置处理器:BeanFactoryPostProcessor(触发时机:bean定义注册之后bean实例化之前)和BeanDefinitionRegistr ...
- spring-boot-starter-quartz集群实践
[**前情提要**]由于项目需要,需要一个定时任务集群,故此有了这个spring-boot-starter-quartz集群的实践.springboot的版本为:2.1.6.RELEASE:quart ...
- 消息中间件-activemq消息机制和持久化介绍(三)
前面一节简单学习了activemq的使用,我们知道activemq的使用方式非常简单有如下几个步骤: 创建连接工厂 创建连接 创建会话 创建目的地 创建生产者或消费者 生产或消费消息 关闭生产或消费者 ...
- Vue系列:Websocket 使用配置
WebSocket 是什么? WebSocket 是一种网络通信协议.而且是在 HTML5 才开始提供的一种在单个 TCP 连接上进行全双工通讯的协议. 为什么需要 WebSocket ? 了解计算 ...
- 【POJ - 3255】Roadblocks(次短路 Dijkstra算法)
Roadblocks 直接翻译了 Descriptions Bessie搬到了一个新的农场,有时候他会回去看他的老朋友.但是他不想很快的回去,他喜欢欣赏沿途的风景,所以他会选择次短路,因为她知道一定有 ...
- 洛谷 P4127 [AHOI2009]同类分布
题意简述 求l~r之间各位数字之和能整除原数的数的个数. 题解思路 数位DP 代码 #include <cstdio> #include <cstring> typedef l ...
- Python获取系统交互式shell,跨平台
本文地址:https://www.cnblogs.com/M4K0/p/9044237.html 昨天搞了半天,终于把这两个环节打通了.后续可以进一步调用adb命令执行一些操作,细节说明已在代码中添加 ...
- Linux任务调度(8)
crond任务调度: 是指系统在某个时间执行特定的命令或程序. 分类:1.系统工作,有些重要的工作必须周而复始地执行,如病毒扫描等:2.个别用户工作,个别用户可能希望执行某些程序,如mysql数据库备 ...
- 在vue.js引用图片的问题
<div id="img"> <img src="img.png" class="img"> </div> ...
- H5 API编码、解码
方式一.decodeURI 解码 encodeURI 编码 方式二. var str = 'hello'; //加密 data base 64编码 组成部分 0-9 a-z A-Z +/ = 64位个 ...