字符串匹配(hash算法)
hash函数对大家来说不陌生吧 ?
而这次我们就用hash函数来实现字符串匹配。
首先我们会想一下二进制数。
对于任意一个二进制数,我们将它化为10进制的数的方法如下(以二进制数1101101为例):
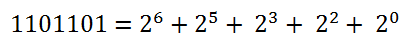
hash用的也是一样的原理,为每一个前缀(也可以后缀,笔者习惯1 base,所以喜欢用前缀来计算,Hash[i] = Hash[i - 1] * x + s[i](其中1 < i <= n,Hash[0] = 0)。
一般地,
而对于l - r区间的hash值,则为:
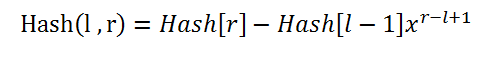
但是如果n很大呢?那样不是会溢出了吗?
因此我们把hash值储存在unsigned long long里面, 那样溢出时,会自动取余2的64次方,but这样可能会使2个不同串的哈希值相同,但这样的概率极低(不排除你的运气不好)。
因此我们可以通过Hash值来比较两个字符串是否相等。
给出多项式hash的处理:
typedef unsigned long long ull;
const int N = 100000 + 5;
const ull base = 163;
char s[N];
ull hash[N]; void init(){//处理hash值
p[0] = 1;
hash[0] = 0;
int n = strlen(s + 1);
for(int i = 1; i <=100000; i ++)p[i] =p[i-1] * base;
for(int i = 1; i <= n; i ++)hash[i] = hash[i - 1] * base + (s[i] - 'a');
} ull get(int l, int r, ull g[]){//取出g里l - r里面的字符串的hash值
return g[r] - g[l - 1] * p[r - l + 1];
}
我们来看到题目吧:传送门
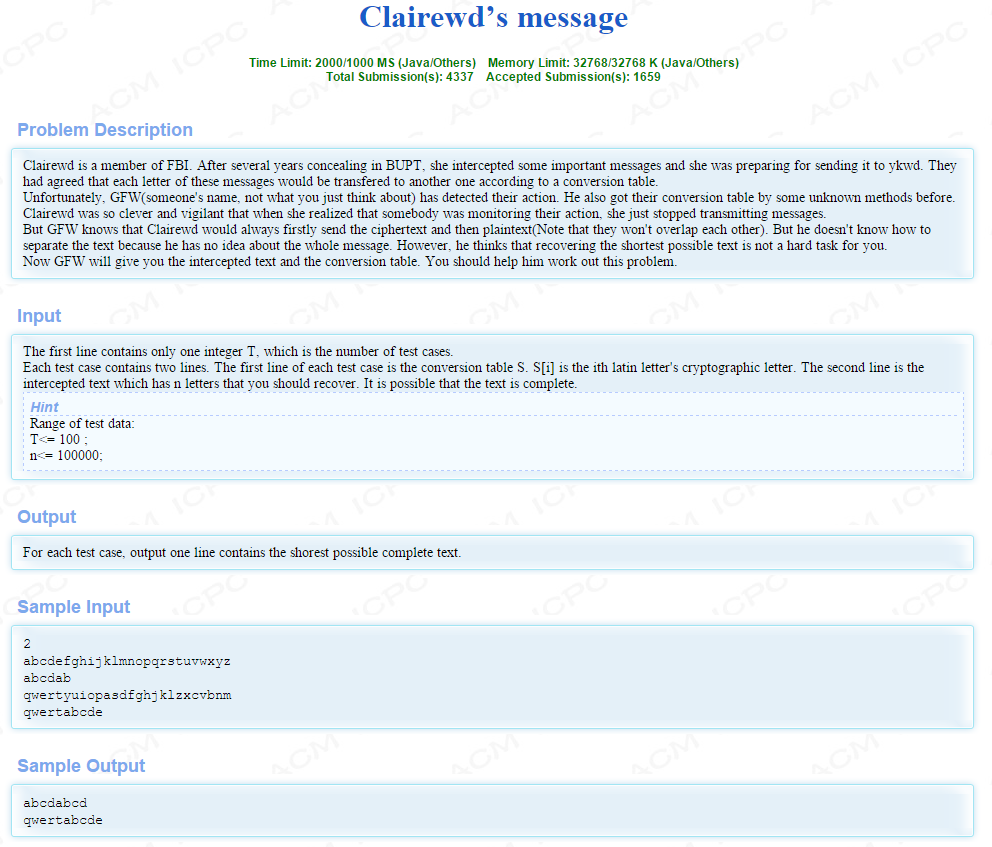
题目大意:
是有一份文件,前面是密文,后面是原文,但那个人接到这个文件后不知道中间从哪里开始是原文,所以你要帮忙还原一下,如果后面原文比密文少,你就将它补全, 第一行是密文转换格式,例如第二个样例表示将q翻译成a,w翻译成b。
思路:
我们只要先把密文都翻译成明文,然后去比较原来的字符串的后缀和翻译之后的字符串前缀的最长匹配长度就行(注:最长匹配的长度不能超过原长的一半)
hash水题(附AC代码):
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
typedef unsigned long long ull;
const int N = 100000 + 5;
const ull base = 163;
ull Hash1[N], Hash2[N], p[N]; char s[N], t[30], r[N]; int T; int c[30]; void init(){
p[0] = 1;
for(int i = 1; i <=100000; i ++)p[i] =p[i-1] * base;
} ull get(int l, int r, ull g[]){
return g[r] - g[l - 1]*p[r - l + 1];
} void work(){
for(int i = 0; i < 26; i ++) c[t[i] - 'a'] = i;
//puts(r+1);
int n = strlen(s + 1);
Hash1[0] = Hash2[0] = 0;
for(int i = 1; i <= n; i ++){
Hash1[i] = Hash1[i - 1] * base + (s[i] - 'a');
Hash2[i] = Hash2[i - 1] * base + (c[s[i] - 'a']);
}
int ans = n;
for(int i = n; i < n * 2; i ++){
if(i & 1) continue;
int tmp = i / 2;
int len =n - tmp;
ull s1 = get(1, len, Hash2);
ull s2 = get(n - len + 1, n, Hash1);
if(s1 == s2){
ans = tmp;
break;
}
//printf("%llu %llu\n", s1, s2);
}
//printf("ans = %d\n", ans);
for(int i = 1; i <= ans; i ++)printf("%c", s[i]);
for(int i = 1; i <= ans; i ++)printf("%c", c[s[i]-'a'] + 'a');
puts("");
} int main(){
scanf("%d", &T);
init();
while(T--){
scanf("%s%s", t, s + 1);
work();
}
return 0;
}
字符串匹配(hash算法)的更多相关文章
- 字符串匹配KMP算法详解
1. 引言 以前看过很多次KMP算法,一直觉得很有用,但都没有搞明白,一方面是网上很少有比较详细的通俗易懂的讲解,另一方面也怪自己没有沉下心来研究.最近在leetcode上又遇见字符串匹配的题目,以此 ...
- 字符串匹配Boyer-Moore算法:文本编辑器中的查找功能是如何实现的?---这应该讲的最容易懂的文章了!
关于字符串匹配算法有很多,之前我有讲过一篇 KMP 匹配算法:图解字符串匹配 KMP 算法,不懂 kmp 的建议看下,写的还不错,这个算法虽然很牛逼,但在实际中用的并不是特别多.至于选择哪一种字符串匹 ...
- 通用高效字符串匹配--Sunday算法
字符串匹配(查找)算法是一类重要的字符串算法(String Algorithm).有两个字符串, 长度为m的haystack(查找串)和长度为n的needle(模式串), 它们构造自同一个有限的字母表 ...
- 字符串匹配--Karp-Rabin算法
主要特征 1.使用hash函数 2.预处理阶段时间复杂度O(m),常量空间 3.查找阶段时间复杂度O(mn) 4.期望运行时间:O(n+m) 本文地址:http://www.cnblogs.com/a ...
- 字符串匹配常见算法(BF,RK,KMP,BM,Sunday)
今日了解了一下字符串匹配的各种方法. 并对sundaysearch算法实现并且单元. 字符串匹配算法,是在实际工程中经常遇到的问题,也是各大公司笔试面试的常考题目.此算法通常输入为原字符串(strin ...
- 字符串匹配&Rabin-Karp算法讲解
问题描述: Rabin-Karp的预处理时间是O(m),匹配时间O( ( n - m + 1 ) m )既然与朴素算法的匹配时间一样,而且还多了一些预处理时间,那为什么我们还要学习这个算法呢?虽然Ra ...
- 字符串匹配KMP算法
1. 字符串匹配的KMP算法 2. KMP算法详解 3. 从头到尾彻底理解KMP
- 字符串匹配--kmp算法原理整理
kmp算法原理:求出P0···Pi的最大相同前后缀长度k: 字符串匹配是计算机的基本任务之一.举例,字符串"BBC ABCDAB ABCDABCDABDE",里面是否包含另一个字符 ...
- 算法——字符串匹配Rabin-Karp算法
前言 Rabin-Karp字符串匹配算法和前面介绍的<朴素字符串匹配算法>类似,也是相应每一个字符进行比較.不同的是Rabin-Karp採用了把字符进行预处理,也就是对每一个字符进行相应进 ...
随机推荐
- Cloud9:解决ThinkPHP在C9上运行时连接数据库时报错"No such file or directory"的问题
昨天尝试在c9上部署了一个ThinkPHP用于开发,但是当试图连接数据库时却出现了这样的问题.经过查找资料发现此问题是由于没有找到mysql.sock这个文件造成的(这个东西估计是mysql的连接线程 ...
- 让UNION与ORDER BY并存于SQL语句当中
在SQL语句中,UNION关键字多用来将并列的多组查询结果(表)合并成一个结果(表),简单实例如下: SELECT [Id],[Name],[Comment] FROM [Product1] UNIO ...
- mysql5.6主从参数详解
mysql5.6的主从相当的不错,增加了不少参数,提升了主从同步的安全和效率,以下是mysql5.6主从参数详解. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...
- mysql-3 检索数据(1)
SELECT 语句 SELECT检索表数据,必须至少给出两条信息--------想选择什么,以及从什么地方选择. 检索一个列 SELECT prod_name FROM products; 上述语句利 ...
- winform 可拖动的自定义Label控件
效果预览: 实现步骤如下: (1)首先在项目上右击选择:添加->新建项,添加自定义控件 (2)自定义的一个Label让它继承LabelControl控件,LabelControl控件是DevEx ...
- 数据分页处理系列之一:Oracle表数据分页检索SQL
关于Oracle数据分页检索SQL语法,网络上比比皆是,花样繁多,本篇也是笔者本人在网络上搜寻的比较有代表性的语法,绝非本人原创,贴在这里,纯粹是为了让"数据分页专题系列"看起 ...
- DuiLib学习笔记(二) 扩展CScrollbar属性
DuiLib学习笔记(二) 扩展CScrollbar属性 Duilib的滚动条滑块默认最小值为滚动条的高度(HScrollbar)或者宽度(VScrollbar).并且这个值默认为16.当采用系统样式 ...
- android AsyncTask实例
.java package com.example.activitydemoay; import android.app.Activity; import android.content.Intent ...
- /proc/interrupts 统计2.6.38.8与3.10.25差异
eth4进,eth5出 linux-3.10.25 67: 2 3 2 3 PCI-MSI-edge eth468: ...
- linux centos使用xrdp远程界面登陆
redhat6 安装xrdp 直接使用windows远程桌面连接登陆 下面介绍实现方法: 第一步:下载源码包,并安装一些依赖的软件下载xrdp源码包 wget http://downloads.so ...