sql分组(orderBy、GroupBy)获取每组前一(几)条数据
sql数据库实现分组并取每组的前1(几)条数据
测试数据准备工作:
根据某一个字段分组取最大(小)值所在行的数据:
创建表并且插入数据
CREATE table Test_orderByOrGroupBy_tb(Name nvarchar(50),Val int,Describe nvarchar(50))
insert into Test_orderByOrGroupBy_tb values('a', 1, 'a1--a的第一个值')
insert into Test_orderByOrGroupBy_tb values('b', 2, 'b2b2b2b2b2b2b2b2b值')
insert into Test_orderByOrGroupBy_tb values('a', 2, 'a2(a的第二个值)')
insert into Test_orderByOrGroupBy_tb values('b', 1, 'b1--b的第一个值')
insert into Test_orderByOrGroupBy_tb values('a', 3, 'a3:a的第三个值')
insert into Test_orderByOrGroupBy_tb values('b', 3, 'b3:b的第三个值')
insert into Test_orderByOrGroupBy_tb values('c', 1, 'c1c1c1c1c1c1c1c1c1c1c值')
insert into Test_orderByOrGroupBy_tb values('b', 5, 'b5b5b5b5b5b5b5b5b5b5值')
insert into Test_orderByOrGroupBy_tb values('c', 2, 'c2c2c2c2c2c2c2c2c2c2值')
insert into Test_orderByOrGroupBy_tb values('b', 4, 'b4b4b4b4b4b4b4b4b值')
GO
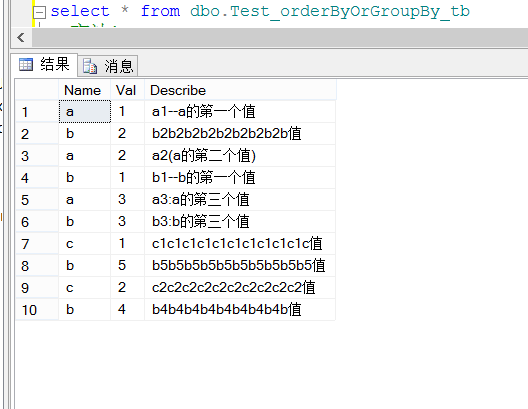
1、根据Name分组取Val最大的值所在行的数据。
Sql语句代码如下:
--方法1:
select a.* from Test_orderByOrGroupBy_tb a where Val = (select max(Val) from Test_orderByOrGroupBy_tb where Name = a.Name) order by a.Name
--方法2:
select a.* from Test_orderByOrGroupBy_tb a,(select Name,max(Val) Val from Test_orderByOrGroupBy_tb group by Name) b where a.Name = b.Name and a.Val = b.Val order by a.Name
--方法3:
select a.* from Test_orderByOrGroupBy_tb a inner join (select Name,max(Val) Val from Test_orderByOrGroupBy_tb group by Name) b on a.Name = b.Name and a.Val = b.Val order by a.Name
--方法4:
select a.* from Test_orderByOrGroupBy_tb a where 1 > (select count(*) from Test_orderByOrGroupBy_tb where Name = a.Name and Val > a.Val ) order by a.Name --其中1表示获取分组中前一条数据
--方法5:
select a.* from Test_orderByOrGroupBy_tb a where not exists(select 1 from Test_orderByOrGroupBy_tb where Name = a.Name and Val > a.Val)
上面的5种方法的sql执行执行结果一样,结果如下图:

2、根据Name分组取Val最小的值所在行的数据。
--方法1:
select a.* from Test_orderByOrGroupBy_tb a where Val = (select min(Val) from Test_orderByOrGroupBy_tb where Name = a.Name) order by a.Name
--方法2:
select a.* from Test_orderByOrGroupBy_tb a,(select Name,min(Val) Val from Test_orderByOrGroupBy_tb group by Name) b where a.Name = b.Name and a.Val = b.Val order by a.Name
--方法3:
select a.* from Test_orderByOrGroupBy_tb a inner join (select Name,min(Val) Val from Test_orderByOrGroupBy_tb group by Name) b on a.Name = b.Name and a.Val = b.Val order by a.Name
--方法4:
select a.* from Test_orderByOrGroupBy_tb a where 1 > (select count(*) from Test_orderByOrGroupBy_tb where Name = a.Name and Val < a.Val ) order by a.Name --其中1表示获取分组中前一条数据
--方法5:
select a.* from Test_orderByOrGroupBy_tb a where not exists(select 1 from Test_orderByOrGroupBy_tb where Name = a.Name and Val < a.Val)
上面5种方法执行结果是一样的,如下图:

3、根据Name分组取第一次出现的行所在的数据。
select a.* from Test_orderByOrGroupBy_tb a where a.Val = (select top 1 val from Test_orderByOrGroupBy_tb where a.Name = a.Name) order by a.Name
执行结果如下图:

4、根据Name分组随机取一条数据
select a.* from Test_orderByOrGroupBy_tb a where a.Val = (select top 1 Val from Test_orderByOrGroupBy_tb where Name = a.Name order by newid()) order by a.Name
运行几次执行结果如下图:

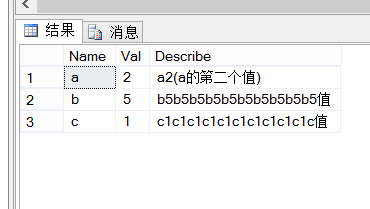

5、根据Name分组取最大的两个(N个)Val
--方法一:
select a.* from Test_orderByOrGroupBy_tb a where 2 > (select count(*) from Test_orderByOrGroupBy_tb where Name = a.Name and Val > a.Val ) order by a.Name,a.Val
--方法二:
select a.* from Test_orderByOrGroupBy_tb a where val in (select top 2 val from Test_orderByOrGroupBy_tb where Name=a.Name order by Val desc) order by a.Name,a.Val
--方法三:
SELECT a.* from Test_orderByOrGroupBy_tb a where exists (select count(*) from Test_orderByOrGroupBy_tb where Name = a.Name and Val > a.Val having Count(*) < 2) order by a.Name
上面的三种方法执行结果是一致的如下图:

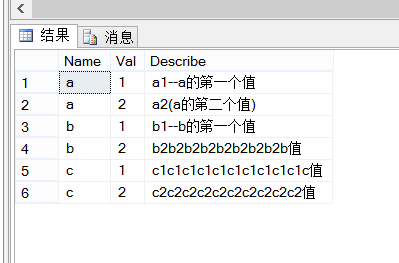
6、根据Name分组取最小的两个(N个)Val
--方法一:
select a.* from Test_orderByOrGroupBy_tb a where 2 > (select count(*) from Test_orderByOrGroupBy_tb where Name = a.Name and val < a.val ) order by a.name,a.val
--方法二:
select a.* from Test_orderByOrGroupBy_tb a where val in (select top 2 val from Test_orderByOrGroupBy_tb where name=a.name order by val) order by a.name,a.val
--方法三
SELECT a.* from Test_orderByOrGroupBy_tb a where exists (select count(*) from Test_orderByOrGroupBy_tb where Name = a.Name and val < a.val having Count(*) < 2) order by a.name
上面的三种方法执行的结果一致如下图:
sql分组(orderBy、GroupBy)获取每组前一(几)条数据的更多相关文章
- SQL 分组后只获取每组的一条数据
/****** Object: Table [dbo].[TEMP] Script Date: 2018-8-22 星期三 23:33:09 ******/ SET ANSI_NULLS ON GO ...
- Sqlserver 如何获取每组中的第一条记录
在日常生活方面,我们经常需要记录一些操作,类似于日志的操作,最后的记录才是有效数据,而且可能它们属于不同的方面.功能下面,从数据库的术语来说,就是查找出每组中的一条数据. 例子 我们要从上面获得的有效 ...
- python 获取当天和前几天时间数据
python 获取当天和前几天时间数据 import datetime from datetime import datetime, date, timedelta def dayDateRange( ...
- SQL分组查询GroupBy
一.分组查询1.使用group by进行分组查询在使用group by关键字时,在select列表中可以指定的项目是有限制的,select语句中仅许以下几项:〉被分组的列〉为每个分组返回一个值得表达式 ...
- SQL分组排序后取每组最新一条数据的另一种思路
在hibernate框架和mysql.oracle两种数据库兼容的项目中实现查询每个id最新更新的一条数据. 之前工作中一直用的mybatis+oracle数据库这种,一般写这类分组排序取每组最新一条 ...
- MYSQL 按某个字段分组,然后取每组前3条记录
先初始化一些数据,表名为 test ,字段及数据为: SQL执行结果为:每个 uid 都只有 3 条记录. SQL语句为: SELECT * FROM test main WHERE ...
- mysql在group by分组后查询第二条/第三条乃至每组中任意一条数据
昨天老板让我查询项目中(众筹),没人刚发起感召后,前三笔钱的入账时间和金额,这把大哥整懵逼了,group by在某些方面是好使,但这次不能为我所用了,获取第一笔进账是简单,可以用group by 直接 ...
- ajax的get方法获取豆瓣电影前10页的数据
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 11:45 # @Author : 秋泊酱 # 1页数据 电影条数20 # https://movie.dou ...
- 【sql进阶】查询每天、每个设备的第一条数据
需求如下 每个设备(不同DeviceID).每天会向数据库插入多条数据,求每天.每个设备插入的第一条数据. 下面SQL中的 ShareRecommendID 类比不同设备的DeviceID. ROW_ ...
随机推荐
- 我与solr(三)--solr后台相关介绍
1.DashBoard: 介绍了当前solr的相关信息,运行时间,版本信息,java虚拟机的配置信息. 注意我们的solr与lucence的版本号是保持一致的,而不同的lucence版本也需要对应的j ...
- webpack入门指南(转载)
什么是 webpack? webpack是近期最火的一款模块加载器兼打包工具,它能把各种资源,例如JS(含JSX).coffee.样式(含less/sass).图片等都作为模块来使用和处理. 我们可以 ...
- #ing# CSS细节注意点
目录: 常用简写 权重(优先级) Hack 常用简写 权重(优先级) Hack etc
- 使用<c:if>标签处理页面数据
使用${feeList.feeType}来取值的时候,因为定义的是数值,刚好看到<c:if>标签的使用,套用代码如下 <td> <c:if test="${fe ...
- 学习django之构建Web是Meta嵌套类的几处使用
Django中meta嵌套类的使用 1.模型中使用嵌套类 在定义抽象模型时如: class Meta : abstract=true 用来指明你创建的模型是一个抽象基础类的模型继承. 2.在一个对象对 ...
- 搭建一个SSH项目框架的步骤
1.导入jar包(38个) 2.配置文件 applicationContext,xml (beans.xml) (数据源.LocalSessionFactoryBean.事务管理器.事务通知.AOP切 ...
- vim插件神器spf13在Linux上的安装
官网给出的安装办法很简单: curl http://j.mp/spf13-vim3 -L -o - | sh 可惜有问题: connection reset by peer 正确的姿势是: curl ...
- (原创)Louis Aston Knight 的家(摄影,欣赏)
本文图片转自腾讯文化:www.cal.qq.com 1.Abstract 记忆中的家,深情刻画. 2.Content 图1 图2 图3 图4 图5 图6 图7 图8 图9 图10 图10 图1 ...
- [OLE DB 源 [1]] 警告: 无法从 OLE DB 访问接口检索列代码页信息。如果该组件支持“DefaultCodePage”属性,将使用来自该属性的代码页。如果当前的字符串代码页值不正确,请更改该属性的值。如果该组件不支持该属性,将使用来自该组件的区域设置 ID 的代码页。
SSIS的警告信息,虽然不影响使用,但是对于一个有强迫症的人来说,实在痛苦, 解决办法:控件右键--属性--AlaywayseUseDefaultCodePage 修改成True即可,默认为False
- Linux之yum安装软件