storm基础系列之一----storm并发度概念剖析
前言:
学了几天storm的基础,发现如果有hadoop基础,再理解起概念来,容易的多。不过,涉及到一些独有的东西,如调度,如并发度,还是很麻烦。那么,从这一篇开始,力争清晰的梳理这些知识。
在正式学习并发之前,有必要先明确几个基本概念的定义,以及具体作用。
一、基础概念
1.1 Topology 原意拓扑。可以把他理解为是hadoop中的job,他是把一系列的任务项组装后的一个结果。
1.2 Spout 是任务的一种,作用是读取数据,然后组装成一定的格式,发射出去。
1.3 Bolt 是另一种任务,接收Spout或者上级Bolt发射的任务,进行处理。处理后,也有发射功能,当然如果已经处理完成,也可以作为叶子节点不再发射。
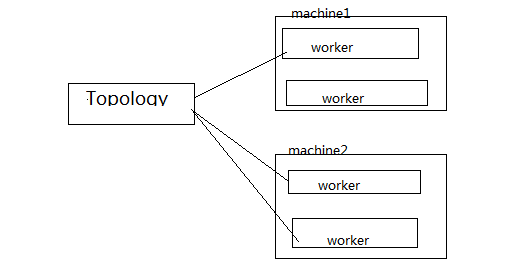
1.4 worker 进程,占用独立的jvm,每台机器都可以拥有多个worker。一个Topology,出于分布式的设计,都会把任务分配到多台机器去执行。那么,相应的,也就是分给了一组可能不在同一台机器上的worker。 反过来理解,一个worker里有一个Topology的任务集合的子集,注意不会再包含另一个Topology的任务。
如图:
1.5 executor 执行者,就是我们在代码里,setspout或setbolt时,指定的数值。可以把他看做是线程。在一个work进程里,可以有多个线程。 每个组件component (spout或bolt)由一个或多个executor来执行。这一层概念,是细化到了Topology的内层,也就是具体每个Spout、Bolt上了。也就是说,这一段代码要并行执行的数目。
1.6 task 具体的逻辑处理单元。或者可以叫任务。有多少个task就实例化多少个组件(注意,实例化并不是执行,执行由executor来负责),通常情况下,一个executor线程可以执行一个或同时执行多个task任务,默认是一个。 task数不会改变,而executor数会变。当task数更大些时,实际并发数就是executor的数目。从这里可以看出,task也是从具体的组件层面来定义的。task是一个静态的概念,而executor是动态的概念,是执行者,比如,我配置了task=100,那么就有100个任务等待执行,我再配置executor=10,这意思就是有十个执行者(即10个线程)并发来执行者100个task(内存有100个对象,供调度执行)。
需要指出的是,executor的数量应该小于等于task数量。task可以不设置,不设置默认就是取的executor的数量。
这里有一张经典的图:
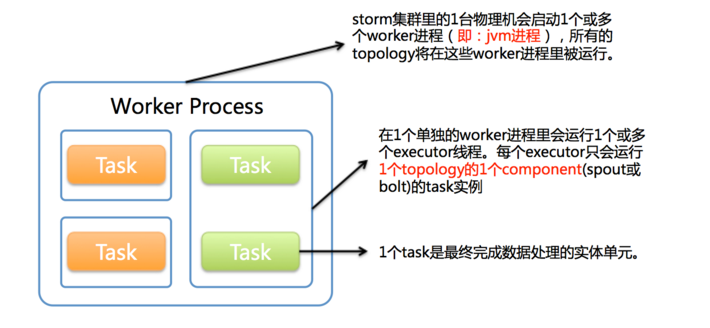
这张图中有一点可以指出,右边的那个executor里,是有两个task的,在这个线程里,会循环调用这两个task,不过这两个task应该是对应同一个组件的。
1.7 component 组件,值得是spout或者bolt。
1.8 nimbus 任务分发调度者,相当于JobTracker。
1.9 supervisor 作业执行者,相当于taskTracker。
二、并发度配置
2.1 理清了上述的概念,那么接下来我们梳理下,并发度配置的相关细节:
worker,可在代码中或配置文件中配置。数目最好大于机器数目。conf.setNumWorkers(2)
executor,代码中配置,setBolt(),setSpout()
task数目,代码中配置,setNumTasks()如果不配置,默认取executor数目。
2.2 动态改变并发度
可变的是worker和executor的数目,可通过命令或者webUI
其中命令的为:
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
以上就是关于storm一些基本概念,以及概念之间的联系。
因为今天提交了两个Topology,出现了一些错误,于是重新回顾这个关系:
再次总结:
每个worker只会处理一种Topology里的component。
可能是多个worker一起处理一个Topology。
executor是线程,处理具体的component。
task是具体component的实例,可以不指定,不设定的时候,num就是executor的数量。
storm基础系列之一----storm并发度概念剖析的更多相关文章
- Storm概念学习系列之storm的可靠性
这个概念,对于理解storm很有必要. 1.worker进程死掉 worker是真实存在的.可以jps查看. 正是因为有了storm的可靠性,所以storm会重新启动一个新的worker进程. 2.s ...
- Storm概念学习系列之storm的设计思想
不多说,直接上干货! storm的设计思想 在 Storm 中也有对流(Stream)的抽象,流是一个不间断的.无界的连续 Tuple(Storm在建模事件流时,把流中的事件抽象为 Tuple 即元组 ...
- Storm概念学习系列之storm的雪崩
不多说,直接上干货! Storm的雪崩问题的解决办法1: Storm概念学习系列之并行度与如何提高storm的并行度 Storm的雪崩问题的解决办法2:
- Storm概念学习系列之storm的定时任务
不多说,直接上干货! 至于为什么,有storm的定时任务.这个很简单.但是,这个在工作中非常重要! 假设有如下的业务场景 这个spoult源源不断地发送数据,boilt呢会进行处理.然后呢,处理后的结 ...
- Storm概念学习系列之storm流程图
把stream当做一列火车, tuple当做车厢,spout当做始发站,bolt当做是中间站点!!! 见 Storm概念学习系列之Spout数据源 Storm概念学习系列之Topology拓扑 Sto ...
- Storm概念学习系列之storm核心组件
不多说,直接上干货! Storm核心组件 了解 Storm 的核心组件对于理解 Storm 原理非常重要,下面介绍 Storm 的整体,然后介绍 Storm 的核心. Storm 集群由一个主节点和多 ...
- Storm概念学习系列之storm简介
不多说,直接上干货! storm简介 Storm 是 Twitter 开源的.分布式的.容错的实时计算系统,遵循 Eclipse Public License1.0. Storm 通过简单的 API ...
- storm基础系列之二----zookeeper的作用
在storm集群中,我们常常使用zookeeper作为协调者.那么具体发挥的是什么作用呢? 概括来说,zookeeper是nimbus和supervisor进行交互的中介.具体来说有二: 1.nimb ...
- storm基础系列之五---------接入数据收集系统flume
1.基本结构介绍 flume是三层架构,agent,collector,storage.每一层都可水平扩展. 其中,agent就是数据采集方:collector是数据整合方:storage是各种数据落 ...
随机推荐
- 如何用js定义数组,用js来拼接json字段
定义js数组的方式有: var arr = (); var arr = []; var arr = new Array(); 如何拼接成一个json字段. <!DOCTYPE HTML PUBL ...
- RabbitMQ在window的搭建
RabbitMq window 搭建设置过程,网上有些说的不太明白,所以亲自操刀测试过程,参考了很多人的资料,多谢各位大神的宝贵资料第一步:装RabbitMq运行环境,类似一个虚拟机的东东 1.otp ...
- hibernate中获得session的方式
his.getsession实际上是调用了父类中的方法获得session.使用spring管理hibernate的SessionFactory的时候,这个方法会从session池中拿出一session ...
- tinyhttpd源码分析
我们经常使用网页,作为开发人员我们也部署过httpd服务器,比如开源的apache,也开发过httpd后台服务,比如fastcgi程序,不过对于httpd服务器内部的运行机制,却不是非常了解,前几天看 ...
- Ported my old SPH solver in Unity
Here is the link to the web player version, http://www-scf.usc.edu/~taian/pages/sph/builds/12212014/ ...
- ie8的兼容
1.IE8以下不支持getElementsByClassName方法//解决IE8之类不支持getElementsByClassNameif (!document.getElementsByClass ...
- AFNetworking 3.0
AFN 一.什么是AFN 全称是AFNetworking,是对NSURLConnection的一层封装 虽然运行效率没有ASI高,但是使用比ASI简单 在iOS开发中,使用比较广泛 AFN的githu ...
- 最小生成树——kruskal算法
kruskal和prim都是解决最小生成树问题,都是选取最小边,但kruskal是通过对所有边按从小到大的顺序排过一次序之后,配合并查集实现的.我们取出一条边,判断如果它的始点和终点属于同一棵树,那么 ...
- HTML5,jQuery,ajax基础面试
简要描述HTML5中的本地存储 答案: 很多时候我们会存储用户本地信息到电脑上,例如:比方说用户有一个填充了一半的长表格,然后突然网络连接断开了,这样用户希望你能存储这些信息到本地,当网络回复的时候, ...
- c语言数据结构之 堆排序
算法:先生成随机数,赋值到数组,将数组第一个元素a[0]设置为哨兵,函数调用数组和随机数个数n,再设定n/2的根结点与孩子结点进行比较操作,若右孩子存在,则选出三个数里最小的数赋值给根节点,如果右孩子 ...