神经网络模型之AlexNet的一些总结
说明: 这个属于个人的一些理解,有错误的地方,还希望给予教育哈~
此处以caffe官方提供的AlexNet为例.
目录:
1.背景
2.框架介绍
3.步骤详细说明
5.参考文献
背景:
AlexNet是在2012年被发表的一个金典之作,并在当年取得了ImageNet最好成绩,也是在那年之后,更多的更深的神经网路被提出,比如优秀的vgg,GoogleLeNet.
其官方提供的数据模型,准确率达到57.1%,top 1-5 达到80.2%. 这项对于传统的机器学习分类算法而言,已经相当的出色。
框架介绍:
AlexNet的结构模型如下:
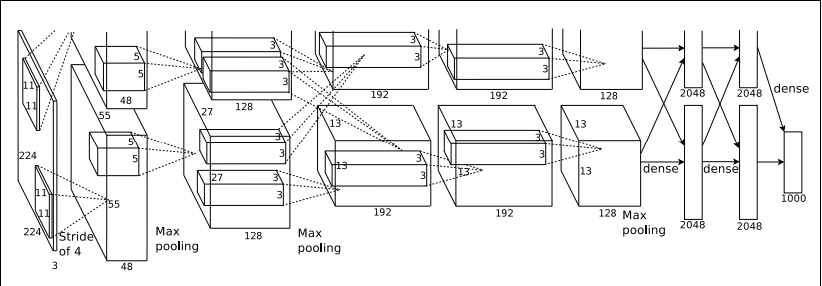
如上图所示,上图采用是两台GPU服务器,所有会看到两个流程图,我们这里以一台CPU服务器为例做描述.该模型一共分为八层,5个卷基层,,以及3个全连接层,在每一个卷积层中包含了激励函数RELU以及局部响应归一化(LRN)处理,然后在经过降采样(pool处理),下面我们来逐一的对每一层进行分析下吧.
3. 详细介绍:
1. 对于conv1层,如下
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
kernel_size:
stride:
}
}
该过程,
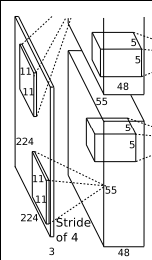
1.输入Input的图像规格: 224*224*3(RGB图像),实际上会经过预处理变为227*227*3
2.使用的96个大小规格为11*11的过滤器filter,或者称为卷积核,进行特征提取,(ps:图上之所以看起来是48个是由于采用了2个GPU服务器处理,每一个服务器上承担了48个).
需要特别提一下的是,原始图片为RBG图像,也就是三个通道的,我们这96个过滤器也是三通道的,也就是我们使用的实际大小规格为11*11*3,也就是原始图像是彩色的,我们提取到的特征也是彩色的,在卷积的时候,我们会依据这个公式来提取特征图: 【img_size - filter_size】/stride +1 = new_feture_size,所以这里我们得到的特征图大小为:
([227-11] / 4 + 1 )= 55 注意【】表示向下取整. 我们得到的新的特征图规格为55*55,注意这里提取到的特征图是彩色的.这样得到了96个55*55大小的特征图了,并且是RGB通道的.
需要特别说明的一点是,我们在使用过滤器filter和数据进行卷积时(ps: 卷积就是[1,2,3]*[1,1,1] = 1*1+2*1+3*1=6,也就是对应相乘并求和),而且我们使用的卷积核尺寸是11*11,也就是采用的是局部链接,每次连接11*11大小区域,然后得到一个新的特征,再次基础上再卷积,再得到新的特征,也就是将传统上采用的全链接的浅层次神经网络,通过加深神经网路层次也就是增加隐藏层,然后下一个隐藏层中的某一个神经元是由上一个网络层中的多个神经元乘以权重加上偏置之后得到的,也就是所偶为的权值共享,通过这来逐步扩大局部视野,(形状像金字塔),最后达到全链接的效果. 这样做的好处是节约内存,一般而言,节约空间的同时,消耗时间就会相应的增加,但是近几年的计算机计算速度的提升,如GPU.已经很好的解决了这个时间的限制的问题.
3. 使用RELU激励函数,来确保特征图的值范围在合理范围之内,比如{0,1},{0,255}
最后还有一个LRN处理,但是由于我一直都是没用这玩意,所以,哈哈哈哈哈哈,没有深切的体会,就没有发言权.
4. 降采样处理(pool层也称为池化),如下图:

layer {
name: "pool1"
type: "Pooling"
bottom: "norm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
5. 使用LRN,中文翻译为局部区域归一化,对降采样的特征图数据进行如果,其中LRN又存在两种模式:
5.1 源码默认的是ACROSS_CHANNELS ,跨通道归一化(这里我称之为弱化),local_size:5(默认值),表示局部弱化在相邻五个特征图间中求和并且每一个值除去这个和.
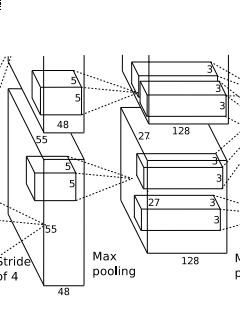
官方给的是内核是3*3大小,该过程就是3*3区域的数据进行处理(求均值,最大/小值,就是区域求均值,区域求最大值,区域求最小值),通过降采样处理,我们可以得到
( [55-3] / 2 + 1 ) = 27 ,也就是得到96个27*27的特征图,然后再以这些特征图,为输入数据,进行第二次卷积.
conv2层,如下图:
对应的caffe:
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
group:
}
}
conv2和conv1不同,conv2中使用256个5*5大小的过滤器filter对96*27*27个特征图,进行进一步提取特征,但是处理的方式和conv1不同,过滤器是对96个特征图中的某几个特征图中相应的区域乘以相应的权重,然后加上偏置之后所得到区域进行卷积,比如过滤器中的一个点X11 ,如X11*new_X11,需要和96个特征图中的1,2,7特征图中的X11,new_X11 =1_X_11*1_W_11+2_X_11*2_W_11+7_X_11*7_W_11+Bias,经过这样卷积之后,然后在在加上宽度高度两边都填充2像素,会的到一个新的256个特征图.特征图的大小为:
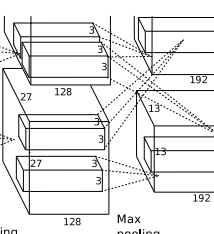
(【27+2*2 - 5】/1 +1) = 27 ,也就是会有256个27*27大小的特征图.
然后进行ReLU操作.
再进行降采样【pool】处理,如下图,得到
layer {
name: "pool2"
type: "Pooling"
bottom: "norm2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
得到: 【27-3】/2 +1 = 13 也就是得到256个13*13大小的特征图.
conv3层,如下图:
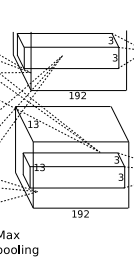
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
}
}
得到【13+2*1 -3】/1 +1 = 13 , 384个13*13的新特征图.
conv3没有使用降采样层.
conv4层:
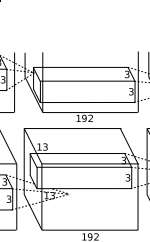
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
group:
}
}
依旧
得到【13+2*1 -3】/1 +1 = 13 , 384个13*13的新特征图.
conv4没有使用降采样层.
conv5层,如下图:
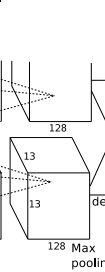
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
group:
}
}
得到256个13*13个特征图.
降采样层pool,防止过拟合:
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
得到: 256个 (【13 - 3】/2 +1)=6 6*6大小的特征图.
fc6全链接图:
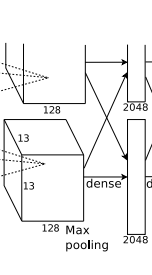
描述一下: 这里使用4096个神经元,对256个大小为6*6特征图,进行一个全链接,也就是将6*6大小的特征图,进行卷积变为一个特征点,然后对于4096个神经元中的一个点,是由256个特征图中某些个特征图卷积之后得到的特征点乘以相应的权重之后,再加上一个偏置得到.
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
再进行一个dropout随机从4096个节点中丢掉一些节点信息(也就是值清0),然后就得到新的4096个神经元.
fc7全连接层:
和fc6类似.
fc8链接层:
采用的是1000个神经元,然后对fc7中4096个神经元进行全链接,然后会通过高斯过滤器,得到1000个float型的值,也就是我们所看到的预测的可能性,
如果是训练模型的话,会通过标签label进行对比误差,然后求解出残差,再通过链式求导法则,将残差通过求解偏导数逐步向上传递,并将权重进行推倒更改,类似与BP网络思虑,然后会逐层逐层的调整权重以及偏置.
5.参考文献:
ImageNet https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
BP神经网络 https://www.zhihu.com/question/27239198
还有一些当时学习的时候看过,不过时隔久远,已经忘了地址了.
神经网络模型之AlexNet的一些总结的更多相关文章
- zz神经网络模型量化方法简介
神经网络模型量化方法简介 https://chenrudan.github.io/blog/2018/10/02/networkquantization.html 2018-10-02 本文主要梳理了 ...
- 使用PyTorch简单实现卷积神经网络模型
这里我们会用 Python 实现三个简单的卷积神经网络模型:LeNet .AlexNet .VGGNet,首先我们需要了解三大基础数据集:MNIST 数据集.Cifar 数据集和 ImageNet 数 ...
- BP神经网络模型与学习算法
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- 建模算法(六)——神经网络模型
(一)神经网络简介 主要是利用计算机的计算能力,对大量的样本进行拟合,最终得到一个我们想要的结果,结果通过0-1编码,这样就OK啦 (二)人工神经网络模型 一.基本单元的三个基本要素 1.一组连接(输 ...
- BP神经网络模型及算法推导
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- 基于pytorch的CNN、LSTM神经网络模型调参小结
(Demo) 这是最近两个月来的一个小总结,实现的demo已经上传github,里面包含了CNN.LSTM.BiLSTM.GRU以及CNN与LSTM.BiLSTM的结合还有多层多通道CNN.LSTM. ...
- 手写数字识别 ----卷积神经网络模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----卷积神经网络模型 import os import tensorflow as tf #部分注释来源于 # http://www.cnblogs.com/rgvb178/p/ ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- 机器学习入门-BP神经网络模型及梯度下降法-2017年9月5日14:58:16
BP(Back Propagation)网络是1985年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一. B ...
随机推荐
- 通过队列解决Lucene文件并发创建索引
public sealed class SearchIndexManager { private static readonly SearchIndexManager searchIndexManag ...
- empty isset
1.当变量未定义时,is_null()和"参数本身"是不允许作为参数判断的,会报Notice警告错误: 2.empty,isset首先都会检查变量是否存在,然后对变量值进行检测.而 ...
- 用Excel创建SQL server性能报告
转载自Kun Lee "Creating SQL Server performance based reports using Excel" 性能测试调优中对数据库的监控十分重要, ...
- centos7下搭建nginx+php7.1+mariadb+memcached+redis
一.环境准备 1.首先介绍一下环境,以及我们今天的主角们 我用的环境是最小化安装的centos7,mariadb(江湖传言mysql被oracle收购后,人们担心像java一样毁在oracle手上于是 ...
- Struts 笔记 内部资料 请勿转载 谢谢合作
Struts 概述 随着MVC 模式的广泛使用,催生了MVC 框架的产生.在所有的MVC 框架中,出现最早,应用最广的就是Struts 框架. Struts 的起源 Struts 是Apache 软件 ...
- Javascript > Eclipse > Code completion (Content Assist)
分享一下,整体理清的思路,关于Eclipse中代码的 自动完成,可配置自定义Library文件地址 其实这个思路的通用的,不管任何Eclipse支持的编辑语言,都可以适用.下面已Javascript来 ...
- 设置bundle包中的默认语言
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 11.0px Menlo; color: #d28f5a } span.s1 { } span.s2 { c ...
- 后缀数组:倍增法和DC3的简单理解
一些定义:设字符串S的长度为n,S[0~n-1]. 子串:设0<=i<=j<=n-1,那么由S的第i到第j个字符组成的串为它的子串S[i,j]. 后缀:设0<=i<=n- ...
- JS对象深刻理解 - 1
JavaScript创建对象 JavaScript 有Date.Array.String等这样的内置对象,功能强大使用简单,人见人爱,但在处理一些复杂的逻辑的时候,内置对象就很无力了,往往需要开发 ...
- web前端性能优化指南(转)
web前端性能优化指南 概述 1. PC优化手段在Mobile侧同样适用2. 在Mobile侧我们提出三秒种渲染完成首屏指标3. 基于第二点,首屏加载3秒完成或使用Loading4. 基于联通3G网络 ...