袋鼠云数栈基于CBO在Spark SQL优化上的探索
原文链接:袋鼠云数栈基于CBO在Spark SQL优化上的探索
一、Spark SQL CBO选型背景
Spark SQL的优化器有两种优化方式:一种是基于规则的优化方式(Rule-Based Optimizer,简称为RBO);另一种是基于代价的优化方式(Cost-Based Optimizer,简称为CBO)。
1、RBO是传统的SQL优化技术
RBO是发展比较早且比较成熟的一项SQL优化技术,它按照制定好的一系列优化规则对SQL语法表达式进行转换,最终生成一个最优的执行计划。RBO属于一种经验式的优化方法,严格按照既定的规则顺序进行匹配,所以不同的SQL写法直接决定执行效率不同。且RBO对数据不敏感,在表大小固定的情况下,无论中间结果数据怎么变化,只要SQL保持不变,生成的执行计划就都是固定的。
2、CBO是RBO改进演化的优化方式
CBO是对RBO改进演化的优化方式,它能根据优化规则对关系表达式进行转换,生成多个执行计划,在根据统计信息(Statistics)和代价模型(Cost Model)计算得出代价最小的物理执行计划。
3、 CBO与RBO优势对比
● RBO优化例子
下面我们来看一个例子:计算t1表(大小为:2G)和t2表(大小为:1.8G)join后的行数
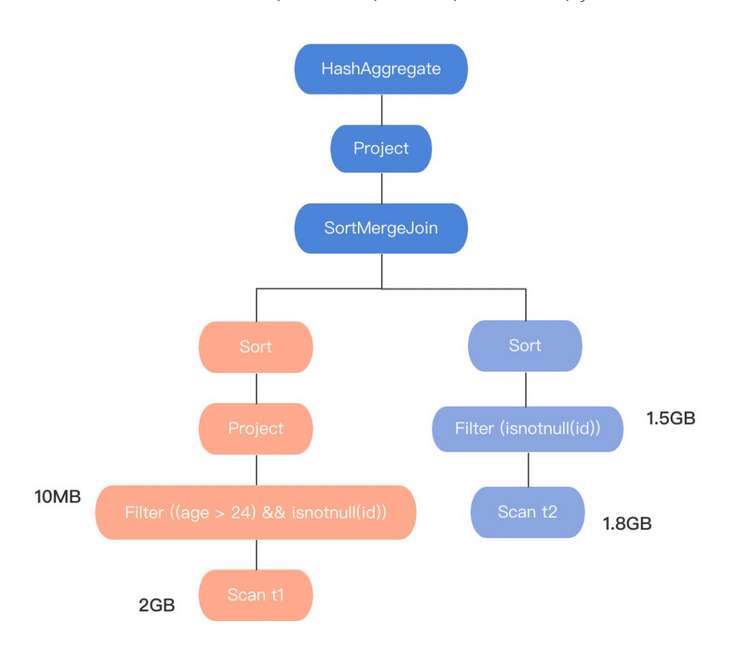
上图是:
SELECT COUNT(t1.id) FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.age > 24
基于RBO优化后生成的物理执行计划图。在图中我们可以看出,执行计划最后是选用SortMergeJoin ⑴ 进行两个表join的。
在Spark中,join的实现有三种:
1.Broadcast Join
2.ShuffleHash Join
3.SortMerge Join
ShuffleHash Join和SortMerge Join都需要shuffle,相对Broadcast Join来说代价要大很多,如果选用Broadcast Join则需要满足有一张表的大小是小于等于
spark.sql.autoBroadcastJoinThreshold 的大小(默认为10M)。
而我们再看,上图的执行计划t1表,原表大小2G过滤后10M,t2表原表大小1.8G过滤后1.5G。这说明RBO优化器不关心中间数据的变化,仅根据原表大小进行join的选择了SortMergeJoin作为最终的join,显然这得到的执行计划不是最优的。
● CBO优化例子
而使用CBO优化器得到的执行计划图如下:
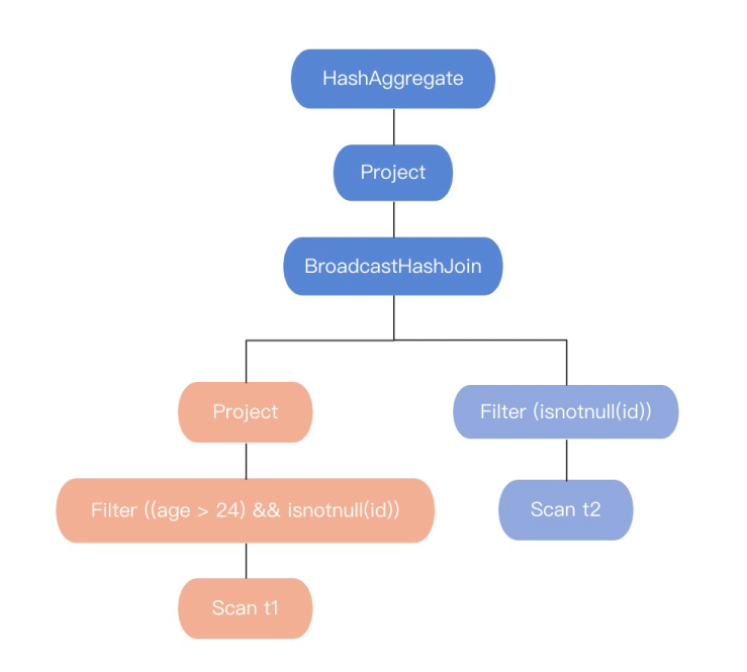
我们不难看出,CBO优化器充分考虑到中间结果,感知到中间结果的变化满足能Broadcast Join的条件,所以生成的最终执行计划会选择Broadcast Join来进行两个表join。
● 其他优势
其实除了刻板的执行导致不能得到最优解的问题,RBO还有学习成本高的问题:开发人员需要熟悉大部分优化规则,否则写出来的SQL性能可能会很差。
● CBO是数栈Spark SQL 优化的更佳选择
相对于RBO,CBO无疑是更好的选择,它使Spark SQL的性能提升上了一个新台阶,Spark作为数栈平台底层非常重要的组件之一,承载着离线开发平台上大部分任务,做好Spark的优化也将推动着数栈在使用上更加高效易用。所以数栈选择CBO做研究探索,由此进一步提高数栈产品性能。
二、Spark SQL CBO实现原理
Spark SQL中实现CBO的步骤分为两大部分,第一部分是统计信息收集,第二部分是成本估算:
1、统计信息收集
统计信息收集分为两个部分:第一部分是原始表信息统计、第二部分是中间算子的信息统计。
1)原始表信息统计
Spark中,通过增加新的SQL语法ANALYZE TABLE来用于统计原始表信息。原始表统计信息分为表级别和列级别两大类,具体的执行如下所示:
● 表级别统计信息
通过执行 ANALYZE TABLE table_name COMPUTE STATISTICS 语句来收集,统计指标包括estimatedSize解压后数据的大小、rowCount数据总条数等。
● 列级别统计信息
通过执行 ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS column-name1, column-name2, …. 语句来收集。
列级别的信息又分为基本列信息和直方图,基本列信息包括列类型、Max、Min、number of nulls, number of distinct values, max column length, average column length等,直方图描述了数据的分布。Spark默认没有开启直方图统计,需要额外设置参数:spark.sql.statistics.histogram.enabled = true。
原始表的信息统计相对简单,推算中间节点的统计信息相对就复杂一些,并且不同的算子会有不同的推算规则,在Spark中算子有很多,有兴趣的同学可以看Spark SQL CBO设计文档:
https://issues.apache.org/jira/secure/attachment/12823839/Spark_CBO_Design_Spec.pdf
2)中间算子的信息统计
我们这里以常见的filter算子为例,看看推算算子统计信息的过程。基于上一节的SQL SELECT COUNT(t1.id) FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.age > 24生成的语法树来看下t1表中包含大于运算符 filter节点的统计信息。
图片
在这里需要分三种情况考虑:
第一种
过滤条件常数值大于max(t1.age),返回结果为0;
第二种
过滤条件常数值小于min(t1.age),则全部返回;
第三种
过滤条件常数介于min(t1.age)和max(t1.age)之间,当没有开启直方图时过滤后统计信息的公式为after_filter = (max(t1.age) - 过滤条件常数24)/(max(t1.age) – min(t1.age)) * before_filter,没有开启直方图则默认任务数据分布是均匀的;当开启直方图时过滤后统计信息公式为after_filter = height(>24) / height(All) * before_filter。然后将该节点min(t1.age)等于过滤条件常数24。
2、成本估算
介绍完如何统计原始表的统计信息和如何计算中间算子的统计信息,有了这些信息后就可以计算每个节点的代价成本了。
在介绍如何计算节点成本之前我们先介绍一些成本参数的含义,如下:
Hr: 从 HDFS 读取 1 个字节的成本
Hw: 从 HDFS 写1 个字节的成本
NEt: 在 Spark 集群中通过网络从任何节点传输 1 个字节到 目标节点的平均成本
Tr: 数据总条数
Tsz: 数据平均大小
CPUc: CPU 成本
计算节点成本会从IO和CPU两个维度考虑,每个算子成本的计算规则不一样,我们通过join算子来举例说明如何计算算子的成本:
假设join是Broadcast Join,大表分布在n个节点上,那么CPU代价和IO代价计算公式分别如下:
CPU Cost=小表构建Hash Table的成本 + 大表探测的成本 = Tr(Rsmall) * CPUc + (Tr(R1) + Tr(R2) + … + Tr(Rn)) * n * CPUc
IO Cost =读取小表的成本 + 小表广播的成本 + 读取大表的成本 = Tr(Rsmall) * Tsz(Rsmall) * Hr + n * Tr(Rsmall) * Tsz(Rsmall) * NEt + (Tr(R1)* Tsz(R1) + … + Tr(Rn) * Tsz(Rn)) * Hr
但是无论哪种算子,成本计算都和参与的数据总条数、数据平均大小等因素直接相关,这也是为什么在这之前要先介绍如何统计原表信息和推算中间算子的统计信息。
每个算子根据定义的规则计算出成本,每个算子成本相加便是整个执行计划的总成本,在这里我们可以考虑一个问题,最优执行计划是列举每个执行计划一个个算出每个的总成本得出来的吗?显然不是的,如果每个执行计划都计算一次总代价,那估计黄花菜都要凉了,Spark巧妙的使用了动态规划的思想,快速得出了最优的执行计划。
三、数栈在Spark SQL CBO上的探索
了解完Spark SQL CBO的实现原理之后,我们来思考一下第一个问题:大数据平台想要实现支持Spark SQL CBO优化的话,需要做些什么?
在前文实现原理中我们提到,Spark SQL CBO的实现分为两步,第一步是统计信息收集,第二步是成本估算。而统计信息收集又分为两步:第一步的原始表信息统计、第二步中间算子的信息统计。到这里我们找到了第一个问题的答案:平台中需要先有原始表信息统计的功能。
第一个问题解决后,我们需要思考第二个问题:什么时候进行表信息统计比较合适?针对这个问题,我们初步设想了三种解决信息统计的方案:
● 在每次SQL查询前,先进行一次表信息统计
这种方式得到的统计信息比较准确,经过CBO优化后得出的执行计划也是最优的,但是信息统计的代价最大。
● 定期刷新表统计信息
每次SQL查询前不需要进行表信息统计,因为业务数据更新的不确定性,所以这种方式进行SQL查询时得到的表统计信息可能不是最新的,那么CBO优化后得到的执行计划有可能不是最优的。
● 在变更数据的业务方执行信息统计
这种方式对于信息统计的代价是最小的,也能保证CBO优化得到的执行计划是最优的,但是对于业务代码的侵入性是最大的。
不难看出三种方案各有利弊,所以进行表信息统计的具体方案取决于平台本身的架构设计。
基于数栈平台建设数仓的结构图如下图所示:
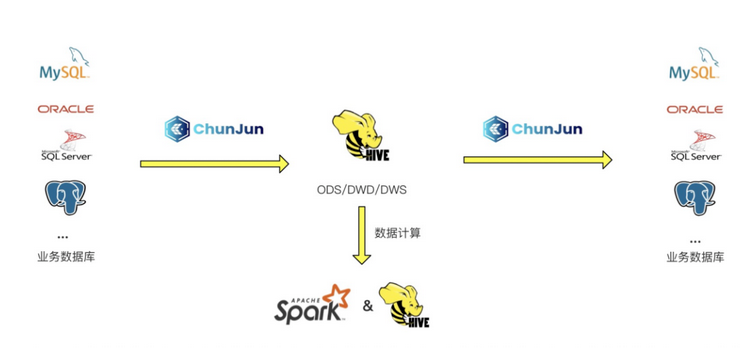
首先通过ChunJun将业务数据库数据采集到Hive ODS层
然后通过Hive或者Spark进行数据处理
最后通过ChunJun将Hive库的数据写入到业务数据库用于业务处理
从结构图可看出数栈有用到Hive、Spark和ChunJun三个组件,并且这三个组件都会读写Hive, 数栈多个子产品(如离线平台和实时平台)也都有可能对Hive进行读写,所以如果基于方案3来做成本是非常高的。
方案1本身代价就已经较大,每次查询前都进行一次信息统计,信息统计的时间是要算在本次查询耗时中的,如果表数据量比较大增加的时间可能是十几分钟甚至更久。
综合考虑,我们选用了更灵活合理的方案2来进行表信息统计。虽然Spark SQL运行时得到的统计信息可能不是最新的,但是总体相比较RBO来说还是有很大的性能提升。
接下来就为大家分享,数栈是如何如何统计收集原表信息统计:
我们在离线平台项目管理页面上添加了表信息统计功能,保证了每个项目可以根据项目本身情况配置不同的触发策略。触发策略可配置按天或者按小时触发,按天触发支持配置到从当天的某一时刻触发,从而避开业务高峰期。配置完毕后,到了触发的时刻离线平台就会自动以项目为单位提交一个Spark任务来统计项目表信息。
在数栈没有实现CBO支持之前,Spark SQL的优化只能通过调整Spark本身的参数实现。这种调优方式很高的准入门槛,需要使用者比较熟悉Spark的原理。数栈CBO的引入大大降低了使用者的学习门槛,用户只需要在Spark Conf中开启
CBO-spark.sql.cbo.enabled=true
然后在对应项目中配置好表信息统计就可以做到SQL优化了。
四、未来展望
在CBO优化方面持续投入研究后,Spark SQL CBO整体相比较RBO而言已经有了很大的性能提升。但这并不说明整个操作系统就没有优化的空间了,已经拿到的进步只会鼓舞我们继续进行更深层次的探索,努力往前再迈一步。
完成对CBO的初步支持探索后,数栈把目光看向了Spark 3.0 版本引入的新特性——AQE(Adaptive Query Execution)。
AQE是动态CBO的优化方式,是在CBO基础上对SQL优化技术又一次的性能提升。如前文所说,CBO目前的计算对前置的原始表信息统计是仍有依赖的,而且信息统计过时的情况会给CBO带来不小的影响。
如果在运行时动态的优化 SQL 执行计划,就不再需要像CBO那样需要提前做表信息统计。数栈正在针对这一个新特性进行,相信不久的将来我们就能引入AQE,让数栈在易用性高性能方面更上一层楼。希望小伙伴们保持关注,数栈愿和大家一起成长。
原文来源:VX公众号“数栈研习社”
袋鼠云开源框架钉钉技术交流群(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
袋鼠云数栈基于CBO在Spark SQL优化上的探索的更多相关文章
- 1. 元信息:Meta类 2. 基于对象查询的sql优化 3. 自定义:Group_Concat() 4. ajax前后台交互
一.元信息 ''' 1. 元信息 1. Model类可以通过元信息类设置索引和排序信息 2. 元信息是在Model类中定义一个Meta子类 class Meta: # 自定义表名 db_table = ...
- Python小白的数学建模课-A1.2021年数维杯C题(运动会优化比赛模式探索)探讨
Python小白的数学建模课 A1-2021年数维杯C题(运动会优化比赛模式探索)探讨. 运动会优化比赛模式问题,是公平分配问题 『Python小白的数学建模课 @ Youcans』带你从数模小白成为 ...
- 云时代架构阅读笔记十一——数据库SQL优化
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 ...
- spark sql优化
1.内存优化 1.1.RDD RDD默认cache仅使用内存 可以看到使用默认cache时,四个分区只在内存中缓存了3个分区,4.4G的数据 使用kryo序列化+MEMORY_ONLY_SER 可以看 ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- spark sql 优化心得
本篇文章主要记录最近在使用spark sql 时遇到的问题已经使用心得. 1 spark 2.0.1 中,启动thriftserver 或者是spark-sql时,如果希望spark-sql run ...
- 基于mysql数据库 关于sql优化的一些问题
mysql数据库有一个explain关键词,可以对select语句进行分析并且输出详细的select执行过程的详细信息. 对sql explain后输出几个字段: id:SELECT查询的标识符,每个 ...
- 袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 袋鼠云出品!数栈UI 5.0全新体验升级,设计背后的故事
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 前言 数栈作为云原⽣⼀站式⼤数据开发平台,从2016年发布第⼀个版本 ...
随机推荐
- Microsoft.NETCore.App 版本不一致导致的运行失败
场景重现 今天新建了一个 ASP.NET Core 的项目, 通过 Web Deploy 顺利发布到IIS上后, 但访问时出现如下异常: 异常原因 通过手动执行dotnet命令发现运行框架版本不一致? ...
- leetcode每日一题:k-avoiding 数组的最小总和
引言 今天是本次开始坚持leetcode每日1题的第10天,也算是迈出了一小步. 题目 2829. k-avoiding 数组的最小总和 给你两个整数 n 和 k . 对于一个由 不同 正整数组成 ...
- GitLab 服务器宕机时的项目代码恢复方法
重要前提:GitLab 数据挂载盘必须能够正常读取,且 /var/opt/gitlab/git-data/repositories 目录下的数据可以完整拷贝. 当 GitLab 服务器意外宕机且没有备 ...
- 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明 @ 目录 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明 1. Exchanges 交换机的 ...
- HTB打靶记录-Vintage
信息收集 nmap -sV -sC -O 10.10.11.45 Nmap scan report for 10.10.11.45 Host is up (2.1s latency). Not sho ...
- 字符串匹配究极大招【KMP】:带你一步步从原理到构建
目录 前言 KMP原理 什么是前缀表 如何构建前缀表 next数组 使用next数组做匹配 实战演练 前言 一文带你了解如何去理解并实现KMP算法.本文用于记录自己的学习过程,同时向大家进行分享相关的 ...
- 康谋方案 | 基于AI自适应迭代的边缘场景探索方案
构建巨量的驾驶场景时,测试ADAS和AD系统面临着巨大挑战,如传统的实验设计(Design of Experiments, DoE)方法难以有效覆盖识别驾驶边缘场景案例,但这些边缘案例恰恰是进一步提升 ...
- 【李宏毅机器学习笔记】生成式对抗网络GAN
[ 李宏毅机器学习]生成式对抗网络GAN 在传统的神经网络任务中,我们通常把一个网络当作一个函数f(x),给定输入x,网络就会输出一个对应的结果 y.比如图像分类任务中,输入是一张图片,输出是一个分类 ...
- symfony5初体验:doctrine、配置、文件上传、jwt登录/auth等常见问题
之前用symfony3.4,最近上手symfony5发现加入了很多新特性,搭配easyadminBundle.api-platform这些用起来感觉简直如有神助,瞬间爱了. 不过api-platfor ...
- 查阅相关资料, 了解什么是scrum中的3355?
在Scrum中,3355是一个用于描述其核心组成部分的模型,具体包括三个核心角色.三个工件.五个关键事件和五个价值观.下面是对Scrum中3355的详细解释: 三个核心角色 产品负责人(Product ...