Spark:用Scala和Java实现WordCount
http://www.cnblogs.com/byrhuangqiang/p/4017725.html
为了在IDEA中编写scala,今天安装配置学习了IDEA集成开发环境。IDEA确实很优秀,学会之后,用起来很顺手。关于如何搭建scala和IDEA开发环境,请看文末的参考资料。
用Scala和Java实现WordCount,其中Java实现的JavaWordCount是spark自带的例子($SPARK_HOME/examples/src/main/java/org/apache/spark/examples/JavaWordCount.java)
1.环境
- OS:Red Hat Enterprise Linux Server release 6.4 (Santiago)
- Hadoop:Hadoop 2.4.1
- JDK:1.7.0_60
- Spark:1.1.0
- Scala:2.11.2
- 集成开发环境:IntelliJ IDEA 13.1.3
注意:需要在客户端windows环境下安装IDEA、Scala、JDK,并且为IDEA下载scala插件。
2.Scala实现单词计数

1 package com.hq
2
3 /**
4 * User: hadoop
5 * Date: 2014/10/10 0010
6 * Time: 18:59
7 */
8 import org.apache.spark.SparkConf
9 import org.apache.spark.SparkContext
10 import org.apache.spark.SparkContext._
11
12 /**
13 * 统计字符出现次数
14 */
15 object WordCount {
16 def main(args: Array[String]) {
17 if (args.length < 1) {
18 System.err.println("Usage: <file>")
19 System.exit(1)
20 }
21
22 val conf = new SparkConf()
23 val sc = new SparkContext(conf)
24 val line = sc.textFile(args(0))
25
26 line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)
27
28 sc.stop()
29 }
30 }
3.Java实现单词计数
1 package com.hq;
2
3 /**
4 * User: hadoop
5 * Date: 2014/10/10 0010
6 * Time: 19:26
7 */
8
9 import org.apache.spark.SparkConf;
10 import org.apache.spark.api.java.JavaPairRDD;
11 import org.apache.spark.api.java.JavaRDD;
12 import org.apache.spark.api.java.JavaSparkContext;
13 import org.apache.spark.api.java.function.FlatMapFunction;
14 import org.apache.spark.api.java.function.Function2;
15 import org.apache.spark.api.java.function.PairFunction;
16 import scala.Tuple2;
17
18 import java.util.Arrays;
19 import java.util.List;
20 import java.util.regex.Pattern;
21
22 public final class JavaWordCount {
23 private static final Pattern SPACE = Pattern.compile(" ");
24
25 public static void main(String[] args) throws Exception {
26
27 if (args.length < 1) {
28 System.err.println("Usage: JavaWordCount <file>");
29 System.exit(1);
30 }
31
32 SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
33 JavaSparkContext ctx = new JavaSparkContext(sparkConf);
34 JavaRDD<String> lines = ctx.textFile(args[0], 1);
35
36 JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
37 @Override
38 public Iterable<String> call(String s) {
39 return Arrays.asList(SPACE.split(s));
40 }
41 });
42
43 JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
44 @Override
45 public Tuple2<String, Integer> call(String s) {
46 return new Tuple2<String, Integer>(s, 1);
47 }
48 });
49
50 JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
51 @Override
52 public Integer call(Integer i1, Integer i2) {
53 return i1 + i2;
54 }
55 });
56
57 List<Tuple2<String, Integer>> output = counts.collect();
58 for (Tuple2<?, ?> tuple : output) {
59 System.out.println(tuple._1() + ": " + tuple._2());
60 }
61 ctx.stop();
62 }
63 }
4.IDEA打包和运行
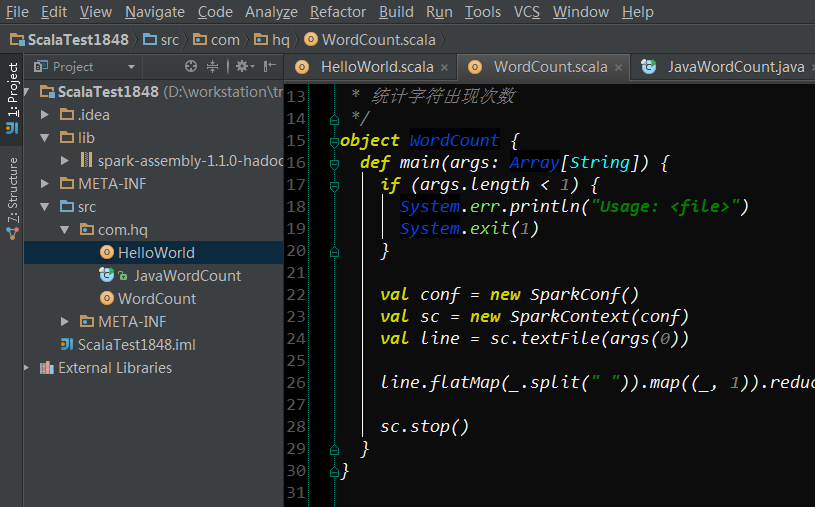
4.1 IDEA的工程结构
在IDEA中建立Scala工程,并导入spark api编程jar包(spark-assembly-1.1.0-hadoop2.4.0.jar:$SPARK_HOME/lib/里面)
4.2 打成jar包
File ---> Project Structure
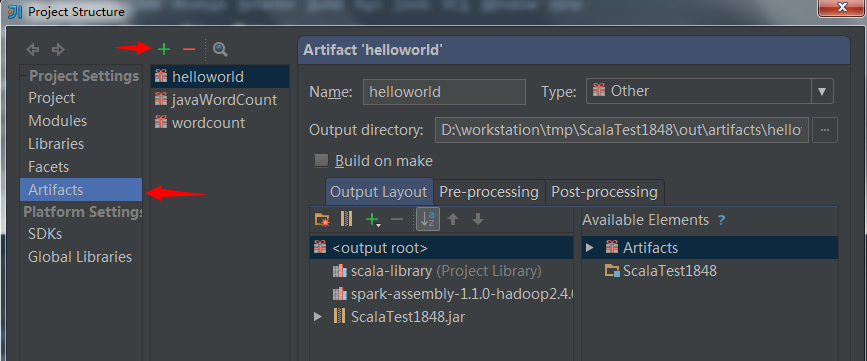
配置完成后,在菜单栏中选择Build->Build Artifacts...,然后使用Build等命令打包。打包完成后会在状态栏中显示“Compilation completed successfully...”的信息,去jar包输出路径下查看jar包,如下所示。

ScalaTest1848.jar就是我们编程所产生的jar包,里面包含了三个类HelloWord、WordCount、JavaWordCount。
可以用这个jar包在spark集群里面运行java或者scala的单词计数程序。
4.3 以Spark集群standalone方式运行单词计数
上传jar包到服务器,并放置在/home/ebupt/test/WordCount.jar路径下。
上传一个text文本文件到HDFS作为单词计数的输入文件:hdfs://eb170:8020/user/ebupt/text
内容如下
1 import org apache spark api java JavaPairRDD
2 import org apache spark api java JavaRDD
3 import org apache spark api java JavaSparkContext
4 import org apache spark api java function FlatMapFunction
5 import org apache spark api java function Function
6 import org apache spark api java function Function2
7 import org apache spark api java function PairFunction
8 import scala Tuple2
用spark-submit命令提交任务运行,具体使用查看:spark-submit --help
1 [ebupt@eb174 bin]$ spark-submit --help
2 Spark assembly has been built with Hive, including Datanucleus jars on classpath
3 Usage: spark-submit [options] <app jar | python file> [app options]
4 Options:
5 --master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
6 --deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
7 on one of the worker machines inside the cluster ("cluster")
8 (Default: client).
9 --class CLASS_NAME Your application's main class (for Java / Scala apps).
10 --name NAME A name of your application.
11 --jars JARS Comma-separated list of local jars to include on the driver
12 and executor classpaths.
13 --py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
14 on the PYTHONPATH for Python apps.
15 --files FILES Comma-separated list of files to be placed in the working
16 directory of each executor.
17
18 --conf PROP=VALUE Arbitrary Spark configuration property.
19 --properties-file FILE Path to a file from which to load extra properties. If not
20 specified, this will look for conf/spark-defaults.conf.
21
22 --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 512M).
23 --driver-java-options Extra Java options to pass to the driver.
24 --driver-library-path Extra library path entries to pass to the driver.
25 --driver-class-path Extra class path entries to pass to the driver. Note that
26 jars added with --jars are automatically included in the
27 classpath.
28
29 --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
30
31 --help, -h Show this help message and exit
32 --verbose, -v Print additional debug output
33
34 Spark standalone with cluster deploy mode only:
35 --driver-cores NUM Cores for driver (Default: 1).
36 --supervise If given, restarts the driver on failure.
37
38 Spark standalone and Mesos only:
39 --total-executor-cores NUM Total cores for all executors.
40
41 YARN-only:
42 --executor-cores NUM Number of cores per executor (Default: 1).
43 --queue QUEUE_NAME The YARN queue to submit to (Default: "default").
44 --num-executors NUM Number of executors to launch (Default: 2).
45 --archives ARCHIVES Comma separated list of archives to be extracted into the
46 working directory of each executor.
①提交scala实现的单词计数:
[ebupt@eb174 test]$ spark-submit --master spark://eb174:7077 --name WordCountByscala --class com.hq.WordCount --executor-memory 1G --total-executor-cores 2 ~/test/WordCount.jar hdfs://eb170:8020/user/ebupt/text
②提交java实现的单词计数:
[ebupt@eb174 test]$ spark-submit --master spark://eb174:7077 --name JavaWordCountByHQ --class com.hq.JavaWordCount --executor-memory 1G --total-executor-cores 2 ~/test/WordCount.jar hdfs://eb170:8020/user/ebupt/text
③2者运行结果类似,所以只写了一个:
1 Spark assembly has been built with Hive, including Datanucleus jars on classpath
2 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
3 14/10/10 19:24:51 INFO SecurityManager: Changing view acls to: ebupt,
4 14/10/10 19:24:51 INFO SecurityManager: Changing modify acls to: ebupt,
5 14/10/10 19:24:51 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(ebupt, ); users with modify permissions: Set(ebupt, )
6 14/10/10 19:24:52 INFO Slf4jLogger: Slf4jLogger started
7 14/10/10 19:24:52 INFO Remoting: Starting remoting
8 14/10/10 19:24:52 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@eb174:56344]
9 14/10/10 19:24:52 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkDriver@eb174:56344]
10 14/10/10 19:24:52 INFO Utils: Successfully started service 'sparkDriver' on port 56344.
11 14/10/10 19:24:52 INFO SparkEnv: Registering MapOutputTracker
12 14/10/10 19:24:52 INFO SparkEnv: Registering BlockManagerMaster
13 14/10/10 19:24:52 INFO DiskBlockManager: Created local directory at /tmp/spark-local-20141010192452-3398
14 14/10/10 19:24:52 INFO Utils: Successfully started service 'Connection manager for block manager' on port 41110.
15 14/10/10 19:24:52 INFO ConnectionManager: Bound socket to port 41110 with id = ConnectionManagerId(eb174,41110)
16 14/10/10 19:24:52 INFO MemoryStore: MemoryStore started with capacity 265.4 MB
17 14/10/10 19:24:52 INFO BlockManagerMaster: Trying to register BlockManager
18 14/10/10 19:24:52 INFO BlockManagerMasterActor: Registering block manager eb174:41110 with 265.4 MB RAM
19 14/10/10 19:24:52 INFO BlockManagerMaster: Registered BlockManager
20 14/10/10 19:24:52 INFO HttpFileServer: HTTP File server directory is /tmp/spark-8051667e-bfdb-4ecd-8111-52992b16bb13
21 14/10/10 19:24:52 INFO HttpServer: Starting HTTP Server
22 14/10/10 19:24:52 INFO Utils: Successfully started service 'HTTP file server' on port 48233.
23 14/10/10 19:24:53 INFO Utils: Successfully started service 'SparkUI' on port 4040.
24 14/10/10 19:24:53 INFO SparkUI: Started SparkUI at http://eb174:4040
25 14/10/10 19:24:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
26 14/10/10 19:24:53 INFO SparkContext: Added JAR file:/home/ebupt/test/WordCountByscala.jar at http://10.1.69.174:48233/jars/WordCountByscala.jar with timestamp 1412940293532
27 14/10/10 19:24:53 INFO AppClient$ClientActor: Connecting to master spark://eb174:7077...
28 14/10/10 19:24:53 INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
29 14/10/10 19:24:53 INFO MemoryStore: ensureFreeSpace(163705) called with curMem=0, maxMem=278302556
30 14/10/10 19:24:53 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 159.9 KB, free 265.3 MB)
31 14/10/10 19:24:53 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20141010192453-0009
32 14/10/10 19:24:53 INFO AppClient$ClientActor: Executor added: app-20141010192453-0009/0 on worker-20141008204132-eb176-49618 (eb176:49618) with 1 cores
33 14/10/10 19:24:53 INFO SparkDeploySchedulerBackend: Granted executor ID app-20141010192453-0009/0 on hostPort eb176:49618 with 1 cores, 1024.0 MB RAM
34 14/10/10 19:24:53 INFO AppClient$ClientActor: Executor added: app-20141010192453-0009/1 on worker-20141008204132-eb175-56337 (eb175:56337) with 1 cores
35 14/10/10 19:24:53 INFO SparkDeploySchedulerBackend: Granted executor ID app-20141010192453-0009/1 on hostPort eb175:56337 with 1 cores, 1024.0 MB RAM
36 14/10/10 19:24:53 INFO AppClient$ClientActor: Executor updated: app-20141010192453-0009/0 is now RUNNING
37 14/10/10 19:24:53 INFO AppClient$ClientActor: Executor updated: app-20141010192453-0009/1 is now RUNNING
38 14/10/10 19:24:53 INFO MemoryStore: ensureFreeSpace(12633) called with curMem=163705, maxMem=278302556
39 14/10/10 19:24:53 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 12.3 KB, free 265.2 MB)
40 14/10/10 19:24:53 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on eb174:41110 (size: 12.3 KB, free: 265.4 MB)
41 14/10/10 19:24:53 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
42 14/10/10 19:24:54 INFO FileInputFormat: Total input paths to process : 1
43 14/10/10 19:24:54 INFO SparkContext: Starting job: collect at WordCount.scala:26
44 14/10/10 19:24:54 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:26)
45 14/10/10 19:24:54 INFO DAGScheduler: Got job 0 (collect at WordCount.scala:26) with 2 output partitions (allowLocal=false)
46 14/10/10 19:24:54 INFO DAGScheduler: Final stage: Stage 0(collect at WordCount.scala:26)
47 14/10/10 19:24:54 INFO DAGScheduler: Parents of final stage: List(Stage 1)
48 14/10/10 19:24:54 INFO DAGScheduler: Missing parents: List(Stage 1)
49 14/10/10 19:24:54 INFO DAGScheduler: Submitting Stage 1 (MappedRDD[3] at map at WordCount.scala:26), which has no missing parents
50 14/10/10 19:24:54 INFO MemoryStore: ensureFreeSpace(3400) called with curMem=176338, maxMem=278302556
51 14/10/10 19:24:54 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 3.3 KB, free 265.2 MB)
52 14/10/10 19:24:54 INFO MemoryStore: ensureFreeSpace(2082) called with curMem=179738, maxMem=278302556
53 14/10/10 19:24:54 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.0 KB, free 265.2 MB)
54 14/10/10 19:24:54 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on eb174:41110 (size: 2.0 KB, free: 265.4 MB)
55 14/10/10 19:24:54 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0
56 14/10/10 19:24:54 INFO DAGScheduler: Submitting 2 missing tasks from Stage 1 (MappedRDD[3] at map at WordCount.scala:26)
57 14/10/10 19:24:54 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
58 14/10/10 19:24:56 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@eb176:35482/user/Executor#1456950111] with ID 0
59 14/10/10 19:24:56 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 0, eb176, ANY, 1238 bytes)
60 14/10/10 19:24:56 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@eb175:35502/user/Executor#-1231100997] with ID 1
61 14/10/10 19:24:56 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 1, eb175, ANY, 1238 bytes)
62 14/10/10 19:24:56 INFO BlockManagerMasterActor: Registering block manager eb176:33296 with 530.3 MB RAM
63 14/10/10 19:24:56 INFO BlockManagerMasterActor: Registering block manager eb175:32903 with 530.3 MB RAM
64 14/10/10 19:24:57 INFO ConnectionManager: Accepted connection from [eb176/10.1.69.176:39218]
65 14/10/10 19:24:57 INFO ConnectionManager: Accepted connection from [eb175/10.1.69.175:55227]
66 14/10/10 19:24:57 INFO SendingConnection: Initiating connection to [eb176/10.1.69.176:33296]
67 14/10/10 19:24:57 INFO SendingConnection: Initiating connection to [eb175/10.1.69.175:32903]
68 14/10/10 19:24:57 INFO SendingConnection: Connected to [eb175/10.1.69.175:32903], 1 messages pending
69 14/10/10 19:24:57 INFO SendingConnection: Connected to [eb176/10.1.69.176:33296], 1 messages pending
70 14/10/10 19:24:57 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on eb175:32903 (size: 2.0 KB, free: 530.3 MB)
71 14/10/10 19:24:57 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on eb176:33296 (size: 2.0 KB, free: 530.3 MB)
72 14/10/10 19:24:57 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on eb176:33296 (size: 12.3 KB, free: 530.3 MB)
73 14/10/10 19:24:57 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on eb175:32903 (size: 12.3 KB, free: 530.3 MB)
74 14/10/10 19:24:58 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 1) in 1697 ms on eb175 (1/2)
75 14/10/10 19:24:58 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 0) in 1715 ms on eb176 (2/2)
76 14/10/10 19:24:58 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
77 14/10/10 19:24:58 INFO DAGScheduler: Stage 1 (map at WordCount.scala:26) finished in 3.593 s
78 14/10/10 19:24:58 INFO DAGScheduler: looking for newly runnable stages
79 14/10/10 19:24:58 INFO DAGScheduler: running: Set()
80 14/10/10 19:24:58 INFO DAGScheduler: waiting: Set(Stage 0)
81 14/10/10 19:24:58 INFO DAGScheduler: failed: Set()
82 14/10/10 19:24:58 INFO DAGScheduler: Missing parents for Stage 0: List()
83 14/10/10 19:24:58 INFO DAGScheduler: Submitting Stage 0 (ShuffledRDD[4] at reduceByKey at WordCount.scala:26), which is now runnable
84 14/10/10 19:24:58 INFO MemoryStore: ensureFreeSpace(2096) called with curMem=181820, maxMem=278302556
85 14/10/10 19:24:58 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.0 KB, free 265.2 MB)
86 14/10/10 19:24:58 INFO MemoryStore: ensureFreeSpace(1338) called with curMem=183916, maxMem=278302556
87 14/10/10 19:24:58 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1338.0 B, free 265.2 MB)
88 14/10/10 19:24:58 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on eb174:41110 (size: 1338.0 B, free: 265.4 MB)
89 14/10/10 19:24:58 INFO BlockManagerMaster: Updated info of block broadcast_2_piece0
90 14/10/10 19:24:58 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (ShuffledRDD[4] at reduceByKey at WordCount.scala:26)
91 14/10/10 19:24:58 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
92 14/10/10 19:24:58 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 2, eb175, PROCESS_LOCAL, 1008 bytes)
93 14/10/10 19:24:58 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 3, eb176, PROCESS_LOCAL, 1008 bytes)
94 14/10/10 19:24:58 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on eb175:32903 (size: 1338.0 B, free: 530.3 MB)
95 14/10/10 19:24:58 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on eb176:33296 (size: 1338.0 B, free: 530.3 MB)
96 14/10/10 19:24:58 INFO MapOutputTrackerMasterActor: Asked to send map output locations for shuffle 0 to sparkExecutor@eb175:59119
97 14/10/10 19:24:58 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 144 bytes
98 14/10/10 19:24:58 INFO MapOutputTrackerMasterActor: Asked to send map output locations for shuffle 0 to sparkExecutor@eb176:39028
99 14/10/10 19:24:58 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 3) in 109 ms on eb176 (1/2)
100 14/10/10 19:24:58 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 2) in 120 ms on eb175 (2/2)
101 14/10/10 19:24:58 INFO DAGScheduler: Stage 0 (collect at WordCount.scala:26) finished in 0.123 s
102 14/10/10 19:24:58 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
103 14/10/10 19:24:58 INFO SparkContext: Job finished: collect at WordCount.scala:26, took 3.815637915 s
104 (scala,1)
105 (Function2,1)
106 (JavaSparkContext,1)
107 (JavaRDD,1)
108 (Tuple2,1)
109 (,1)
110 (org,7)
111 (apache,7)
112 (JavaPairRDD,1)
113 (java,7)
114 (function,4)
115 (api,7)
116 (Function,1)
117 (PairFunction,1)
118 (spark,7)
119 (FlatMapFunction,1)
120 (import,8)
121 14/10/10 19:24:58 INFO SparkUI: Stopped Spark web UI at http://eb174:4040
122 14/10/10 19:24:58 INFO DAGScheduler: Stopping DAGScheduler
123 14/10/10 19:24:58 INFO SparkDeploySchedulerBackend: Shutting down all executors
124 14/10/10 19:24:58 INFO SparkDeploySchedulerBackend: Asking each executor to shut down
125 14/10/10 19:24:58 INFO ConnectionManager: Removing SendingConnection to ConnectionManagerId(eb176,33296)
126 14/10/10 19:24:58 INFO ConnectionManager: Removing ReceivingConnection to ConnectionManagerId(eb176,33296)
127 14/10/10 19:24:58 ERROR ConnectionManager: Corresponding SendingConnection to ConnectionManagerId(eb176,33296) not found
128 14/10/10 19:24:58 INFO ConnectionManager: Removing ReceivingConnection to ConnectionManagerId(eb175,32903)
129 14/10/10 19:24:58 INFO ConnectionManager: Removing SendingConnection to ConnectionManagerId(eb175,32903)
130 14/10/10 19:24:58 INFO ConnectionManager: Removing SendingConnection to ConnectionManagerId(eb175,32903)
131 14/10/10 19:24:58 INFO ConnectionManager: Key not valid ? sun.nio.ch.SelectionKeyImpl@5e92c11b
132 14/10/10 19:24:58 INFO ConnectionManager: key already cancelled ? sun.nio.ch.SelectionKeyImpl@5e92c11b
133 java.nio.channels.CancelledKeyException
134 at org.apache.spark.network.ConnectionManager.run(ConnectionManager.scala:310)
135 at org.apache.spark.network.ConnectionManager$$anon$4.run(ConnectionManager.scala:139)
136 14/10/10 19:24:59 INFO MapOutputTrackerMasterActor: MapOutputTrackerActor stopped!
137 14/10/10 19:24:59 INFO ConnectionManager: Selector thread was interrupted!
138 14/10/10 19:24:59 INFO ConnectionManager: Removing ReceivingConnection to ConnectionManagerId(eb176,33296)
139 14/10/10 19:24:59 ERROR ConnectionManager: Corresponding SendingConnection to ConnectionManagerId(eb176,33296) not found
140 14/10/10 19:24:59 INFO ConnectionManager: Removing SendingConnection to ConnectionManagerId(eb176,33296)
141 14/10/10 19:24:59 WARN ConnectionManager: All connections not cleaned up
142 14/10/10 19:24:59 INFO ConnectionManager: ConnectionManager stopped
143 14/10/10 19:24:59 INFO MemoryStore: MemoryStore cleared
144 14/10/10 19:24:59 INFO BlockManager: BlockManager stopped
145 14/10/10 19:24:59 INFO BlockManagerMaster: BlockManagerMaster stopped
146 14/10/10 19:24:59 INFO SparkContext: Successfully stopped SparkContext
147 14/10/10 19:24:59 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
148 14/10/10 19:24:59 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
149 14/10/10 19:24:59 INFO Remoting: Remoting shut down
150 14/10/10 19:24:59 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
5.参考资料
关于IDEA的使用:Scala从零开始:使用Intellij IDEA写hello world
scala编写WC: Spark wordcount开发并提交到集群运行
java编写WC:用java编写spark程序,简单示例及运行、Spark在Yarn上运行Wordcount程序
Spark:用Scala和Java实现WordCount的更多相关文章
- Spark 用Scala和Java分别实现wordcount
Scala import org.apache.spark.{SparkConf, SparkContext} object wordcount { def main(args: Array[Stri ...
- 0基础就可以上手的Spark脚本开发-for Java
前言 最近由于工作需要,要分析大几百G的Nginx日志数据.之前也有过类似的需求,但那个时候数据量不多.一次只有几百兆,或者几个G.因为数据都在Hive里面,当时的做法是:把数据从Hive导到MySQ ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- java+hadoop+spark+hbase+scala+kafka+zookeeper配置环境变量记录备忘
java+hadoop+spark+hbase+scala 在/etc/profile 下面加上如下环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_102 expor ...
- spark提示Caused by: java.lang.ClassCastException: scala.collection.mutable.WrappedArray$ofRef cannot be cast to [Lscala.collection.immutable.Map;
spark提示Caused by: java.lang.ClassCastException: scala.collection.mutable.WrappedArray$ofRef cannot b ...
- spark之scala程序开发(集群运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
- 用maven来创建scala和java项目代码环境(图文详解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆适用)(博主推荐)
不多说,直接上干货! 为什么要写这篇博客? 首先,对于spark项目,强烈建议搭建,用Intellij IDEA(Ultimate版本),如果你还有另所爱好尝试Scala IDEA for Eclip ...
- Win7 Eclipse 搭建spark java1.8(lambda)环境:WordCount helloworld例子
[学习笔记] Win7 Eclipse 搭建spark java1.8(lambda)环境:WordCount helloworld例子 lambda表达式是java8给我们带来的一个重量的新特性,借 ...
随机推荐
- leetcode@ [126] Word Ladder II (BFS + 层次遍历 + DFS)
https://leetcode.com/problems/word-ladder-ii/ Given two words (beginWord and endWord), and a diction ...
- leetcode@ [72/115] Edit Distance & Distinct Subsequences (Dynamic Programming)
https://leetcode.com/problems/edit-distance/ Given two words word1 and word2, find the minimum numbe ...
- leetcode@ [131/132] Palindrome Partitioning & Palindrome Partitioning II
https://leetcode.com/problems/palindrome-partitioning/ Given a string s, partition s such that every ...
- python 递归函数
在函数内部,可以调用其他函数.如果一个函数在内部调用自身本身,这个函数就是递归函数. 举个例子,我们来计算阶乘n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示,可以看出: f ...
- 《MEF程序设计指南》博文汇总
<MEF程序设计指南>博文汇总 在MEF之前,人们已经提出了许多依赖注入框架来解决应用的扩展性问题,比如OSGI 实现以Spring 等等.在 Microsoft 的平台上,.NET Fr ...
- 如何在64位系统上安装SQL Server 2000
如何在64位系统上安装SQL Server 2000? 现在用SQL Server 2000数据库的人少了吧?大都是SQL Server 2005/2008了.不过还是有需求的,今天一朋友就让我在他的 ...
- PowerDesigner 物理数据模型(PDM)
PowerDesigner 物理数据模型(PDM) 说明 数据库脚本sqldatabasegeneration存储 目录(?)[+] 一. PDM 介绍 物理数据模型(Physical ...
- android studio里的build.gradle基本属性
//声明是android 程序 apply plugin: 'com.android.application' android { //编译SDK版本 compileSdkVersion 23 // ...
- 在WWDC 2014上,没提到的iOS 8 八大新特性
今天凌晨1点,36氪如约为大家研磨出WWDC 2014全程 "贴身直播"(我不得不佩服牺牲个人时间,熬夜为大家奉上好文的5位氪星人:JasonZheng.WANGJINGYU.pa ...
- orderby group by
说到SQL语句,大家最開始想到的就是他的查询语句: select* from tableName: 这是最简单的一种查询方式,不带有不论什么的条件. 当然在我们的实际应用中,这条语句也是非经常常使用到 ...