3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试
一、说明
从上一节可看出,虽然搭建好了HA架构,但是只能手动进行active与standby的切换;
接下来看一下用zookeeper进行自动故障转移:
#
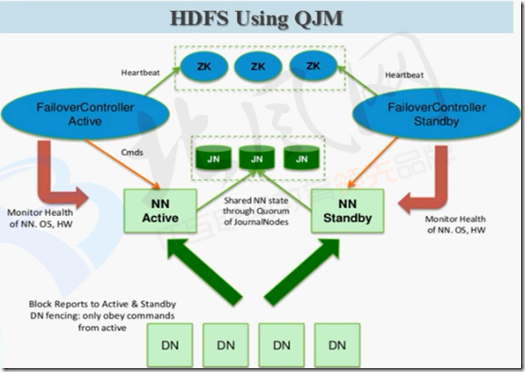
在启动HA之后,两个NameNode都是standby状态,可以利用zookeeper的选举功能,选出一个当Active #
监控
ZKFC
FailoverController
二、配置
1、hdfs-site.xml
#”开启自动转移功能“,加入以下内容;
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
2、core-site.xml
#”设置故障转移的zookeeper集群“,加入以下内容;
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
3、关闭集群所有服务
#master
[root@master hadoop-2.5.0]# sbin/stop-dfs.sh [root@master ~]# xcall jps
====== master jps ======
18719 Jps
====== slave1 jps ======
19150 Jps
====== slave2 jps ======
13595 Jps #如果还有其他服务(zookeeper等)也要关闭;
4、同步配置文件
[root@master hadoop]# pwd
/opt/app/hadoop-2.5.0/etc/hadoop [root@master hadoop]# scp -r hdfs-site.xml core-site.xml root@slave1:/opt/app/hadoop-2.5.0/etc/hadoop/ [root@master hadoop]# scp -r hdfs-site.xml core-site.xml root@slave2:/opt/app/hadoop-2.5.0/etc/hadoop/
5、启动zookeeper
#所有节点启动zookeeper
[root@master ~]# /opt/app/zookeeper-3.4.5/bin/zkServer.sh start [root@slave1 ~]# /opt/app/zookeeper-3.4.5/bin/zkServer.sh start [root@slave2 ~]# /opt/app/zookeeper-3.4.5/bin/zkServer.sh start #查看
[root@master ~]# xcall jps
====== master jps ======
18824 Jps
18765 QuorumPeerMain
====== slave1 jps ======
19201 QuorumPeerMain
19263 Jps
====== slave2 jps ======
13646 QuorumPeerMain
13702 Jps
6、初始化HA在Zookeeper中状态
#master
[root@master hadoop-2.5.0]# bin/hdfs zkfc -formatZK #
此时可以在slave1上用客户端连入zookeeper查看:
[root@slave1 zookeeper-3.4.5]# bin/zkCli.sh [zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper] [zk: localhost:2181(CONNECTED) 2] ls / #生成了hadoop-ha
[hadoop-ha, zookeeper]
7、启动HDFS服务
#master
[root@master hadoop-2.5.0]# sbin/start-dfs.sh #查看启动情况
[root@master ~]# xcall jps
====== master jps ======
19588 DFSZKFailoverController #ZKFC监控进程
19087 NameNode
19193 DataNode
19393 JournalNode
18765 QuorumPeerMain
19662 Jps
====== slave1 jps ======
19743 DFSZKFailoverController #ZKFC监控进程
19201 QuorumPeerMain
19800 Jps
19613 JournalNode
19521 DataNode
19443 NameNode
====== slave2 jps ======
13646 QuorumPeerMain
13850 DataNode
14014 Jps
13942 JournalNode #查看nn1 nn2的状态
[root@master hadoop-2.5.0]# bin/hdfs haadmin -getServiceState nn1
19/04/18 10:34:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active [root@master hadoop-2.5.0]# bin/hdfs haadmin -getServiceState nn2
19/04/18 10:34:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby #可见已经自动把nn1选举为active了,nn2为standby;在web中也可以看到;
8、测试故障自动转移
可以kill掉active状态的namenode,查看standby状态的namenode是否已经自动变为active了;
3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试的更多相关文章
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- 【解决】HDFS HA无法自动切换问题
[解决]HDFS HA无法自动切换问题 原因: 最早设置为root互相登录,可是zkfc服务是hdfs账号运行的,没有权限访问到root的id_rsa文件.更改为hdfs账号免密钥登录恢复正常. ...
- keepalive配置mysql自动故障转移
keepalive配置mysql自动故障转移 原创 2016年02月29日 02:16:52 2640 本文先配置了一个双master环境,互为主从,然后通过Keepalive配置了一个虚拟IP,客户 ...
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- 【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】
问题描述: 上一篇就是NameNode 的HA 部署完成,但是存在问题,问题是如果 主NameNode的节点宕机了,还是需要人工去使用命令来切换NameNode的Acitve 这样很不方便,所以 ...
- zookeeper:springboot+dubbo配置zk集群并测试
1.springboot配置zk集群 1.1:非主从配置方法 dubbo: registry: protocol: zookeeper address: ,, check: false 1.2:主从配 ...
- MongoDB副本集配置系列十一:MongoDB 数据同步原理和自动故障转移的原理
1:数据同步的原理: 当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步: 1:检查自己local库的oplog.rs集合找出最近的时间戳. 2:检查Primary ...
- 大数据(3) - 高可用 HDFS HA
HDFS HA高可用 1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制 ...
- 【Zookeeper】利用zookeeper搭建Hdoop HA高可用
HA概述 所谓HA(high available),即高可用(7*24小时不中断服务). 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA. ...
随机推荐
- python-tornado操作
Tornado 是 FriendFeed 使用的可扩展的非阻塞式 web 服务器及其相关工具的开源版本.这个 Web 框架看起来有些像web.py 或者 Google 的 webapp,不过为了能有效 ...
- Creating Tabbed Applications
新建一个空工程,如图 新建类 using System; using UIKit; namespace TabbedApplication { public class TabController : ...
- wpf Style也继承(包含内部定义事件)
如何在既定皮肤下为某个style添加内容是我今天碰的问题,皮肤往往是对全局control进行设置的,当然这就无法满足某个个性十足的“另类”了,比如当使用DataGridCheckBoxColumn时, ...
- redis文档翻译_LRU缓存
Using Redis as an LRU cache使用Redis作为LRU缓存 出处:http://blog.csdn.net/column/details/redisbanli.html Whe ...
- iOS进程间通信之CFMessagePort
本文转载至 http://www.cocoachina.com/industry/20140606/8701.html iOS系统是出了名的封闭,每个应用的活动范围被严格地限制在各自的沙盒中.尽管如此 ...
- EasyPusher直播推送中用到的缓冲区设计和丢帧原理
问题描述 我们在开发直播过程中,会需要用到直播推送端,推送端将直播的音视频数据推送到流媒体服务器或者cdn,再由流媒体服务器/CDN进行视频的转发和分发,提供给客户端进行观看.由于直播推送端会存在于各 ...
- GO 入门(一)
1.下载安装go环境 https://golang.org/dl/ 2.检查环境变量配置情况,安装过程中会自动配置:GOROOT 和 Path 3.建立go工作区,并配置 ...
- Unable to start adb server: adb server version (32) doesn't match this client (39); killing...
关于Android studio 连接不上adb问题,有人说重启机器,有人说重启工具,也有人说adb kill-server.然后我都尝试过依然没有解决.通过各种查询.最终成功的解决!!! adb n ...
- Android Studio 卡顿解决
每次升级/安装 Android Studio 之后最好都修改一下这个参数:到 Android Studio 安装目录,找到 bin/studio(64?).vmoptions(文件名可能因操作系统而不 ...
- Promise 源码分析
前言 then/promise项目是基于Promises/A+标准实现的Promise库,从这个项目当中,我们来看Promise的原理是什么,它是如何做到的,从而更加熟悉Promise 分析 从ind ...