软阈值迭代算法(ISTA)和快速软阈值迭代算法(FISTA)
缺月挂疏桐,漏断人初静。
谁见幽人独往来,缥缈孤鸿影。
惊起却回头,有恨无人省。
拣尽寒枝不肯栖,寂寞沙洲冷。---- 苏轼
更多精彩内容请关注微信公众号 “优化与算法”
ISTA算法和FISTA算法是求解线性逆问题的经典方法,隶属于梯度类算法,也常用于压缩感知重构算法中,隶属于梯度类算法,这次将这2中算法原理做简单分析,并给出matlab仿真实验,通过实验结果来验证算法性能。
1. 引言
对于一个基本的线性逆问题:
\quad \quad \quad \quad\quad \quad\quad \quad(1)\]
其中\({\bf{A }} \in {^{M \times N}}\), \({\bf{y }} \in {^{M}}\)且是已知的,\(\bf{w}\)是未知噪声。
(1)式可用最小二乘法(Least Squares)来求解:
\quad \quad \quad \quad\quad \quad\quad \quad(2)\]
当 \(M=N\) 且 \(\bf{A}\) 非奇异时,最小二乘法的解等价于\(\bf{A^{-1}y}\)。
然而,在很多情况下,\(\bf(A)\) 是病态的(ill-conditioned),此时,用最小二乘法求解时,系统微小的扰动都会导致结果差别很大,可谓失之毫厘谬以千里,因此最小二乘法不适用于求解病态方程。
什么是条件数?矩阵 \(\bf{A}\) 的条件数是指 \(\bf{A}\) 的最大奇异值与最小奇异值的比值,显然条件数最小为1,条件数越小说明矩阵越趋于“良态”,条件数越大,矩阵越趋于奇异,从而趋于“病态”。
为了求解病态线性系统的逆问题,前苏联科学家安德烈·尼古拉耶维奇·吉洪诺夫提出了吉洪诺夫正则化方法(Tikhonov regularization),该方法也称为“岭回归”。最小二乘是一种无偏估计方法(保真度很好),如果系统是病态的,则会导致其估计方差很大(对扰动很敏感),吉洪诺夫正则化方法的主要思想是以可容忍的微小偏差来换取估计的良好效果,实现方差和偏差的一个trade-off。吉洪诺夫正则化求解病态问题可以表示为:
\quad \quad \quad \quad\quad \quad\quad \quad(3)\]
其中\(\lambda>0\) 为正则化参数。问题(3)的解等价于如下岭回归估计器:
\]
安德烈·尼古拉耶维奇·蒂霍诺夫(俄文:阿尔瓦勒德普列耶娃;1906年10月17日至1993年10月7日)是苏联和俄罗斯数学家和地球物理学家,以对拓扑学、泛函分析、数学物理和不适定问题的重要贡献而闻名。他也是地球物理学中大地电磁法的发明者之一。

岭回归是采用 \({\ell _2}\) 范数作为正则项,另一种求解式(1)的方法是采用 \({\ell _1}\) 范数作为正则项,这就是经典的LASSO(Least absolute shrinkage and selection operator)问题:
\]
采用 \({\ell _1}\) 范数正则项相对于 \({\ell _2}\) 范数正则项有两个优势,第一个优势是 \({\ell _1}\) 范数正则项能产生稀疏解,第二个优势是其具有对异常值不敏感的特性,这一点恰好与岭回归相反。
式(5)中的问题是一个凸优化问题,通常可以转化为二阶锥规划(second order cone programming)问题,从而使用内点法(interior point)等方法求解。然而在大规模问题中,由于数据维度太大,而内点法的算法复杂度为 \(O({N^3})\),导致求解非常耗时。
基于上述原因,很多研究者研究通过简单的基于梯度的方法来求解(5)式。基于梯度的方法其计算量主要集中在矩阵 \(\bf{A}\) 与向量 \(\bf{y}\) 的乘积上,算法复杂度小,而且算法结构简单,容易操作。
2. 迭代收缩阈值算法(ISTA)
在众多基于梯度的算法中,迭代收缩阈值算法(Iterative Shrinkage Thresholding Algorithm)是一种非常受关注的算法,ISTA算法在每一次迭代中通过一个收缩/软阈值操作来更新 \(\bf{x}\),其具体迭代格式如下:
\]
其中 \({{\mathop{\rm soft}\nolimits} _{\lambda t}}( \cdot )\) 是软阈值操作函数:
\]
软阈值操作函数如下图所示:
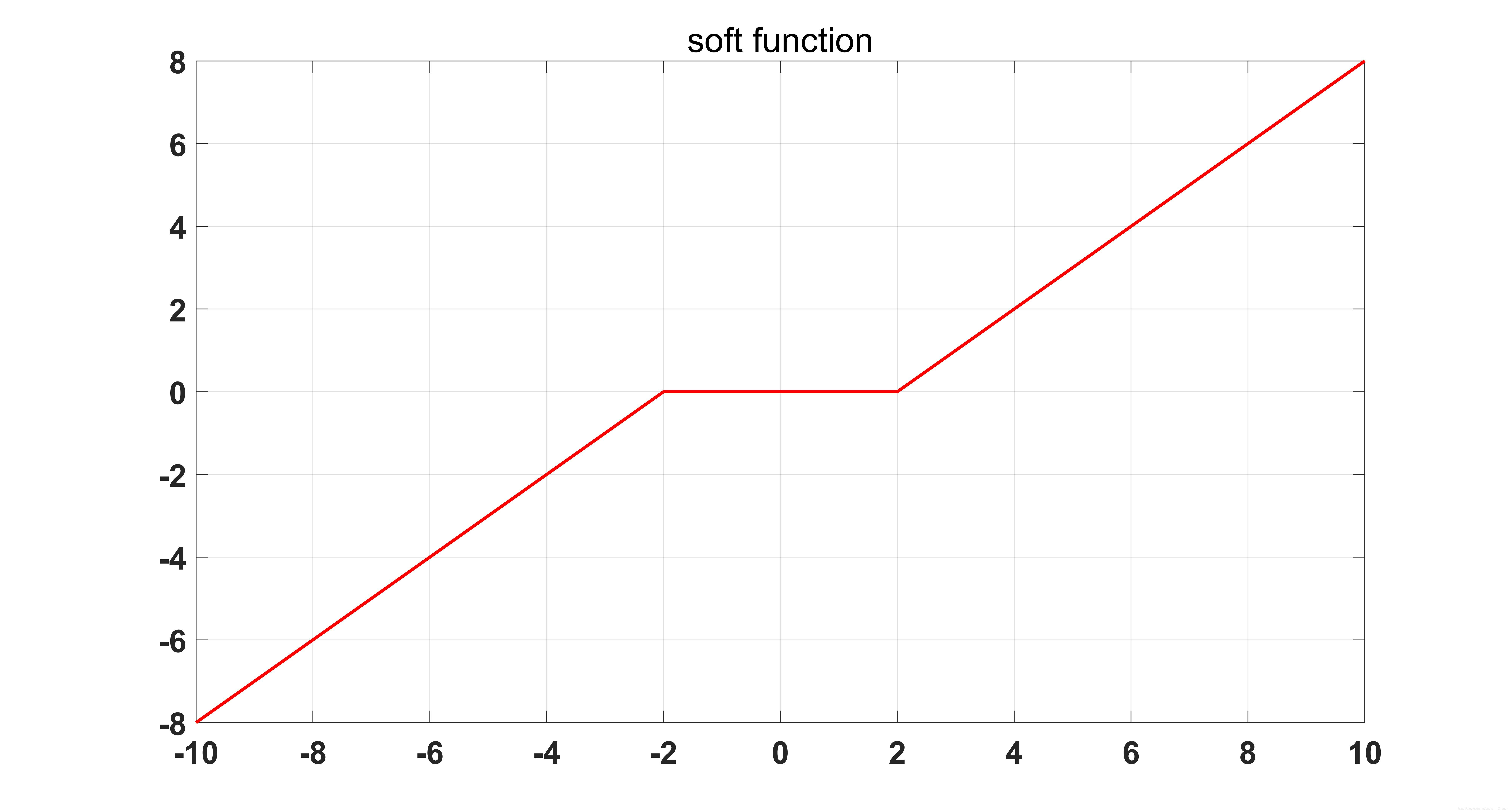
其中 \(sign()\) 是符号函数。
那么ISTA的迭代格式(6)式是怎么来的呢?算法中的“收缩阈值”体现在哪里?这要从梯度下降法(Gradient Descent)说起。
考虑一个连续可导的无约束最小化问题:
\]
(8)式可用梯度下降法来求解:
\]
这里 \(t_k>0\) 是迭代步长。我们知道,梯度下降法可以表示成 \(f\) 在点 \(x_{k-1}\) 处的近端正则化(proximal regularization),其等价形式可以表示为:
\]
(9)-(10)可由李普希兹连续条件 \({\left\| {\nabla f({{\bf{x}}_k}) - \nabla f({{\bf{x}}_{k - 1}})} \right\|_2} \le L(f){\left\| {{{\bf{x}}_k} - {{\bf{x}}_{k - 1}}} \right\|_2}\) 和 \(f\) 在 \(x_{k-1}\) 处的2阶泰勒展开得到,很简单,这里不再赘述。
将(8)式加上 \({\ell _1}\) 范数正则项,得到:
\]
则(10)式相应变成:
\]
时(12)忽略掉常数项 \(f(\bf x_{k-1})\) 和 \({\nabla f({{\bf{x}}_{k - 1}})}\) 之后,(12)式可以写成:
\]
文献中已经证明,当迭代步长取 \(f\) 的李普希兹常数的倒数(即 \({1 \over {L(f)}}\))时,由ISTA算法生成的序列 \(\bf x_k\) 的收敛速度为 \(O({1 \over {\rm{k}}})\) ,显然为次线性收敛速度。
ISTA算法的伪代码见原文,matlab代码如下:
function [x_hat,error] = cs_ista(y,A,lambda,epsilon,itermax)
% Iterative Soft Thresholding Algorithm(ISTA)
% Version: 1.0 written by Louis Zhang @2019-12-7
% Reference: Beck, Amir, and Marc Teboulle. "A fast iterative
% shrinkage-thresholding algorithm for linear inverse problems."
% SIAM journal on imaging sciences 2.1 (2009): 183-202.
% Inputs:
% y - measurement vector
% A - measurement matrix
% lambda - denoiser parameter in the noisy case
% epsilon - error threshold
% inter_max - maximum number of amp iterations
%
% Outputs:
% x_hat - the last estimate
% error - reconstruction error
if nargin < 5
itermax = 10000 ;
end
if nargin < 4
epsilon = 1e-4 ;
end
if nargin < 3
lambda = 2e-5 ;
end
N = size(A,2) ;
error = [];
x_1 = zeros(N,1) ;
for i = 1:itermax
g_1 = A'*(y - A*x_1) ;
alpha = 1 ;
% obtain step size alpha by line search
% alpha = (g_1'*g_1)/((A*g_1)'*(A*g_1)) ;
x_2 = x_1 + alpha * g_1 ;
x_hat = sign(x_2).*max(abs(x_2)-alpha*lambda,0) ;
error(i,1) = norm(x_hat - x_1) / norm(x_hat) ;
error(i,2) = norm(y-A*x_hat) ;
if error(i,1) < epsilon || error(i,1) < epsilon
break;
else
x_1 = x_hat ;
end
end
实际过程中,矩阵 \(\bf A\) 通常很大,计算其李普希兹常数非常困难,因此出现了ISTA算法的Backtracking版本,通过不断收缩迭代步长的策略使其收敛。
3. 快速迭代收缩阈值算法(Fast Iterative Shrinkage Thresholding Algorithm, FISTA)
为了加速ISTA算法的收敛,文献中作者采用了著名的梯度加速策略Nesterov加速技术,使得ISTA算法的收敛速度从 \(O({1 \over {\rm{k}}})\) 变成 \(O({1 \over {\rm{k^2}}})\)。具体的证明过程可参见原文的定理4.1。
FISTA与ISTA算法相比,仅仅多了个Nesterov加速步骤,以极少的额外计算量大幅提高了算法的收敛速度。而且不仅在FISTA算法中,在几乎所有与梯度有关的算法中,Nesterov加速技术都可以使用。那Nesterov加速技术为何如此神通广大呢?
Nesterov加速技术由大神Yurii Nesterov于1983年提出来的,它与目前深度学习中用到的经典的动量方法(Momentum method)很相似,和动量方法的区别在于二者用到了不同点的梯度,动量方法采用的是上一步迭代点的梯度,而Nesterov方法则采用从上一步迭代点处朝前走一步处的梯度。具体对比如下。
动量方法:
\]
\]
Nesterov方法:
\]
\]
对比可发现,Nesterov方法和动量方法几乎一样,只是梯度处稍有差别。下图能更直观看出二者的区别。
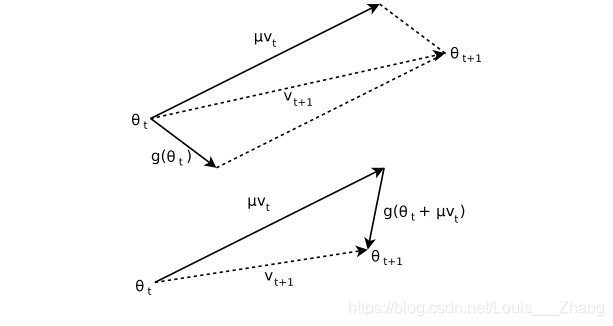
尤里·内斯特罗夫是俄罗斯数学家,国际公认的凸优化专家,特别是在高效算法开发和数值优化分析方面。他现在是卢旺大学的教授。

FISTA算法的伪代码见原文,matlab代码如下:
function [x_2,error] = cs_fista(y,A,lambda,epsilon,itermax)
% Fast Iterative Soft Thresholding Algorithm(FISTA)
% Version: 1.0 written by yfzhang @2019-12-8
% Reference: Beck, Amir, and Marc Teboulle. "A fast iterative
% shrinkage-thresholding algorithm for linear inverse problems."
% SIAM journal on imaging sciences 2.1 (2009): 183-202.
% Inputs:
% y - measurement vector
% A - measurement matrix
% lambda - denoiser parameter in the noisy case
% epsilon - error threshold
% inter_max - maximum number of amp iterations
%
% Outputs:
% x_hat - the last estimate
% error - reconstruction error
if nargin < 5
itermax = 10000 ;
end
if nargin < 4
epsilon = 1e-4 ;
end
if nargin < 3
lambda = 2e-5 ;
end
N = size(A,2);
error = [] ;
x_0 = zeros(N,1);
x_1 = zeros(N,1);
t_0 = 1 ;
for i = 1:itermax
t_1 = (1+sqrt(1+4*t_0^2))/2 ;
% g_1 = A'*(y-A*x_1);
alpha =1;
% alpha = (g_1'*g_1)/((A*g_1)'*(A*g_1)) ;
z_2 = x_1 + ((t_0-1)/(t_1))*(x_1 - x_0) ;
z_2 = z_2+A'*(y-A*z_2);
x_2 = sign(z_2).*max(abs(z_2)-alpha*lambda,0) ;
error(i,1) = norm(x_2 - x_1)/norm(x_2) ;
error(i,2) = norm(y-A*x_2) ;
if error(i,1) < epsilon || error(i,2) < epsilon
break;
else
x_0 = x_1 ;
x_1 = x_2 ;
t_0 = t_1 ;
end
end
4. 仿真实验
为了验证ISTA算法和FISTA算法的算法性能,此处用一维随机高斯信号做实验,测试程序如下:
% One-dimensional random Gaussian signal test script for CS reconstruction
% algorithm
% Version: 1.0 written by yfzhang @2019-12-8
clear
clc
N = 1024 ;
M = 512 ;
K = 10 ;
x = zeros(N,1);
T = 5*randn(K,1);
index_k = randperm(N);
x(index_k(1:K)) = T;
A = randn(M,N);
A=sqrt(1/M)*A;
A = orth(A')';
% sigma = 1e-4 ;
% e = sigma*randn(M,1);
y = A * x ;% + e ;
[x_rec1,error1] = cs_fista(y,A,5e-3,1e-4,5e3) ;
[x_rec2,error2] = cs_ista(y,A,5e-3,1e-4,5e3) ;
figure (1)
plot(error1(:,2),'r-');
hold on
plot(error2(:,2),'b-');
仿真结果图如下所示:
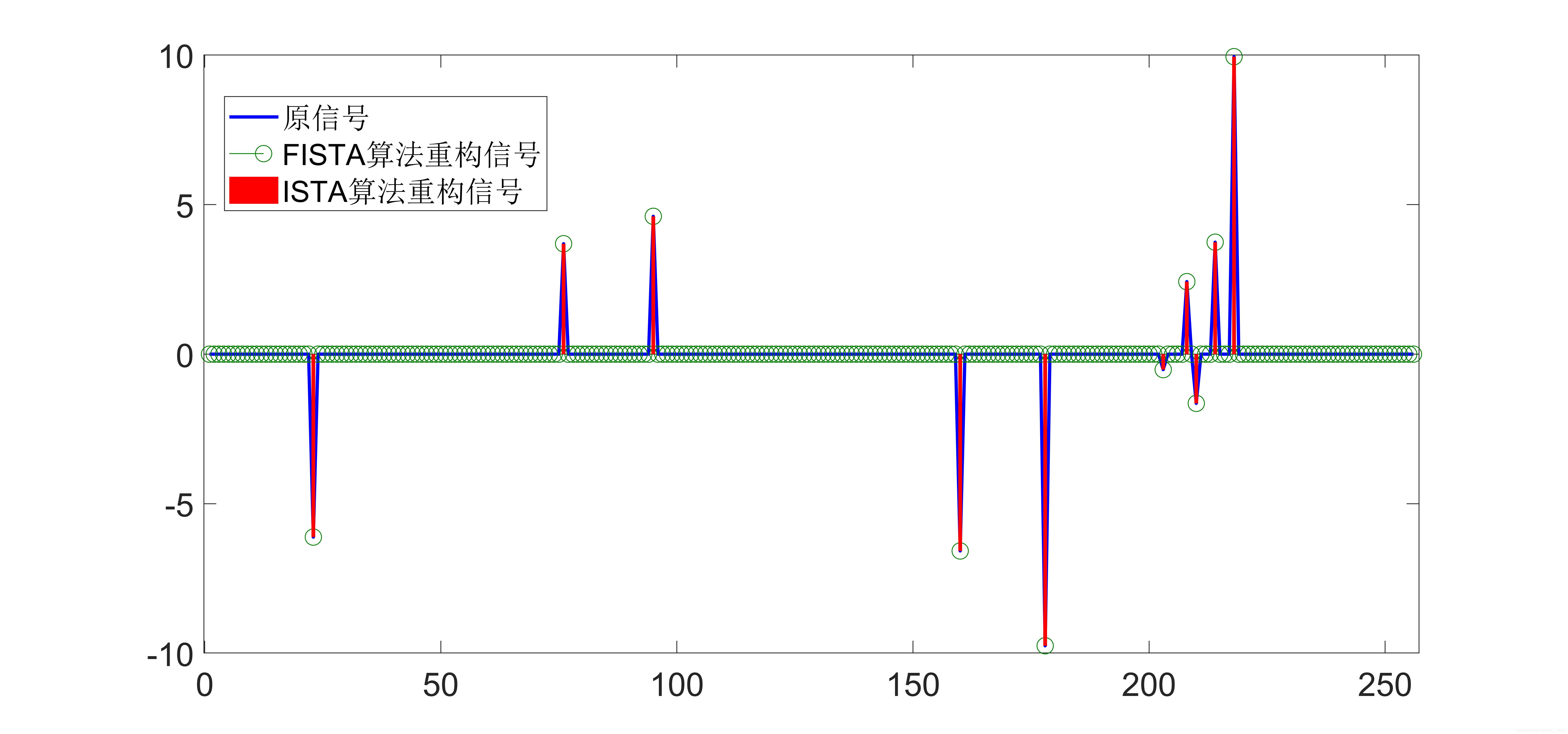
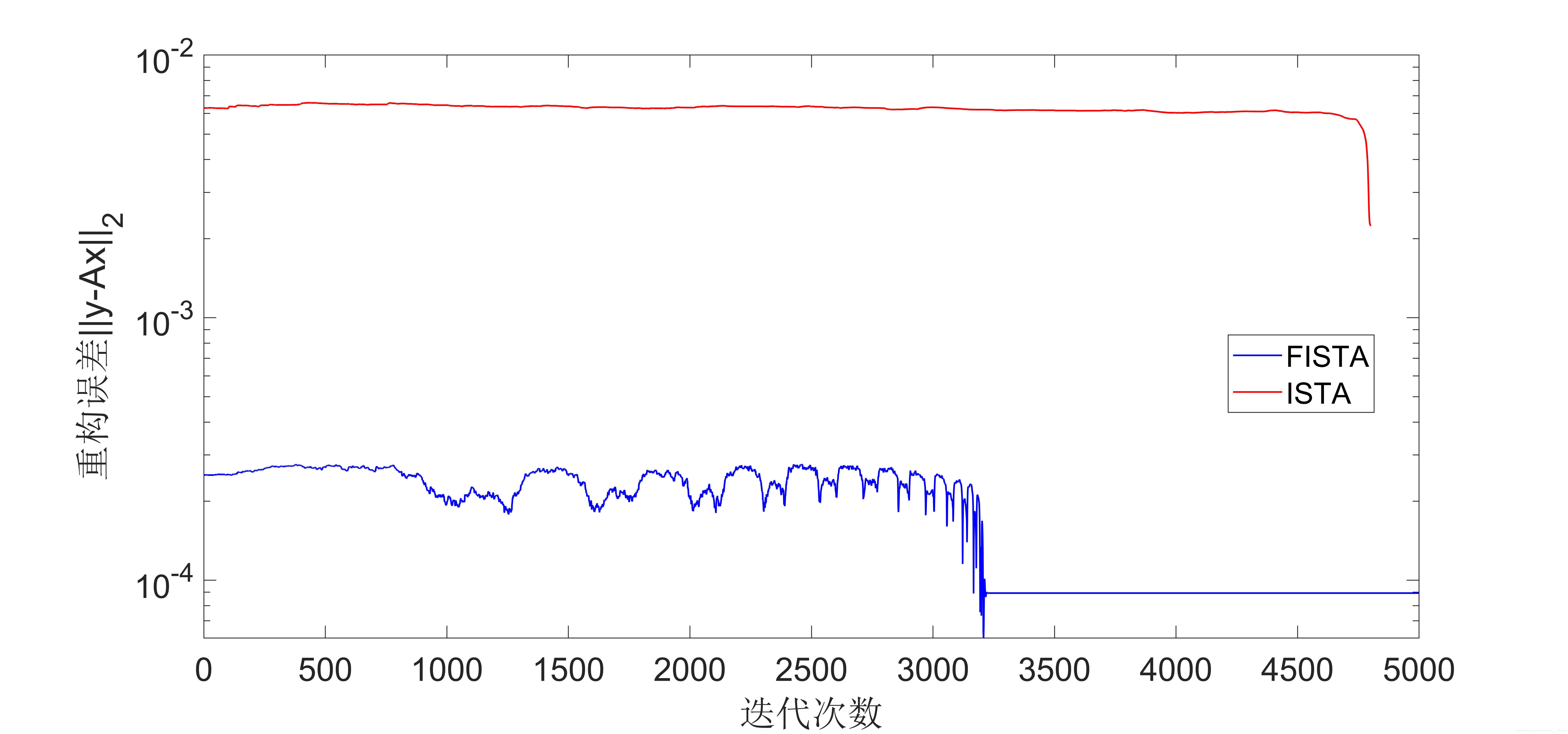
从实验结果可以看出,FIST算法收敛速度比ISTA算法要快很多。
这里顺便贴上原文中实验图,是关于图像去噪的:


图示为迭代次数与去噪效果的直观图,左边为FISTA算法,右边为ISTA算法,可以明显发现FISTA算法去噪速度较快。
5. 讨论
Iterative Shrinkage Thresholding 实际上不能称为一种算法,而是一类算法,ISTA算法和FISTA以及ISTA的改进算法如TWISTA算法等都是采用软阈值操作,求解的是 \({\ell _1}\) 范数正则化问题(LASSO),而还有一些算法是采用硬阈值操作的,这类算法称为迭代硬阈值类算法(Iterative Hard Thresholding),这类算法求解的问题是 \({\ell _0}\) 约束的最小化问题,是个非凸优化问题,以后有机会总结一下迭代硬阈值类算法。
参考文献
[1] Beck, Amir, and Marc Teboulle. "A fast iterative shrinkage-thresholding algorithm for linear inverse problems." SIAM journal on imaging sciences 2.1 (2009): 183-202.
[2] Yurii E Nesterov., Dokl, akad. nauk Sssr. " A method for solving the convex programming problem with convergence rate O (1/k^ 2)" 1983.
更多精彩内容请关注微信公众号 “优化与算法”

软阈值迭代算法(ISTA)和快速软阈值迭代算法(FISTA)的更多相关文章
- 【转】C语言快速幂取模算法小结
(转自:http://www.jb51.net/article/54947.htm) 本文实例汇总了C语言实现的快速幂取模算法,是比较常见的算法.分享给大家供大家参考之用.具体如下: 首先,所谓的快速 ...
- 【BZOJ1009】GT考试(KMP算法,矩阵快速幂,动态规划)
[BZOJ1009]GT考试(KMP算法,矩阵快速幂,动态规划) 题面 BZOJ 题解 看到这个题目 化简一下题意 长度为\(n\)的,由\(0-9\)组成的字符串中 不含串\(s\)的串的数量有几个 ...
- 快速傅立叶变换(FFT)算法
已知多项式f(x)=a0+a1x+a2x2+...+am-1xm-1, g(x)=b0+b1x+b2x2+...+bn-1xn-1.利用卷积的蛮力算法,得到h(x)=f(x)g(x),这一过程的时间复 ...
- 【HEVC帧间预测论文】P1.1 基于运动特征的HEVC快速帧间预测算法
基于运动特征的 HEVC 快速帧间预测算法/Fast Inter-Frame Prediction Algorithm for HEVC Based on Motion Features <HE ...
- SSE图像算法优化系列三十:GIMP中的Noise Reduction算法原理及快速实现。
GIMP源代码链接:https://gitlab.gnome.org/GNOME/gimp/-/archive/master/gimp-master.zip GEGL相关代码链接:https://gi ...
- 【智能算法】用模拟退火(SA, Simulated Annealing)算法解决旅行商问题 (TSP, Traveling Salesman Problem)
喜欢的话可以扫码关注我们的公众号哦,更多精彩尽在微信公众号[程序猿声] 文章声明 此文章部分资料和代码整合自网上,来源太多已经无法查明出处,如侵犯您的权利,请联系我删除. 01 什么是旅行商问题(TS ...
- Python <算法思想集结>之初窥基础算法
1. 前言 数据结构和算法是程序的 2 大基础结构,如果说数据是程序的汽油,算法则就是程序的发动机. 什么是数据结构? 指数据在计算机中的存储方式,数据的存储方式会影响到获取数据的便利性. 现实生活中 ...
- miller_rabin算法检测生成大素数的RSA算法实现
import math from functools import reduce #用于合并字符 from os import urandom #系统随机的字符 import binascii # ...
- 经典算法研究系列:二、Dijkstra 算法初探
July 二零一一年一月 本文主要参考:算法导论 第二版.维基百科. 一.Dijkstra 算法的介绍 Dijkstra 算法,又叫迪科斯彻算法(Dijkstra),算法解决的是有向图中单个源点到 ...
随机推荐
- Vue指令之`v-bind`的三种用法及v-on事件指令
v-bind:是 Vue中,提供的用于绑定属性的指令 1. 直接使用指令`v-bind` 2. 使用简化指令`:` 3. 在绑定的时候,拼接绑定内容:`:title="btnTitle + ...
- 前台.cshtml得到cookie值方法
function Cookie_() { $.ajax({ url: "/Login_/do_cookie",//请求地址 dataType: "json",/ ...
- Scyther-Compromise 协议形式化安全分析如何改进协议
1.最终的目的是如何将协议的不安全因素进行改进,提升安全性能.对协议中有关的加密和认证的过程进行形式化分析验证的时候通过添加敌手模型的(DY模型和eCK强安全模型),接受者和发送者之间的通信过程可能存 ...
- 交付Dubbo微服务到kubernetes集群
1.基础架构 1.1.架构图 Zookeeper是Dubbo微服务集群的注册中心 它的高可用机制和k8s的etcd集群一致 java编写,需要jdk环境 1.2.节点规划 主机名 角色 ip hdss ...
- linux修改MAC的方法
Linux修改MAC地址方法 Linux modifies MAC address method 1 ifconfig wlan0 down 2 ifconfig wlan0 hw ether MAC ...
- G1垃圾收集器角色划分与重要概念详解【纯理论】
继续接着上一次[https://www.cnblogs.com/webor2006/p/11129326.html]对G1进行理论化的学习,上一次学到了G1收集器的堆结构,回忆下: 接着继续对它进行了 ...
- 【经典/基础BFS+略微复杂的题意】PAT-L3-004. 肿瘤诊断
L3-004. 肿瘤诊断 在诊断肿瘤疾病时,计算肿瘤体积是很重要的一环.给定病灶扫描切片中标注出的疑似肿瘤区域,请你计算肿瘤的体积. 输入格式: 输入第一行给出4个正整数:M.N.L.T,其中M和N是 ...
- golang 时间的比较,time.Time的初始值?
参考: https://golangcode.com/checking-if-date-has-been-set/ https://stackoverflow.com/questions/209243 ...
- 在vue中使用css预编辑器
vue中使用less 安装less依赖,npm install less less-loader --save vue中使用sass npm install --save-dev sass-loade ...
- 云计算(7)---the scheduler of Hadoop
The scheduler of Hadoop Programming MapReduce 在有些情况下,reducer也可以先开始于Map.但为了便于理解,在这儿我们都是使reduce不会早于map ...