Netty源码之解码中两种数据积累器(Cumulator)的区别
上一篇随笔中已经介绍了解码核心工作流程,里面有个数据积累器的存在(Cumulator),其实解码中有两种Cumulator,那他们的区别是什么呢?
还是先打开ByteToMessageDecoder的channelRead();
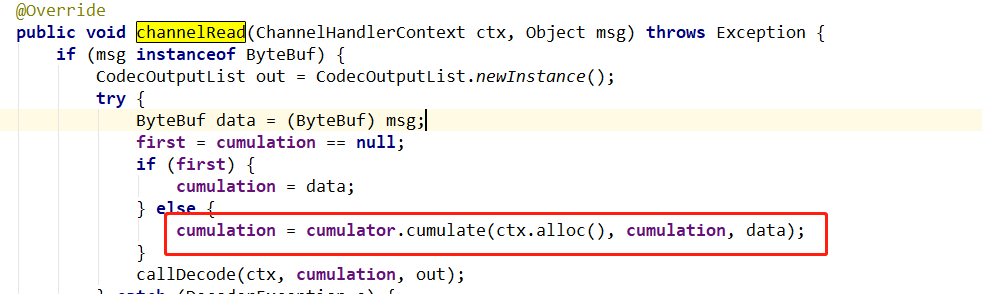
点进去查看cumulate()实现

又是一个抽象方法,看实现不难发现它有两种实现方式

两种实现分别为:MERGE_CUMULATOR(默认的):采用的是内存复制,先扩容空间,再追加数据
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
try {
final ByteBuf buffer;
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1 || cumulation.isReadOnly()) {
// Expand cumulation (by replace it) when either there is not more room in the buffer
// or if the refCnt is greater then 1 which may happen when the user use slice().retain() or
// duplicate().retain() or if its read-only.
//
// See:
// - https://github.com/netty/netty/issues/2327
// - https://github.com/netty/netty/issues/1764
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
buffer = cumulation;
}
buffer.writeBytes(in);
return buffer;
} finally {
// We must release in in all cases as otherwise it may produce a leak if writeBytes(...) throw
// for whatever release (for example because of OutOfMemoryError)
in.release();
}
}
};
第二种 :COMPOSITE_CUMULATOR :不是复制而是组合,先扩容,如果数据够了的话就直接把数据给组合起来,避免了内存复制
public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
try {
if (cumulation.refCnt() > 1) {
// Expand cumulation (by replace it) when the refCnt is greater then 1 which may happen when the
// user use slice().retain() or duplicate().retain().
//
// See:
// - https://github.com/netty/netty/issues/2327
// - https://github.com/netty/netty/issues/1764
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
buffer.writeBytes(in);
} else {
CompositeByteBuf composite;
if (cumulation instanceof CompositeByteBuf) {
composite = (CompositeByteBuf) cumulation;
} else {
composite = alloc.compositeBuffer(Integer.MAX_VALUE);
composite.addComponent(true, cumulation);
}
composite.addComponent(true, in);
in = null;
buffer = composite;
}
return buffer;
} finally {
if (in != null) {
// We must release if the ownership was not transferred as otherwise it may produce a leak if
// writeBytes(...) throw for whatever release (for example because of OutOfMemoryError).
in.release();
}
}
}
};
我只想做的更好,仅此而已
Netty源码之解码中两种数据积累器(Cumulator)的区别的更多相关文章
- Netty源码解读(四)-读写数据
读写Channel(READ)的创建和注册 在NioEventLoop#run中提到,当有IO事件时,会调用processSelectedKeys方法来处理. 当客户端连接服务端,会触发服务端的ACC ...
- 论MySQL数据库中两种数据引擎的差别
InnoDB和MyISAM是在使用MySQL最常用的两个表类型,各有优缺点,视具体应用而定. 基本的差别为: MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持. MyISAM类型的表强 ...
- 5. SOFAJRaft源码分析— RheaKV中如何存放数据?
概述 上一篇讲了RheaKV是如何进行初始化的,因为RheaKV主要是用来做KV存储的,RheaKV读写的是相当的复杂,一起写会篇幅太长,所以这一篇主要来讲一下RheaKV中如何存放数据. 我们这里使 ...
- netty源码分析之二:accept请求
我在前面说过了server的启动,差不多可以看到netty nio主要的东西包括了:nioEventLoop,nioMessageUnsafe,channelPipeline,channelHandl ...
- Netty 源码 ChannelHandler(四)编解码技术
Netty 源码 ChannelHandler(四)编解码技术 Netty 系列目录(https://www.cnblogs.com/binarylei/p/10117436.html) 一.拆包与粘 ...
- Netty 源码中对 Redis 协议的实现
原文地址: haifeiWu的博客 博客地址:www.hchstudio.cn 欢迎转载,转载请注明作者及出处,谢谢! 近期一直在做网络协议相关的工作,所以博客也就与之相关的比较多,今天楼主结合 Re ...
- netty源码解解析(4.0)-18 ChannelHandler: codec--编解码框架
编解码框架和一些常用的实现位于io.netty.handler.codec包中. 编解码框架包含两部分:Byte流和特定类型数据之间的编解码,也叫序列化和反序列化.不类型数据之间的转换. 下图是编解码 ...
- Netty源码分析第8章(高性能工具类FastThreadLocal和Recycler)---->第4节: recycler中获取对象
Netty源码分析第八章: 高性能工具类FastThreadLocal和Recycler 第四节: recycler中获取对象 这一小节剖析如何从对象回收站中获取对象: 我们回顾上一小节demo的ma ...
- 【转】netty源码分析之LengthFieldBasedFrameDecoder
原文:https://www.jianshu.com/p/a0a51fd79f62 拆包的原理 关于拆包原理的上一篇博文 netty源码分析之拆包器的奥秘 中已详细阐述,这里简单总结下:netty的拆 ...
随机推荐
- Codevs 2505 上学路线 (组合数学)
2505 上学路线 时间限制: 1 s 空间限制: 64000 KB 题目等级 : 钻石 Diamond 题目描述 Description 因为是学生,所以显然小A每天都要上学.小A所在的城市的道路构 ...
- noi 统计前k大的数
描述 给定一个数组,统计前k大的数并且把这k个数从大到小输出. 输入 第一行包含一个整数n,表示数组的大小.n < 100000. 第二行包含n个整数,表示数组的元素,整数之间以一个空格分开.每 ...
- 「SPOJ TTM 」To the moon「标记永久化」
题意 概括为主席树区间加区间询问 题解 记录一下标记永久化的方法.每个点存add和sum两个标记,表示这个区间整个加多少,区间和是多少(这个区间和不包括祖先结点区间加) 然后区间加的时候,给路上每结点 ...
- 【线性代数】3-4:方程组的完整解( $Ax=b$ )
title: [线性代数]3-4:方程组的完整解( Ax=bAx=bAx=b ) categories: Mathematic Linear Algebra keywords: Ax=b Specia ...
- codeforces1209E2 状压dp,枚举子集
题意 给一个n行m列的矩阵,每一列可以循环移位,问经过任意次移位后每一行的最大值总和最大为多少. 分析 每一行的最大值之和最大,可以理解为每一行任意选择一个数使它们的和最大. 设\(dp[i][S]\ ...
- MySQL 5.7半同步复制技术
一.复制架构衍生史 在谈这个特性之前,我们先来看看MySQL的复制架构衍生史. 在2000年,MySQL 3.23.15版本引入了Replication.Replication作为一种准实时同步方式, ...
- html,css,js实现的一个钟表
效果如图: 实现代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- godaddy SSL证书不信任
在使用网上教程的部署godaddy证书,会出现证书不受信任的情况. 各别审核比较严格的浏览器会阻止或者要求添加例外.情况如下: 利用在线证书测试工具会提示根证书的内容为空.从而导致证书不受信任. 解决 ...
- 在CSS中水平居中和垂直居中:完整的指南
这篇文章将会按照如下思路展开: 一.水平居中 1. 行内元素水平居中 2. block元素水平居中 3. 多个块级元素水平居中 二.垂直居中 1. 行内元素水平居中 2. block元素水平居中 3. ...
- [MyBatis]再次向MySql一张表插入一千万条数据 批量插入 用时5m24s
本例代码下载:https://files.cnblogs.com/files/xiandedanteng/InsertMillionComparison20191012.rar 环境依然和原来一样. ...