Spark组件
1,Application
application(应用)其实就是用spark-submit提交的程序。比方说spark examples中的计算pi的SparkPi。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储(比方说collect收集输出到console)。
2,Driver
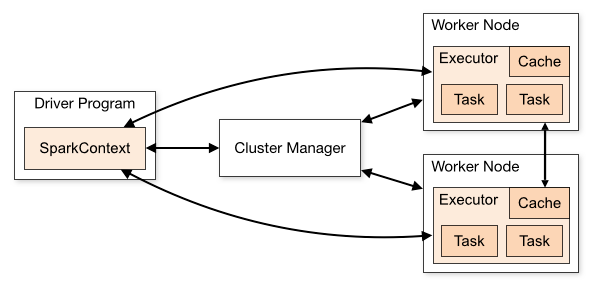
Spark中的driver感觉其实和yarn中Application Master的功能相类似。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster两种模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择集群中的一台机器启动driver。从spark官网截图的一张图可以大致了解driver的功能。
3,Job
Spark中的Job和MR中Job不一样不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等。
4, Task
Task是Spark中最新的执行单元。RDD一般是带有partitions的,每个partition的在一个executor上的执行可以任务是一个Task。
5, Stage
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点。从spark的论文中的两张截图,可以清楚的理解宽窄依赖以及stage的划分。
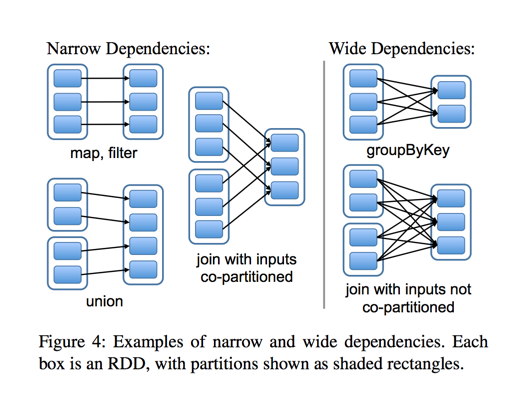
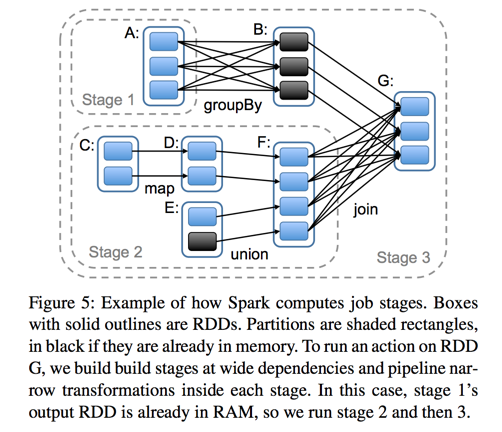
至于为什么这么划分,主要是宽窄依赖在容错恢复以及处理性能上的差异(宽依赖需要进行shuffer)导致的。
Spark组件的更多相关文章
- Spark组件间通信
1.Spark组件之间使用RPC机制进行通信.RPC的客户端在本地编写并调用业务接口,接口在本地通过RPC框架的动态代理机制生成一个对应的实现类,在这个实现类中完成soket通信.远程调用等功能的逻辑 ...
- 小记---------spark组件与其他组件的比较 spark/mapreduce ;spark sql/hive ; spark streaming/storm
Spark与Hadoop的对比 Scala是Spark的主要编程语言,但Spark还支持Java.Python.R作为编程语言 Hadoop的编程语言是Java
- spark组件笔记
SparkContext 中最重要的3个组建: 1 TaskScheduler (包含两个内容,TaskSchedulerImpl和SparkDeploySchedulerBackend)-用于向Ma ...
- Spark SQL | 目前Spark社区最活跃的组件之一
Spark SQL是一个用来处理结构化数据的Spark组件,前身是shark,但是shark过多的依赖于hive如采用hive的语法解析器.查询优化器等,制约了Spark各个组件之间的相互集成,因此S ...
- Spark——SparkContext简单分析
本篇文章就要根据源码分析SparkContext所做的一些事情,用过Spark的开发者都知道SparkContext是编写Spark程序用到的第一个类,足以说明SparkContext的重要性:这里先 ...
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- 平易近人、兼容并蓄——Spark SQL 1.3.0概览
自2013年3月面世以来,Spark SQL已经成为除Spark Core以外最大的Spark组件.除了接过Shark的接力棒,继续为Spark用户提供高性能的SQL on Hadoop解决方案之外, ...
- Hadoop与Spark比较
先看这篇文章:http://www.huochai.mobi/p/d/3967708/?share_tid=86bc0ba46c64&fmid=0 直接比较Hadoop和Spark有难度,因为 ...
随机推荐
- Sublime Text3自定义代码片段
1.打开工具--插件开发--新建代码片段 会出现下图: 2.在<![CDATA[和]]>内写下你要的代码片段,注意的是代码片段要靠最左边. 3.设置快捷键,把下面tabTrigger标签的 ...
- Servlet使用简介
Servlet的使用基本包含三个步骤: 1.继承HttpServlet 或实现Servlet 接口 (根据源码分析最终都是对servlet接口的实现) 2.配置地址: 配置web.xml 或者用注解的 ...
- Django连接mysql数据库
1.app中对应的models.py配置相关表结构信息 from django.db import models class Question(models.Model): question_text ...
- jmeter系列-------注意事项
1.自己创建的数据自己擅长,不要留垃圾数据 2.每个接口都需要增加断言,保证脚本的结果的正确性 3.相同的应用放在一个简单控制器下,所有的应用尽量放在一个线程组下面,将特殊场景单独抽离成一个线程组 4 ...
- FileDetector-基于java开发的照片整理工具
1. 项目背景 开发这个功能的主要原因如下: 1. 大学期间拍摄了约50G的照片,照片很多 2. 存放不规范,导致同一张照片出现在不同的文件夹内,可读性差,无法形成记忆线. 3. 重复存放过多,很多照 ...
- jq获取图片的原始尺寸,自适应布局
原理: each()遍历,width().height()获取宽高, load() 注意: 由于页面加载完了,但图片不一定加载完了,所以直接通过 $("img").width(), ...
- Struts2中Action接收参数的方法
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt112 Struts2中Action接收参数的方法主要有以下三种: 1.使用A ...
- 裸机LCD驱动配置
横屏4.3寸LCD为480*272(行:480个像素点 列:272个行) 1.1 LCD原理图 : Pin1:Von 电源正(这里由硬件自动控制) Pin2:VM/VDEN 数据使能 ...
- cocos2dx lua中异步加载网络图片,可用于显示微信头像
最近在做一个棋牌项目,脚本语言用的lua,登录需要使用微信登录,用户头像用微信账户的头像,微信接口返回的头像是一个url,那么遇到的一个问题就是如何在lua中异步加载这个头像,先在引擎源码里找了下可能 ...
- jQuery学习目录
前面的话 目前来说,jQuery可能已经不再处于人们的话题中心.人们讨论的更多的是Vue.Angular和React.但是,jQuery的使用量依然广泛,据统计,它仍然是目前使用率最高的javascr ...