快学Scala之特质
要点如下:
- Scala中类只能继承一个超类, 可以扩展任意数量的特质
- 特质可以要求实现它们的类具备特定的字段, 方法和超类
- 与Java接口不同, Scala特质可以提供方法和字段的实现
- 当将多个特质叠加使用的时候, 顺序很重要
1. Scala类没有多继承
如果只是把毫不相关的类组装在一起, 多继承不会出现问题, 不过像下面这个简单例子就能让问题就浮出水面了;
class Student {
val id: Int = 10
}
class Teacher {
val id: Int = 100
}
假设可以有:
class TeacherAssistant extends Student, Teacher { ... }
要求返回id时, 该返回哪一个呢?
菱形继承
 

对于 class A 中的字段, class D 从 B 和 C 都得到了一份, 这两个字段怎么得到和被构造呢?
C++ 中通过虚拟基类解决它, 这是个脆弱而复杂的解决方法, Java设计者对这些复杂性心生畏惧, 采取了强硬的限制措施, 类只能继承一个超类, 能实现任意数量的接口.
同样, Scala 中类只能继承一个超类, 可以扩展任意数量的特质,与Java接口相比, Scala 的特质可以有具体方法和抽象方法; Java 的抽象基类中也有具体方法和抽象方法, 不过如果子类需要多个抽象基类的方法时, Java 就做不到了(没法多继承), Scala 中类可以扩展任意数量的特质.
2. 带有特质的类
2.1 当做接口使用的特质
- Scala可以完全像Java接口一样工作, 你不需要将抽象方法声明为 abstract, 特质中未被实现的方法默认就是抽象方法;
- 类可以通过 extends 关键字继承特质, 如果需要的特质不止一个, 通过 with 关键字添加额外特质
- 重写特质的抽象方法时, 不需要 override 关键字
- 所有 Java 接口都可以当做 Scala 特质使用
比起Java接口, 特质和类更为相似
trait Logger {
def log(msg: String) // 抽象方法
}
class ConsoleLogger extends Logger with Serializable { // 使用extends
def log(msg: String): Unit = { // 不需要override关键字
println("ConsoleLogger: " + msg)
}
}
object LoggerTest extends App{
val logger = new ConsoleLogger
logger.log("hi")
}
/*输出
ConsoleLogger: hi
*/
2.2 带有具体实现的特质
trait Logger {
def log(msg: String) // 抽象方法
def printAny(k: Any) { // 具体方法
println("具体实现")
}
}
让特质混有具体行为有一个弊端. 当特质改变时, 所有混入该特质的类都必须重新编译.
2.3 继承类的特质
特质继承另一特质是一种常见的用法, 而特质继承类却不常见.
特质继承类, 这个类会自动成为所有混入该特质的超类
trait Logger extends Exception { }
class Mylogger extends Logger { } // Exception 自动成为 Mylogger 的超类
如果我们的类已经继承了另一个类怎么办?
没关系只要这个类是特质超类的子类就好了;
//IOException 是 Exception 的子类
class Mylogger extends IOException with Logger { }
不过如果我们的类继承了一个和特质超类不相关的类, 那么这个类就没法混入这个特质了.
3. 带有特质的对象
在构造单个对象时, 你可以为它添加特质;
特质可以将对象原本没有的方法与字段加入对象中
如果特质和对象改写了同一超类的方法, 则排在右边的先被执行.
// Feline 猫科动物
abstract class Feline {
def say()
}
trait Tiger extends Feline {
// 在特质中重写抽象方法, 需要在方法前添加 abstract override 2个关键字
abstract override def say() = println("嗷嗷嗷")
def king() = println("I'm king of here")
}
class Cat extends Feline {
override def say() = println("喵喵喵")
}
object Test extends App {
val feline = new Cat with Tiger
feline.say // Cat 和 Tiger 都与 say 方法, 调用时从右往左调用, 是 Tiger 在叫
feline.king // 可以看到即使没有 cat 中没有 king 方法, Tiger 特质也能将自己的方法混入 Cat 中
}
/*output
嗷嗷嗷
I'm king of here
*/
4. 特质的叠加
可以为类和对象添加多个相互调用的特质 时, 从最后一个开始调用. 这对于需要分阶段加工处理某个值的场景很有用.
下面展示一个char数组的例子, 展示混入的顺序很重要
定义一个抽象类CharBuffer, 提供两种方法
- put 在数组中加入字符
- get 从数组头部取出字符
abstract class CharBuffer {
def get: Char
def put(c: Char)
}
class Overlay extends CharBuffer{
val buf = new ArrayBuffer[Char]
override def get: Char = {
if (buf.length != 0) buf(0) else '@'
}
override def put(c: Char): Unit = {
buf.append(c)
}
}
定义两种对输入字符进行操作的特质:
- ToUpper 将输入字符变为大写
- ToLower 将输入字符变为小写
因为上面两个特质改变了原始队列类的行为而并非定义了全新的队列类, 所以这2种特质是可堆叠的,你可以选择它们混入类中,获得所需改动的全新的类。
trait ToUpper extends CharBuffer {
// 特质中重写抽象方法 abstract override
abstract override def put(c: Char) = super.put(c.toUpper)
// abstract override def put(c: Char): Unit = put(c.toUpper)
// java.lang.StackOverflowError, 由于put相当于 this.put, 在特质层级中一直调用自己, 死循环
}
trait ToLower extends CharBuffer {
abstract override def put(c: Char) = super.put(c.toLower)
}
特质中 super 的含义和类中 super 含义并不相同, 如果具有相同含义, 这里super.put调用时超类的 put 方法, 它是一个抽象方法, 则会报错, 下面会详细介绍 super.put 的含义
测试
object TestOverlay extends App {
val cb1 = new Overlay with ToLower with ToUpper
val cb2 = new Overlay with ToUpper with ToLower
cb1.put('A')
println(cb1.get)
cb2.put('a')
println(cb2.get)
}
/*output
a
A
*/
上面代码的一些说明:
上面的特质继承了超类charBuffer, 意味着这两个特质只能混入继承了charBuffer的类中
上面每一个
put方法都将修改过的消息传递给super.put, 对于特质来说, super.put 调用的是特质层级的下一个特质(下面说), 具体是哪一个根据特质添加的顺序来决定. 一般来说, 特质从最后一个开始被处理.在特质中,由于继承的是抽象类,super调用时非法的。这里必须使用abstract override 这两个关键字,在这里表示特质要求它们混入的对象(或者实现它们的类)具备 put 的具体实现, 这种定义仅在特质定义中使用。
混入的顺序很重要,越靠近右侧的特质越先起作用。当你调用带混入的类的方法时,最右侧特质的方法首先被调用。如果那个方法调用了super,它调用其左侧特质的方法,以此类推。
如果要控制具体哪个特质的方法被调用, 则可以在方括号中给出名称: super[超类].put(...), 这里给出的必须是直接超类型, 无法使用继承层级中更远的特质或者类; 不过在本例中不行, 由于两个特质的超类是抽象类, 没有具体方法, 编译器报错
5. 特质的构造顺序
特质也可以有构造器,由字段的初始化和其他特质体中的语句构成。这些语句在任何混入该特质的对象在构造时都会被执行。
构造器的执行顺序:
- 调用超类的构造器;
- 特质构造器在超类构造器之后、类构造器之前执行;
- 特质由左到右被构造;
- 每个特质当中,父特质先被构造;
- 如果多个特质共有一个父特质,父特质不会被重复构造
- 所有特质被构造完毕,子类被构造。
线性化细节
- 线性化是描述某个类型的所有超类型的一种技术规格;
- 构造器的顺序是线性化顺序的反向;
- 线性化给出了在特质中super被解析的顺序,
如果 C extends c1 with c2 with c3, 则:
lin(C) = C >> lin(c3) >> lin(c2) >> lin(c1)
这里>>意思是 "串接并去掉重复项, 右侧胜出"
下面例子中:
class Cat extends Animal with Furry with FourLegged
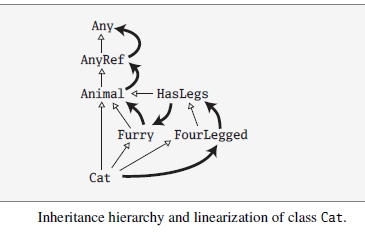
lin(Cat) = Cat>>lin(FourLegged)>>lin(Furry)>>lin(Animal)
= Cat>>(FourLegged>>HasLegs)>>(Furry>>Animal)>>(Animal)
= Cat>>FourLegged>>HasLegs>>Furry>>Animal
线性化给出了在特质中super被解析的顺序, 举例来说就是
FourLegged中调用super会执行HasLegs的方法
HasLegs中调用super会执行Furry的方法
例子
Scala 的线性化的主要属性可以用下面的例子演示:假设你有一个类 Cat,继承自超类 Animal 以及两个特质 Furry 和 FourLegged。 FourLegged 又扩展了另一个特质 HasLegs:
class Animal
trait Furry extends Animal
trait HasLegs extends Animal
trait FourLegged extends HasLegs
class Cat extends Animal with Furry with FourLegged
类 Cat 的继承层级和线性化次序展示在下图。继承次序使用传统的 UML 标注指明:白色箭头表明继承,箭头指向超类型。黑色箭头说明线性化次序,箭头指向 super 调用解决的方向。

6. 特质中的字段
特质中的字段可以是具体的也可以是抽象的. 如果给出了初始值那么字段就是具体的.
6.1 具体字段
trait Ability {
val run = "running" // 具体字段
def log(msg: String) = {}
}
class Cat extends Ability {
val name = "cat"
}
1.混入Ability特质的类自动获得一个run字段.
2.通常对于特质中每一个具体字段, 使用该特质的类都会获得一个字段与之对应.
3.这些字段不是被继承的, 他们只是简单的加到了子类中.任何通过这种方式被混入的字段都会自动成为该类自己的字段, 这是个细微的区别, 却很重要
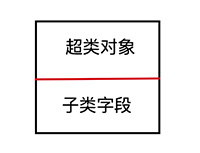 

JVM中, 一个类只能继承一个超类, 因此来自特质的字段不能以相同的方式继承. 由于这个限制, run 被直接加到Cat类中, 和name字段排在子类字段中.
6.2 初始化特质抽象字段
在类中初始化
特质中未被初始化的字段在具体的子类中必须被重写
trait Ability {
val swim: String // 具体字段
def ability(msg: String) = println(msg + swim) // 方法用了swim字段
}
class Cat extends Ability {
val swim = "swimming" // 不需要 override
}
这种提供特质参数的方式在零时构造某种对象很有利, 很灵活,按需定制.
创建对象时初始化
特质不能有构造器参数. 每个特质都有一个无参构造器. 值得一提的是, 缺少构造器参数是特质与类唯一不相同的技术差别. 除此之外, 特质可以具有类的所有特性, 比如具体的和抽象的字段, 以及超类.
这种局限对于那些需要定制才有用的特质来说会是一个问题, 这个问题具体就表现在一个带有特质的对象身上. 我们先来看下面的代码, 然后在分析一下, 就能一目了然了.
/**
* Created by wangbin on 2017/7/11.
*/
trait Fruit {
val name: String
// 由于是字段, 构造时就输出
val valPrint = println("valPrint: " + name)
// lazy 定义法, 由于是lazy字段, 第一次使用时输出
lazy val lazyPrint = println("lazyPrint: " + name)
// def 定义法, 方法, 每次调用时输出
def defPrint = println("defPrint: " + name)
}
object TestFruit extends App {
// 方法1. lazy定义法
println("** lazy定义法 构造输出 **")
val apple1 = new Fruit {
val name = "Apple"
}
println("\n** lazy定义法 调用输出 **")
apple1.lazyPrint
apple1.defPrint
// 方法2. 提前定义法
println("\n** 提前定义法 构造输出 **")
val apple2= new {
val name = "Apple"
} with Fruit
println("\n** 提前定义法 调用输出 **")
apple2.lazyPrint
apple2.defPrint
}
/*
** lazy定义法 构造输出 **
valPrint: null
** lazy定义法 调用输出 **
lazyPrint: Apple
defPrint: Apple
** 提前定义法 构造输出 **
valPrint: Apple
** 提前定义法 调用输出 **
lazyPrint: Apple
defPrint: Apple
*/
为了便于观察, 先把输出整理成表格
| 方法 | valPrint | lazyPrint | defPrint |
|---|---|---|---|
| lazy定义法 | null | Apple | Apple |
| 提前定义法 | Apple | Apple | Apple |
我们先来看一下 lazy定义法 和 提前定义法 的构造输出, 即 valPrint, lazy定义法输出为 null, 提前定义法输出为 "Apple"; 问题出在构造顺序上, Fruit 构造器(特质的构造顺序)先与子类构造器执行. 这里的子类并不那么明显, new 语句构造的其实是一个 Fruit 的匿名子类的实例. 也就是说 Fruit 先初始化, 子类的 name 还没来得及初始化, Fruit 的 valPrint 在构造时就立即求值了, 所以输出为 null.
由于lazy值每次使用都会检查是否已经初始化, 用起来并不是那么高效.
关于 val, lazy val, def 的关系可以看看 lazy
特质背后的实现: Scala通过将 trait 翻译成 JVM 的类和接口 , 关于通过反编译的方式查看 Scala 特质的背后工作方式可以参照 Scala 令人着迷的类设计中介绍的方法, 有兴趣的可以看看.
参考:
- 特质与特质线性化 Jason Ding
快学Scala之特质的更多相关文章
- 快学Scala 第十九课 (trait的abstract override使用)
trait的abstract override使用: 当我看到abstract override介绍的时候也是一脸懵逼,因为快学scala,只介绍了因为TimestampLogger中调用的super ...
- 快学Scala习题解答—第一章 基础
1 简介 近期对Scala比较感兴趣,买了本<快学Scala>,感觉不错.比<Programming Scala:Tackle Multi-Core Complexity on th ...
- 《快学Scala》
Robert Peng's Blog - https://mr-dai.github.io/ <快学Scala>Intro与第1章 - https://mr-dai.github.io/S ...
- [Scala] 快学Scala A2L2
集合 13.1 集合的三大类 所有的集合都扩展Iterable特质.集合的三大集合为Seq, Set, Map Seq是一个有先后次序的值的序列,比如数组或列表.IndexSeq允许我们通过整型下表快 ...
- 快学Scala习题解答—第十章 特质
10 特质 10.1 java.awt.Rectangle类有两个非常实用的方法translate和grow,但可惜的是像java.awt.geom.Ellipse2D这种类没有. 在Scala中,你 ...
- [Scala] 快学Scala A1L1
基础 1.1 声明值和变量 在Scala中,鼓励使用val; 不需要给出值或变量的类型,这个信息可以从初始化表达式推断出来.在必要的时候,可以指定类型. 在Scala中,仅当同一行代码中存在多条语句时 ...
- 快学scala
scala 1. scala的由来 scala是一门多范式的编程语言,一种类似java的编程语言[2] ,设计初衷是要集成面向对象编程和函数式编程的各种特性. java和c++的进化速度已经大不如 ...
- 快学Scala 第6章 对象 - 练习
1. 编写一个Conversions对象,加入inchesToCentimeters.gallonsToLiters和milesToKilometers方法. object Conversions { ...
- 快学Scala 2
控制结构和函数 1.在Scala中,几乎所有构造出来的语法结构都有值.这个特性是为了使得程序更加精简,也更易读. (1)if表达式有值 (2)块也有值——是它最后一个表达式的值 (3)Scala的fo ...
随机推荐
- php回调函数的使用
1.array_map — 将回调函数作用到给定数组的单元上 参数:array array_map ( callable $callback , array $arr1 [, array $... ] ...
- 建造者模式—设计角度重温DNF中的角色
应用场景 假设现在我们要设计DNF中的人物角色(鬼剑士.神枪手.魔法师.圣骑士.格斗家).然而,利用面对对象的思想,必须先从实体入手,每一个角色都包含各种装备.武器.配饰,这些就当做要建造的零件,然后 ...
- PropertyGrid自定义控件
PropertyGrid是一个很强大的控件,使用该控件做属性设置面板的一个好处就是你只需要专注于代码而无需关注UI的呈现,PropertyGrid会默认根据变量类型选择合适的控件显示.但是这也带来了一 ...
- 有趣而又被忽略的Unity技巧
0x00 前言 本文的内容主要来自YouTube播主Brackeys的视频TOP 10 UNITY TIPS 和TOP 10 UNITY TIPS #2.在此基础上经过自己的实践和筛选之后,选择了几个 ...
- java基础(五章)
一. 调试 步骤1:设置断点(不能在空白处设置断点) 步骤2:启动调试 步骤3:调试代码(F6单步跳过)笔记本Fn+F6(F5) 步骤4:结束调试 掌握调试的好处? l 很清晰的看到, ...
- lucene全文搜索之三:生成索引字段,创建索引文档(给索引字段加权)基于lucene5.5.3
前言:上一章中我们已经实现了索引器的创建,但是我们没有索引文档,本章将会讲解如何生成字段.创建索引文档,给字段加权以及保存文档到索引器目录 luncene5.5.3集合jar包下载地址:http:// ...
- IntelliJ IDEA提示:Error during artifact deployment. See server log for details.
IntelliJ IDEA-2017.1.1 tomcat-8.5.13 问题:在IntelliJ IDEA中使用tomcat部署web app时,提示:Error during artifact ...
- EOS数据源的配置
EOS产品默认安装完成后的数据源为default,由于业务需要,会配置多数据源,这就有了以下的随笔: 1.在governor里面新增数据源 2.逻辑流中,数据源默认为default,根据需要改为自己新 ...
- docker 汇总
整理中 ... 一. docker 基础 配置参数最佳实践 二. docker 编排工具 docker swarm mesos kubernetes AWS ECS 三. docker 生态 dock ...
- 点击页面其它地方隐藏该div的方法
思路一 第一种思路分两步 第一步:对document的click事件绑定事件处理程序,使其隐藏该div 第二步:对div的click事件绑定事件处理程序,阻止事件冒泡,防止其冒泡到document,而 ...