搭建Hadoop平台(新手入门)
刚刚大学毕业,接触大数据有一年的时间了,把自己的一些学习笔记分享给大家,希望同热爱大数据的伙伴们一起学习,成长!
资料准备:
Hadoop-2.7.1下载:http://pan.baidu.com/s/1o7LKaSU 密码:64du
Jdk下载(文中使用1.7,这里给得1.8,不影响使用):http://pan.baidu.com/s/1kVEEJ91 密码:r22t
安装步骤:
0.关闭防火墙
执行:service iptables stop 这个指令关闭完防火墙后,如果重启,防火墙会重新建立,所以,如果想重启后防火墙还关闭,需额外执行:chkconfig iptables off
1.配置主机名
执行: vim /etc/sysconfig/network
编辑主机名
注意:主机名里不能有下滑线,或者特殊字符#$,不然会找不到主机导致无法启动
这种方式更改主机名需要重启才能永久生效,因为主机名属于内核参数。
如果不想重启,可以执行:hostname hadoop01。但是这种更改是临时的,重启后会恢复 原主机名。
所以可以结合使用。先修改配置文件,然后执行:hostname hadoop01 。可以达到不重启或重启都是主机名都是同一个的目的

2.配置hosts文件
执行:vim /etc/hosts(192.168.161.41是我自己机器的ip,这里必须写入自己本机的ip)

3.配置免秘钥登录
在hadoop01节点执行(执行过hostname hadoop01):
执行:ssh-keygen
然后一直回车,直到出现类似的图形:
生成节点的公钥和私钥,生成的文件会自动放在/root/.ssh目录下
然后把公钥发往远程机器,比如hadoop01向hadoop02发送
执行:ssh-copy-id root@hadoop01
此时,hadoop02节点就是把收到的hadoop秘钥保存在
/root/.ssh/authorized_keys 这个文件里,这个文件相当于访问白名单,凡是在此白明白存储的 秘钥对应的机器,登录时都是免密码登录的。
当hadoop01再次通过ssh远程登录hadoop02时,发现不需要输入密码了。

在hadoop02节点执行上述上述步骤,让hadoop02节点连接hadoop01免密码登录
4.配置自己节点登录的免密码登录
如果是单机的伪分布式环境,节点需要登录自己节点,即hadoop01要登录hadoop01
但是此时是需要输入密码的,所以要在hadoop01节点上
执行:ssh-copy-id root@hadoop01(上面已经给出)
5.安装和配置jdk
1)安装jdk
mkdir /usr/local/src/java
rz 上传jdk tar包
tar -xvf jdk-7u51-linux-x64.tar.gz
配置环境变量
1:vi /etc/profile
2:在尾行添加
#set java environment
JAVA_HOME=/usr/local/src/java/jdk1.7.0_51
JAVA_BIN=/usr/local/src/java/jdk1.7.0_51/bin
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
保存退出
3:source /etc/profile 使更改的配置立即生效
4:java -version 查看JDK版本信息。如显示1.7.0证明成功。
执行: vi /etc/profile
2)在尾行添加
#set java environment
JAVA_HOME=/usr/local/src/java/jdk1.7.0_51
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOMEPATH CLASSPATH
保存退出
3)source /etc/profile 使更改的配置立即生效
4)java -version 查看JDK版本信息。如显示1.7.0证明成功。
6.上传和解压hadoop安装包
执行:tar -xvf hadoop……(包名)
目录说明:
bin目录:命令脚本
etc/hadoop:存放hadoop的配置文件
lib目录:hadoop运行的依赖jar包
sbin目录:启动和关闭hadoop等命令都在这里
libexec目录:存放的也是hadoop命令,但一般不常用
最常用的就是bin和etc目录
7.配置hadoop-env.sh
这个文件里写的是hadoop的环境变量,主要修改hadoop的java_home路径
切换到 etc/hadoop(cd etc/hadoop)目录
执行:vim hadoop-env.sh
修改java_home路径和hadoop_conf_dir 路径(自己本机的安装目录)
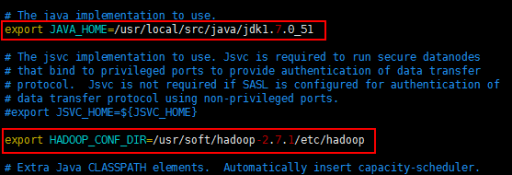
然后执行:source hadoop-env.sh 让配置立即生效
8.修改core-site.xml
在 etc/hadoop 目录下
执行:vim core-site.xml
配置如下:
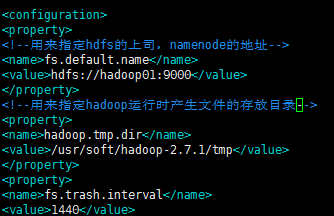
<configuration>
<!--用来指定hdfs的上司,namenode的地址-->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000<value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/soft/hadoop-2.7.1/tmp</value>
</property>
</configuration>
9.修改vim hdfs-site .xml
配置如下:
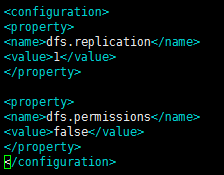
<configuration>
<!--指定hdfs保存数据副本的数量,包括自己,默认值是3-->
<!--如果是伪分布模式,此值是1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置 hdfs 的操作权限, false 表示任何用户都可以在 hdfs 上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
10.修改vim mapred-site.xml
这个文件初始时是没有的,有的是模板文件,mapred-site.xml.template
所以需要拷贝一份,并重命名为mapred-site.xml
执行:cp mapred-site.xml.template mapred-site.xml
配置如下:
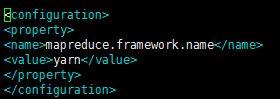
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn是资源协调工具,
11.修改vim yarn-site.xml
配置如下:

<configuration>
<!--Site specific YARN configuration properties -->
<property>
<!--指定yarn的老大resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
12.配置vim slaves文件

13.配置hadoop的环境变量
配置代码:vim /etc/profile

HADOOP_HOME=/usr/soft/hadoop-2.7.1JAVA_HOME=/usr/local/src/java/jdk1.7.0_51
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
14.格式化namenode
为什么要格式化?
执行:hadoop namenode -format
如果不好使,可以重启linux
当出现:successfully,证明格式化成功

15.启动Hadoop
cd hadoop-2.7.1/sbin (进入hadoop安装目录后执行)
./start-dfs.sh或者sh start-dfs.sh
16.停止Hadoop
./stop-dfs.sh 或者sh stop-dfs.sh
注:如果在启动时,报错:Cannot find configuration directory: /etc/hadoop
解决办法:
编辑etc/hadoop下的hadoop-env.sh 文件,添加如下配置信息:

export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
然后执行source hadoop-env.sh 使配置立即生效
执行:start-yarn.sh 启动yarn相关的服务
在浏览器访问:
192.168.161.41:50070 来访问 hadoop 的管理页面(必须是自己本机的ip)
大家若感兴趣,转载本文,请注明出处
搭建Hadoop平台(新手入门)的更多相关文章
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 大数据Hadoop学习之搭建Hadoop平台(2.1)
关于大数据,一看就懂,一懂就懵. 一.简介 Hadoop的平台搭建,设置为三种搭建方式,第一种是"单节点安装",这种安装方式最为简单,但是并没有展示出Hadoop的技术优势,适合 ...
- Windows 10 搭建Hadoop平台
一.环境配置 JDK:1.8. Hadoop下载地址(我选择的是2.7.6版本):https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ ...
- ubuntu下搭建hadoop平台
终于把单击模式跟伪分布式模式搭建起来了,记录于此. 1.SSH无密码验证配置 因为伪分布模式下DataNode和NameNode均是本身,所以必须配置SSH localhost的无密码验证. 第一步, ...
- 使用ambari搭建Hadoop平台
1.操作系统 CentoOS Server with GUI(有GUI,有浏览器*ambari基于浏览器*推荐latest stable version)2.分区 默认 + /hadoop3.网络设置 ...
- hadoop平台搭建
前言 这是小的第一次搭建hadoop平台,写下这篇博客有以下几个目的(ps:本博只记录在linux系统下搭建hadoop的步骤,如果需要了解在其他平台上搭建hadoop的步骤,还请移步): 1.希望大 ...
- 安卓自动化测试(2)Robotium环境搭建与新手入门教程
Robotium环境搭建与新手入门教程 准备工具:Robotium资料下载 知识准备: java基础知识,如基本的数据结构.语法结构.类.继承等 对Android系统较为熟悉,了解四大组件,会编写简单 ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- 高可用Hadoop平台-HBase集群搭建
1.概述 今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示: 基础软件的准备 HBase介绍 HBase集群搭建 单点问题验证 截 ...
随机推荐
- 201521123082 《Java程序设计》第10周学习总结
201521123082 <Java程序设计>第10周学习总结 标签(空格分隔): java 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. A ...
- Java学习6——基本数据类型及其转换
Java常量: Java的常量值用字符串表示,区分不同的数据类型 整型常量123.浮点型常量3.14.字符常量'a'.逻辑常量true.字符串常量"helloworld". ps: ...
- 201521123032 《Java程序设计》第8周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 2. 书面作业 本次作业题集集合 1.List中指定元素的删除(题目4-1) 1.1 实验总结 在课堂上在老师 ...
- 201521044091 java 第一周总结
1.本周学习总结 (1)第一次开始接触java语言,有些用法还是和c和c++有点差异,需要不断去学习 (2)java其实不仅仅一种高级语言,它包括的还有它的整套体系. 2. 书面作业 1.为什么jav ...
- Linux如何设置dns
首先打开dns设置文档 空的dns文档如图所示 键入图片中的文本保存即可设置了自己的dns 保存后推出即可.
- 201521123080《Java程序设计》第11周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 多线程: 操作系统有两个容易混淆的概念,进程和线程. 进程:一个计算机程序的运行实例,包含了需要执行的指令:有自己 ...
- Java程序设计——学生基本信息管理系统
1.团队课程设计博客链接 http://www.cnblogs.com/handsome321/p/7067121.html 2.个人负责模块说明 本组课题:学生信息管理系统 本人任务:插入.删除学生 ...
- chrome保存网页为单个文件(mht格式)
网页归档(英语:MIME HTML或MIME Encapsulation of Aggregate HTML Documents,又称单一文件网页或网页封存盘案)为以多用途互联网邮件扩展格式,将一个多 ...
- 关于args的一个小bug
我在开始学习Java的时候就有点疑惑,到底main方法中的args到底是什么?经过我的一些思考,然后结合代码写一点自己的看法. 下面来看一段代码: /** * @author 薛定谔的猫 * 关于ar ...
- Python内置函数详解
置顶 内置函数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii https://docs.pyth ...