URL加载页面的过程
总体过程:
1、DNS解析
2、TCP连接
3、发送HTTP请求
4、服务器处理请求并返回HTTP报文
5、浏览器解析渲染页面
6、连接结束
一、DNS解析
在互联网中,每一台机计算机的唯一 标识是他的IP地址,由于IP地址难以记忆,因此便有了与其相对应的网址,便于用户搜索网站。于是,DNS解析就是将网址(即域名)解析为IP地址的过程,具体如下(盗)图:
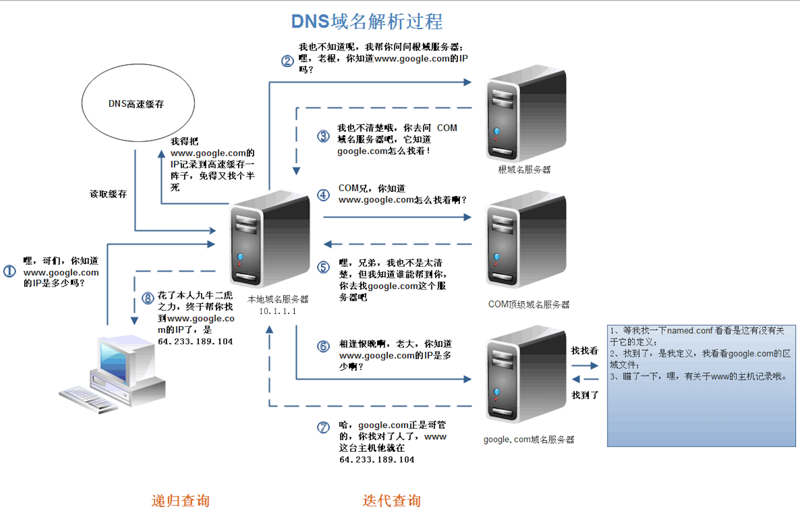
讲解一波:
突然计算机中浏览器中有人输入了www.google.com;
1、浏览器问本地域名服务器,你有没有www.google.com的IP地址呢?(没有);
2、本地域名服务器去问根域名服务器,你有没有www.google.com的IP地址呢?;
3、根域名返回答案:我没有诶!;
4、本地域名服务器得到答案后,就再去问COM顶级域名服务器,你有没呢?;
5、顶级域名服务器也返回答案说:我也没有呢!不过你可以去找一下google.com;
6、本地域名服务器又去问了最终boss(google.com);
7.google.com说我有www.google.com的IP地址呢!于是将IP地址返回给本地域名服务器;
8、本地域名服务器终于拿到了IP地址,于是将IP地址告诉给了浏览器;
以上过程为最原始的DNS域名解析过程,可见复杂与繁琐程度,在现代用户量与请求数以百万级别计算的互联网时代,倘若每次访问都需要进行这些步骤,显然是不科学的。
于是,DNS缓存出现了。
上图可见,DNS缓存在较近距离的服务器或者浏览器中,则第二次查询的过程与时间便缩短很多。
DNS缓存,根据距离远近分别为:浏览器缓存、系统缓存、路由器缓存、IPS服务器缓存、根域名服务器缓存、顶级域名服务器缓存、主域名服务器缓存。
关于访问页面过程的优化还有一项:DNS负载均衡。
DNS负载均衡,又称DNS重定向;是一种以空间换时间的技术。
具体实现为:
倘若用户访问的IP地址不变,都在某一台服务器上,那该服务器所需要承受的性能要求便非常高。因此,作为用户,它只需要得到对应的IP地址和请求内容就可以,并不会在乎是哪台服务器提供的。
其中CDN(content delivery network)内容分发网络,就是一门DNS重定向技术,为用户响应最近的服务器需要的IP地址和请求内容。这样将会大量提高用户访问速度。(空间交换时间)。
二、TCP连接
TCP/IP协议簇共有四层,分别对应如下:
应用层 : HTTP、FTP、DNS、SMTP等
传输层:TCP、UDP等
网络层:IP、ARP等
数据链路层:802.11、WIFI等
TCP的连接与断开过程,共需要发7个包才能实现,成为“三次握手,四次挥手”,如下:
第一次握手:客户端发送带SYN标志的数据报;(SYN请求连接)
第二次握手:服务端发送回带SYN/ACK标志的数据报;(ACK确认应答,SYN请求连接)
第三次握手:客户端发送带ACK标志的数据报;(ACK确认应答)
连接成功。
第一次挥手:客户端发送带FIN标志的数据报;(FIN请求切开连接)
第二次挥手:服务端发送带ACK标志的数据报;(ACK确认应答)
第三次挥手:服务端发送带FIN标志的数据报;(FIN请求切开连接)
第四次挥手:客户端发送带ACK标志的数据报;(ACK确认应答)
三、发送HTTP请求
HTTP请求是基于TCP连接上的,也就是说只有建立起了TCP连接之后才能进行HTTP请求。
HTTP报文的总体如下图:
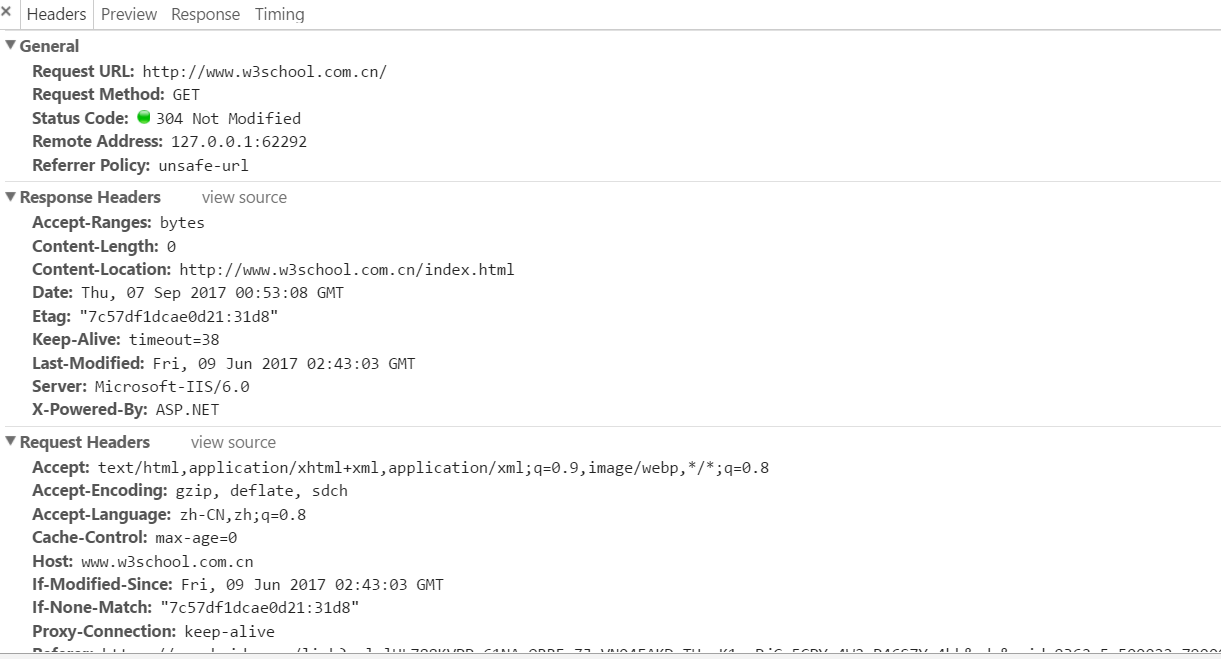
以上部分是一个完整的HTTP请求。
第一部分是综合体(General),第二部分是HTTP发送的请求,第三部分是HTTP的响应。(具体细节后面再述)。
关于HTTP请求和响应的组成分别为:
请求:请求行、请求头、请求体;
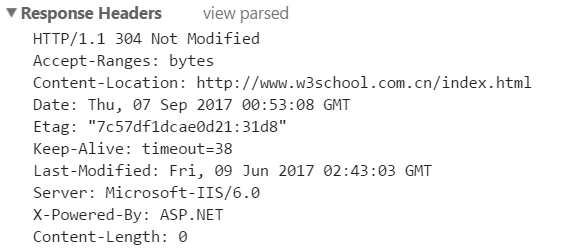
请求行:HTTP/1.1 304 Not modified;
请求头:Accept-Ranges:bytes;
.........
Content-Length:0;
请求体:发送的数据(当请求为GET时,请求体为空)
响应:响应行、响应头、响应体;

响应与请求类似,不过多阐述。
HTTP/1.1请求方法总结:
GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT;
GET请求:GET方法是默认的HTTP其你去,请求已被URI识别的资源。指定资源经服务器端解析后返回响应内容。GET请求可以再URL上明文传参,但是安全性不高,当然也可以不带参数。当用来提交表单数据时,很容易被辨认出表单数据。
POST请求:用来传输实体的主体。而GET方法一般用来获取响应的主体内容。因此作为传输方法,POST请求克服了GET请求在传输实体的一些缺点。
GET请求与POST请求的区别比较:
1)服务器端安全方面。GET请求用于信息获取,它不存在传输实体,因此对于修改方面或者数据库方面是安全的。而POST请求的实质是修改服务器上资源的请求,相对来说容易被利用进行一些流氓操作。
2)传输信息方面。GET请求将数据信息附在URL上面明文传输,而POST请求将传输的信息放在HTTP报文中,在信息安全性方面,POST请求比GET请求更好。
3)数据大小方面。GET请求传输的数据量限制一般为2KB左右,原因:GET请求通过URL传输数据,URL对于数据是没有限制的,但是不同浏览器对于URL的大小是存在限制的,所以一般来说是2KB。POST 请求对于数据是不存在限制的,唯一可能限制的原因是服务器端处理数据的能力。
HEAD请求:与GET请求类似,不过不返回报文的主体信息。
具体作用:判断类型;查看状态码;判断资源是否修改;检查超链接的有效性;
PUT请求:修改服务器端指定资源,一般用户上传文件,但由于该方法在HTTP/1.1自身不带验证机制,所以无法保证安全性,因此一般不使用。
DELETE请求:与PUT请求相反,请求修改服务器上的指定资源;
OPTIONS请求:获取服务器端支持的HTTP请求方法;用途:获取HTTP请求方法(黑客常用);检查服务器性能(未深入);
TRACE请求和CONNECT请求(暂时不了解过多);
HTTP状态码:
1XX:提示信息类,表示请求被成功接收,继续处理;
2XX:请求成功类,表示请求被成功接收,理解,接受;
3XX:重定向类,要完成请求必须进行更进一步的处理;
4XX:客户端错误类,请求有语法错误或请求无法处理;
5XX:服务端错误类,服务器未能实现合法的请求;
常见状态码:
200:请求被成功完成,资源已返回到客户端。
301:重定向,客户请求的文档在其他地方,表示永久性转移。
302:重定向,客户请求的文档在其他地方,表示暂时性转移。
304:自从上次请求后,请求的网页从未修改过。即浏览器获取缓存即可(详细见前端缓存篇)
400:请求出现语法错误。
401:客户试图未经授权访问受密码保护的页面。(即未授权)
403:资源不可用,禁止访问。
404:无法找到指定位置的资源。
405:请求方法对指定资源不适用。
500:常见的服务器端错误。
503:服务器暂时无法处理请求(可能维护或过载)
301和302区别:
两者都表示地址的重定向。也就是当浏览器得到服务器返回的这两种状态码,就会进行从旧地址跳转到一个新的地址,新的地址可以从响应的Location的首部得到。
区别:301表示资源被永远地在旧地址移除,搜索引擎会进行新旧地址的交换。302表示资源暂时从旧地址迁出去,过段时间会回来,搜索引擎还会保留旧地址。
一般出现重定向的情况:网站目录调整;网站地址更改;网页扩展名更改。如果没有重定向,会返回404,导致用户流量浪费。
尽量少用302重定向,易发生网址劫持。
所谓网址劫持:A网站拥有简洁友好的url,但是B网站的url非常长且混乱,如果A网站重定向到B网站,对于搜索引擎算法来说,它依旧可能将网址显示为A网站,便于用户,此时的情况就是:浏览器中是A网站的网址,但是页面内容为B网站的。此时,B网站Url就不能被抓取了,也就是发生了URL的劫持。
URI和URL的区别:
URI:统一资源标识符,表示网络资源。
URL:统一资源定位符,表示网络资源的地址,即网址。
RFC:征求修正意见书,RFC是互联网设计文档。倘若不按照RFC标准执行,可能导致无法通信的情况。(暂未深入)
HTTP:无状态协议,对请求和响应不做持久化处理。
无状态:协议对于事务处理没有记忆能力。通俗点,当浏览器发送请求给服务器,服务器响应,当浏览器再次发送请求给服务器时,服务器不会知道你是上次的浏览器,或者说,服务器不会记住浏览器。
TCP协议和UDP协议都属于TCP/IP协议簇。
TCP:面向连接,可靠的连接;UDP:非连接,尽可能交付,不可靠连接;
HTTP和HTTPs区别:
HTTP:超文本传输协议,应用层的协议。
缺点:
1、通信内容为明文,未加密,内容可能被窃听。
2、通信双方的身份未进行验证,可能出现伪装身份的情况。(例如DOS攻击)
3、接受的报文的完整性无法保证,中途可能被篡改。
鉴于HTTP的缺点,HTTPS在HTTP的基础上增加了:
1、通信加密; 2、证书认证; 3、完整性保护
SSL是如何配合HTTP进行通信加密的:
HTTPS并非一个新的协议,可以说是:HTTPS = HTTP +SSL;

由图可见,SSL协议独立于HTTP协议,也可以用于其他协议的加密。如 SMTP等。
目前,百度搜索引擎对于HTTPS的抓取还不是很支持,但是谷歌是支持的。
HTTPS会降低通信效率:
1、通信速率降低,加多了一层SSL协议的通信过程。
2、加密过程消耗资源。
3、证书开销,需要向认证机构购买证书。
URL加载页面的过程的更多相关文章
- 从输入 URL 到页面加载完成的过程中都发生了什么事情?
这个问题是老生常谈的问题啦,虽然说到处百度都有的答案,还是希望自己能总结一下. 如今有很多答案,都是从硬件开始讲起,比如键盘的响应或者触屏的响应,然后CPU处理到OS的内核等等.这里不作为重点来讲,要 ...
- 从输入 URL 到页面加载完成的过程中都发生了什么
从输入 URL 到页面加载完成的过程中都发生了什么 过程描述 浏览器查找域名对应的 IP 地址: 浏览器根据 IP 地址与服务器建立 socket 连接: 浏览器与服务器通信: 浏览器请求,服务器处理 ...
- 从输入 URL 到页面加载完成的过程详解---【XUEBIG】
从输入 URL 到页面加载完成的过程中都发生了什么事情? 这是一道经典的面试题,涉及面非常广,要答出来并不困难,当要将问题回答好却不是那么容易 过程概述 浏览器查找域名对应的 IP 地址: 浏览器根据 ...
- 【转】 从输入 URL 到页面加载完成的过程中都发生了什么事情?
该问题总结 一. 往浏览器输入URL后给你一个页面,你天天在使用的东西,学过计算机网络的知道是怎么回事,就DNS解析然后页面的回馈,不过要讲好还是有难度. 之前fex团队的nwind专门写过这个问题的 ...
- Web访问原理-从输入URL到页面加载完成的过程中都发生了什么事情?
从输入URL到页面加载完成的过程中都发生了什么事情?--这是一个经典的面试题: 主要是关于计算机网络方面的知识基础,对于非科班计算机自学web开发的同学可能理解起来就很困难. StackOverFlo ...
- ExtJs非Iframe框架加载页面实现
在用Ext开发App应用时,一般的框架都是左边为菜单栏,中间为tab页方式的显示区域.而tab页面大多采用的嵌入一个iframe来显示内容.但是采用iframe方式有一个很大的弊端就是每次在加载一个新 ...
- 小程序wx.previewImage查看图片再次点击返回时重新加载页面问题
wx.previewImage预览图片这个过程到底发生了什么? 首先我们点击图片预览,附上查看图片代码: <image class="headImg" data-src=&q ...
- jquery mobile 和phonegap开发总结之三跨域加载页面
跨域加载 一要进行一定的配置见下面 $( document ).bind( "mobileinit", function() { // Make your jQuery Mobil ...
- 爬虫再探实战(三)———爬取动态加载页面——selenium
自学python爬虫也快半年了,在目前看来,我面临着三个待解决的爬虫技术方面的问题:动态加载,多线程并发抓取,模拟登陆.目前正在不断学习相关知识.下面简单写一下用selenium处理动态加载页面相关的 ...
随机推荐
- websocket(三) 进阶!netty框架实现websocket达到高并发
引言: 在前面两篇文章中,我们对原生websocket进行了了解,且用demo来简单的讲解了其用法.但是在实际项目中,那样的用法是不可取的,理由是tomcat对高并发的支持不怎么好,特别是tomcat ...
- <meta http-equiv="X-UA-Compatible" content="IE=edge">的作用
X-UA-Compatible是针对ie8新加的一个设置,对于ie8之外的浏览器是不识别的. X-UA-Compatible 是针对 IE8 版本的一个特殊文件头标记,用于为 IE8 指定不同的页面渲 ...
- 防止SSH自动断线
在连接远程SSH服务的时候,经常会发生长时间后的断线,或者无响应(无法再键盘输入). 总体来说有两个方法: 1.依赖ssh客户端定时发送心跳. putty.SecureCRT.XShell都有这个功能 ...
- 使用.Net Core+EF7 完成CodeFirst
emmm,本来想着用Core做一个小项目玩玩的,然后肯定是要用到数据库的, 然后想,啊,要不用CodeFirst,感觉很腻害的样子,于是,一脸天真无邪的我就踏入了一个深不见底的天坑... 本来想着,应 ...
- Cs Round#56 D Find Path Union
题意:有一棵如下的完全二叉树,求所有给定结点到根节点的路径的并有多少条边. 一开始联想到线段树,发现结点的排布很像线段树的标号.于是模仿线段树敲了一下,交上去发现3个点MLE了... 无心优化,跑去看 ...
- HDU4466 Triangle
题意:给一个长为N的铁丝,问你有几种方法将其划分为若干段,使得每一段都能围成一个边长为整数的三角形,并且围成的三角形都相似 思路其实很明显,三角形的周长必定是N的约数,那么答案就是周长C能围城的三角形 ...
- 对象存取器属性:getter和setter
在一个对象中,操作其中的属性或方法,通常运用最多的就是读(引用)和写了,譬如说o.a,这就是一个读的操作,而o.b = 1则是一个写的操作.事实上在除ie外最新主流浏览器的实现中,任何一个对象的键值都 ...
- python 爬取国家粮食局东北地区玉米收购价格监测信息
#!/usr/bin/python# -*- coding: UTF-8 -*-import reimport sysimport timeimport urllibimport urllib.req ...
- Cocos2d-X使用CCAnimation创建动画
动画在游戏中是很常见的 程序1:创建一个简单的动画 首先须要在project文件夹下的Resource文件夹中放一张有各种不同动作的图片 在程序中加入以下的代码 #include "Anim ...
- TortoiseSVN的安装和使用
TortoiseSVN是windows平台下Subversion的免费开源client. 一般我们都是先讲讲server的配置.然后再讲client的使用,可是在TortoiseSVN上.却能够反过来 ...