python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行。对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了。本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似的做法,不赘述。主要是分析页面以及用Python实现简单方便的抓取。
笔者使用的工具如下
Python 3——极其方便的编程语言。选择3.x的版本是因为3.x对中文处理更加友好。
Pandas——Python的一个附加库,用于数据整理。
IE 11——分析页面请求过程(其他类似的流量监控工具亦可)。
剩下的还有requests,re,这些都是Python自带的库。
实例页面(美的某热水器):http://detail.tmall.com/item.htm?id=41464129793
评论在哪里?
要抓取评论数据,首先得找到评论究竟在哪里。打开上述网址,然后查看源代码,发现里面并没有评论内容!那么,评论数据究竟在哪里呢?原来天猫使用了ajax加密,它会从另外的页面中读取评论数据。
这时候IE 11就发挥作用了(当然你也可以使用其他的流量监控工具),使用前,先打开上述网址,待页面打开后,清除一下IE 11的缓存、历史文件等,然后按F12,会出现如下界面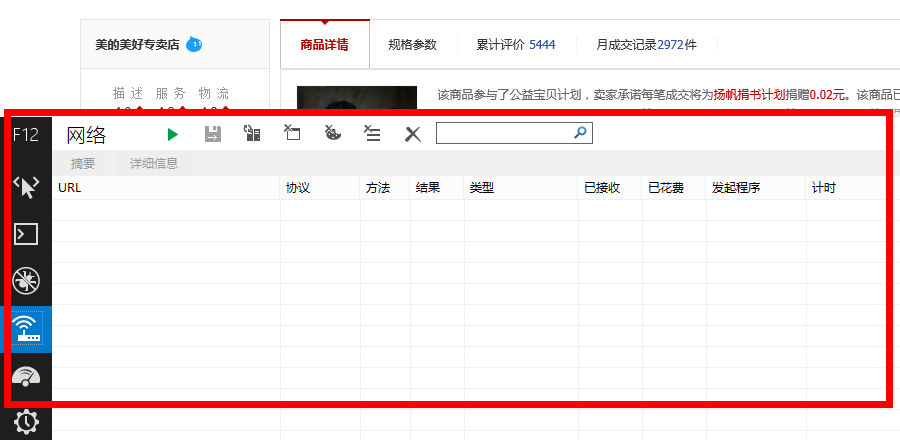
这时候点击绿色的三角形按钮,启动网络流量捕获(或者直接按F5),然后点击天猫页面中的“累计评价”: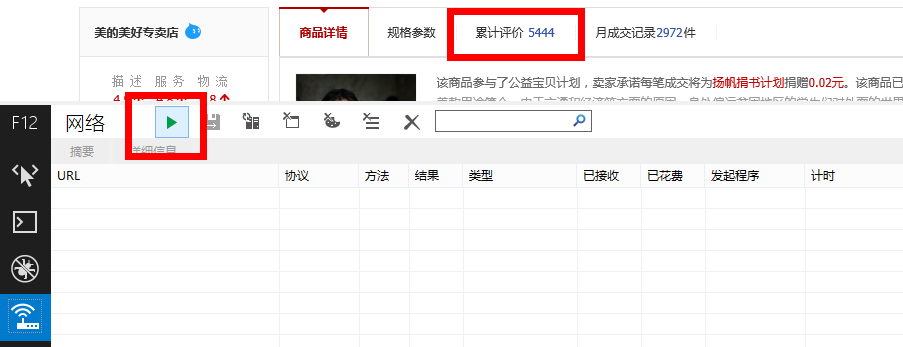
出现如下结果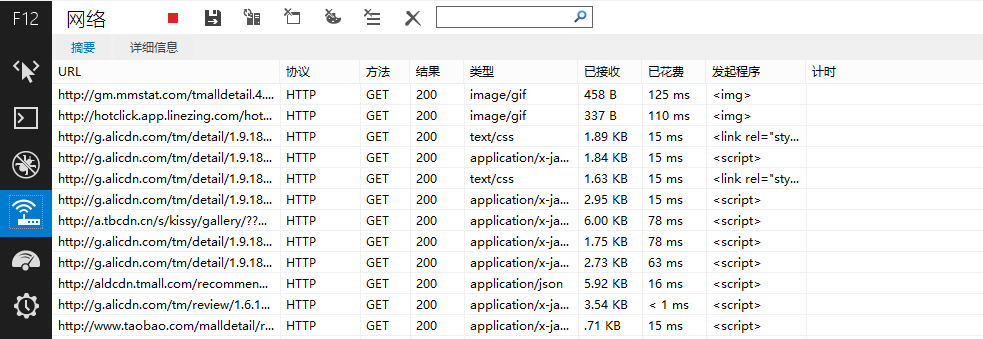
在URL下面出现很多网址,而评论数据正隐藏在其中!我们主要留意类型为“text/html”或者“application/json”的网址,经过测试发现,天猫的评论在下面这个网址之中
http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&spuId=296980116&sellerId=1652490016&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=166UW5TcyMNYQwiAiwVQX1EeUR5RH5Cd0xiNGI%3D%7CUm5Ockt1SHxBe0B0SXNOdCI%3D%7CU2xMHDJxPk82UjVOI1h2VngRd1snQSJEI107F2gFfgRlAmRKakQYeR9zFGoQPmg%2B%7CVGhXd1llXGJfa1ZsV2NeZFljVGlLdUt2TXFOc0tyT3pHe0Z6QHlXAQ%3D%3D%7CVWldfS0SMgo3FysUNBonHyMdNwI4HStHNkVrPWs%3D%7CVmhIGCIWNgsrFykQJAQ6DzQAIBwiGSICOAM2FioULxQ0DjEEUgQ%3D%7CV25OHjAePgA0DCwQKRYsDDgHPAdRBw%3D%3D%7CWGFBET8RMQ04ACAcJR0iAjYDNwtdCw%3D%3D%7CWWBAED5%2BKmIZcBZ6MUwxSmREfUl2VmpSbVR0SHVLcU4YTg%3D%3D%7CWmFBET9aIgwsECoKNxcrFysSL3kv%7CW2BAED5bIw0tESQEOBgkGCEfI3Uj%7CXGVFFTsVNQw2AiIeJxMoCDQIMwg9az0%3D%7CXWZGFjhdJQsrECgINhYqFiwRL3kv%7CXmdHFzkXNws3DS0RLxciAj4BPAY%2BaD4%3D%7CX2ZGFjgWNgo1ASEdIxsjAz8ANQE1YzU%3D%7CQHtbCyVAOBY2Aj4eIwM%2FAToONGI0%7CQXhYCCYIKBMqFzcLMwY%2FHyMdKRItey0%3D%7CQntbCyULKxQgGDgEPQg8HCAZIxoveS8%3D%7CQ3paCiQKKhYoFDQIMggwEC8SJh8idCI%3D%7CRH1dDSMNLRIrFTUJMw82FikWKxUueC4%3D%7CRX5eDiAOLhItEzMOLhIuFy4VKH4o%7CRn5eDiAOLn5GeEdnW2VeYjQUKQknCSkQKRIrFyN1Iw%3D%3D%7CR35Dfl5jQ3xcYFllRXtDeVlgQHxBYVV1QGBfZUV6QWFZeUZ%2FX2FBfl5hXX1AYEF9XXxDY0J8XGBbe0IU&isg=B2E8ACFC7C2F2CB185668041148A7DAA&_ksTS=1430908138129_1993&callback=jsonp1994
是不是感觉长到晕了?不要紧,只需要稍加分析,就发现可以精简为以下部分
http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1
我们发现天猫还是很慷慨的,评论页面的地址是很有规律的(像京东就完全没规律了,随机生成。),其中itemId是商品id,sellerid是卖家id,currentPage是页面号。
怎么爬取?
费了一番周折,终于找到评论在哪里了,接下来是爬取,怎么爬取呢?首先分析一下页面规律。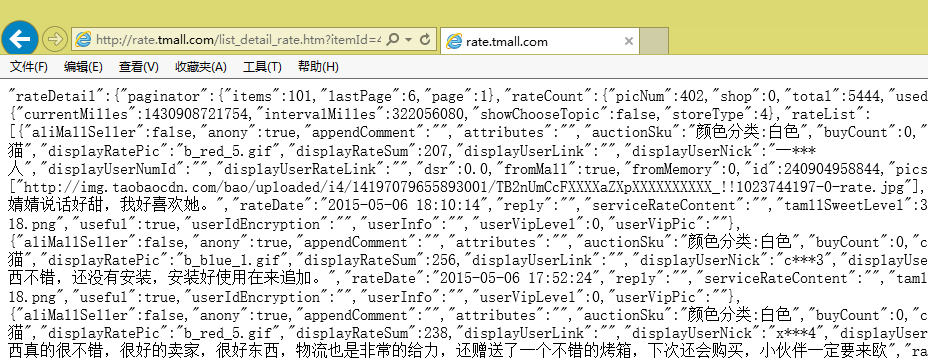
我们发现页面数据是很规范的,事实上,它是一种被称为JSON的轻量级数据交换格式(大家可以搜索JSON),但它又不是通常的JSON,事实上,页面中的方括号[]里边的内容,才是一个正确的JSON规范文本。
下面开始我们的爬取,我使用Python中的requests库进行抓取,在Python中依次输入:
import requests as rq
url='http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1'
myweb = rq.get(url)现在该页面的内容已经保存在myweb变量中了,我们可以用myweb.text查看文本内容。
接下来就是只保留方括号里边的部分,这需要用到正则表达式了,涉及到的模块有re。
import re
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"',myweb.text)[0]呃,这句代码什么意思?懂Python的读者大概都能读懂它,不懂的话,请先阅读一下相关的正则表达式的教程。上面的意思是,在文本中查找下面标签
"rateList":[...],"tags"
找到后保留方括号及方括号里边的内容。为什么不直接以方括号为标签呢,而要多加几个字符?这是为了防止用户评论中出现方括号而导致抓取出错。
现在抓取到了myjson,这是一个标准的JSON文本了,怎么读取JSON?也简单,直接用Pandas吧。这是Python中强大的数据分析工具,用它可以直接读取JSON。当然,如果仅仅是为了读取JSON,完全没必要用它,但是我们还要考虑把同一个商品的每个评论页的数据都合并成一个表,并进行预处理等,这时候Pandas就非常方便了。
import pandas as pd
mytable = pd.read_json(myjson)现在mytable就是一个规范的Pandas的DataFrame了: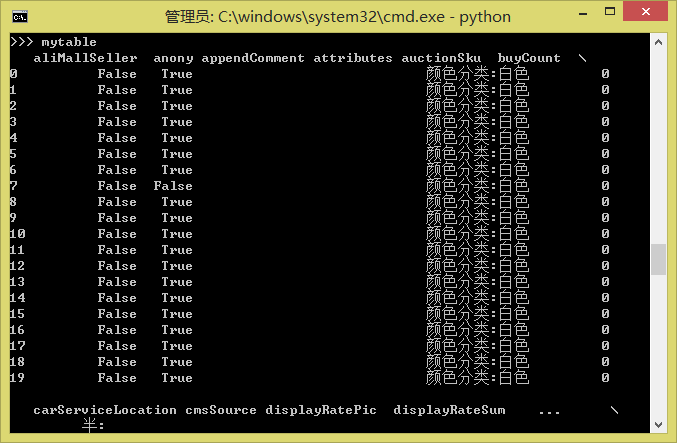
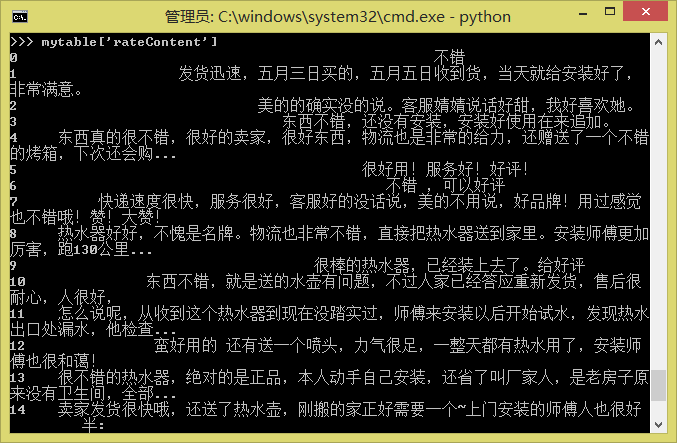
如果有两个表mytable1和mytable2需要合并,则只要
pd.concat([mytable1, mytable2], ignore_index=True)等等。更多的操作请参考Pandas的教程。
最后,要把评论保存为txt或者Excel(由于存在中文编码问题,保存为txt可能出错,因此不妨保存为Excel,Pandas也能够读取Excel文件)
mytable.to_csv('mytable.txt')
mytable.to_excel('mytable.xls')
一点点结论
让我们看看一共用了几行代码?
import requests as rq
import re
import pandas as pd
url='http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1'
myweb = rq.get(url)
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"',myweb.text)[0]
mytable = pd.read_json(myjson)
mytable.to_csv('mytable.txt')
mytable.to_excel('mytable.xls')
九行!十行不到,我们就完成了一个简单的爬虫程序,并且能够爬取到天猫上的数据了!是不是跃跃欲试了?
当然,这只是一个简单的示例文件。要想实用,还要加入一些功能,比如找出评论共有多少页,逐页读取评论。另外,批量获取商品id也是要实现的。这些要靠大家自由发挥了,都不是困难的问题,本文只希望起到抛砖引玉的作用,为需要爬取数据的读者提供一个最简单的指引。
其中最困难的问题,应该是大量采集之后,有可能被天猫本身的系统发现,然后要你输入验证码才能继续访问的情况,这就复杂得多了,解决的方案有使用代理、使用更大的采集时间间隔或者直接OCR系统识别验证码等等,笔者也没有很好的解决办法。
转载到请包括本文地址:http://spaces.ac.cn/archives/3298/
python 爬取天猫美的评论数据的更多相关文章
- Python爬取 | 唯美女生图片
这里只是代码展示,且复制后不能直接运行,需要配置一些设置才行,具体请查看下方链接介绍: Python爬取 | 唯美女生图片 from selenium import webdriver from fa ...
- Python爬虫实战练习:爬取美团旅游景点评论数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 今年的国庆节还有半个月就要来了,相信很多的小伙伴还是非常期待这个小长假的.国庆节是一年中的小 ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- python爬取豆瓣top250的电影数据并存入excle
爬取网址: https://movie.douban.com/top250 一:爬取思路(新手可以看一下) : 1:定义两个函数,一个get_page函数爬取数据,一个save函数保存数据,mian中 ...
- Python爬取6271家死亡公司数据,一眼看尽十年创业公司消亡史!
小五利用python将其中的死亡公司数据爬取下来,借此来观察最近十年创业公司消亡史. 获取数据 F12,Network查看异步请求XHR,翻页. 成功找到返回json格式数据的url, 很多人 ...
- Python爬取上交所一年大盘数据
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 半个码农2018 PS:如有需要Python学习资料的小伙伴可以加点 ...
- Python爬取6271家死亡公司数据,看十年创业公司消亡史
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 朱小五 凹凸玩数据 PS:如有需要Python学习资料的小伙伴可以加 ...
- Python爬取某网站文档数据完整教程(附源码)
基本开发环境 (https://jq.qq.com/?_wv=1027&k=NofUEYzs) Python 3.6 Pycharm 相关模块的使用 (https://jq.qq.com/?_ ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
随机推荐
- 51nod_1639:绑鞋带
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1639 #include <bits/stdc++.h& ...
- Linux之grep及正则表达式
grep简介 grep 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来.通常grep有三种版本grep.egrep(等同于grep -E)和fgrep.egrep为扩展的g ...
- MySQL系列(二)---MySQL事务
MySql 事务 目录 MySQL系列(一):基础知识大总结 MySQL系列(二):MySQL事务 什么是事务(transaction) 保证成批操作要么完全执行,要么完全不执行,维护数据的完整性.也 ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- 【JAVASCRIPT】React学习- 数据流(组件通信)
摘要 react 学习包括几个部分: 文本渲染 JSX 语法 组件化思想 数据流 一 组件通信如何实现 父子组件之间不存在继承关系 1.1 父=>子通信 父组件可以通过 this.refs.xx ...
- 移动端和pc端事件绑定方式以及取消浏览器默认样式和取消冒泡
### 两种绑定方式 (DOM0)1.obj.onclick = fn; (DOM2)2. ie:obj.attachEvent(事件名称,事件函数); 1.没有捕获(非标准的ie 标准的ie底下有 ...
- 浅谈js分页的几种方法
一个项目中必然会遇到分页这种需求的,分页可以使数据加载更合理,也让页面显示更美观,更有层次感!那么js分页到底如何实现呢?下面我就来讲一下三种循序渐进的方法 1.自己纯手写分页 更深入的去理解分页的意 ...
- python的__init__几种方法总结
参考 __init__() 这个方法一般用于初始化一个类 但是 当实例化一个类的时候, __init__并不是第一个被调用的, 第一个被调用的是__new__ #!/usr/bin/env pytho ...
- [js高手之路] es6系列教程 - var, let, const详解
function show( flag ){ console.log( a ); if( flag ){ var a = 'ghostwu'; return a; } else { console.l ...
- Js 获取时间戳
//获取时间戳 单位:秒: //1. 获取当前时间戳 function getUnixTime(){ var date = new Date(); //使用getTime方法: var unix_ti ...