中文分词中的战斗机-jieba库
英文分词的第三方库NLTK不错,中文分词工具也有很多(盘古分词、Yaha分词、Jieba分词等)。但是从加载自定义字典、多线程、自动匹配新词等方面来看。
大jieba确实是中文分词中的战斗机。
请随意观看表演
安装
- 使用pip包傻瓜安装:
py -3 -m pip install jieba/pip install jiba(windows下推荐第一种,可以分别安装python2和3对应jieba) - pypi下载地址
分词
3种模式
- 精确模式:试图将句子最精确地切开,适合文本分析
- 全模式:把句子中所有的可以成词的词语都扫描出来(速度快)
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
实现方式
- 精确模式:
jieba.cut(sen) - 全模式:
jieba.cut(sen,cut_all=True) - 搜索引擎模式:
jieba.cut_for_search(sen)
import jieba
sen = "我爱深圳大学"
sen_list = jieba.cut(sen)
sen_list_all = jieba.cut(sen,cut_all=True)
sen_list_search = jieba.cut_for_search(sen)
for i in sen_list:
print(i,end=" ")
print()
for i in sen_list_all:
print(i,end=" ")
print()
for i in sen_list_search:
print(i,end=" ")
print()
结果:附截图

自定义词典
创建方式
- 后缀:txt
- 格式:词语( 权重 词性 )
- 注意事项:
- windows下txt不能用自带的编辑器,否则会乱码。可以用VSCODE,或者其他编辑器
- 可以只有词语
- 在没有权重的情况下,只有比默认词典长的词语才可以加载进去。附截图

加载字典
jieba.load_userdict(txtFile)
调整字典
添加词:jieba.add_word(word,freq=None,tag=None)
删除词:jieba.del_word(word)
import jieba
sen = "胶州市市长江大桥"
sen_list = jieba.cut(sen)
for i in sen_list:
print(i,end=" ")
print()
胶州市 市 长江大桥
jieba.add_word('江大桥',freq=20000)
sen_list = jieba.cut(sen)
for i in sen_list:
print(i,end=" ")
print()
结果附截图

改变主字典
- 占用内存较小的词典文件
- 支持繁体分词更好的词典文件
- 加载方法:
jieba.set_dictionary('data/dict.txt.big')
延迟加载
之前发现,词典不是一次性加载的,说明它采用的是延迟加载。即:当遇到应用的时候才会加载。有点类似于python高级特性中的
yield(节省内存)
效果图如下:
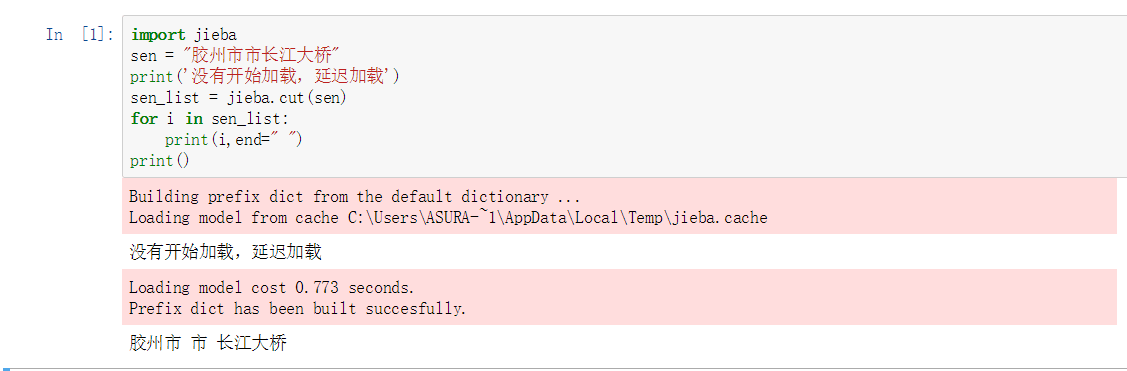
- 手动加载的方法:
jieba.initialize()
关键词提取
jieba.analyse.extract_tags(sentence,topK=20):返回topK个TF/IDF权重最大的词语
import jieba.analyse
sen_ana = jieba.analyse.extract_tags(sen,3)
for i in sen_ana:
print(i)
江大桥
胶州市
市长
词性标注
jieba.posseg.cut(sen):返回的每个迭代对象有两个属性-> word 词语 + flag 词性
import jieba.posseg
words = jieba.posseg.cut(sen)
for word in words:
print(word.flag," ",word.word)
ns 胶州市
n 市长
x 江大桥
词语定位
jieba.tokenize(sen,mode):mode可以设置为search,开启搜索模式
index= jieba.tokenize(sen)
for i in index:
print(i[0],"from",i[1],"to",i[2])
胶州市 from 0 to 3
市长 from 3 to 5
江大桥 from 5 to 8
内部算法
- 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
参考文献
中文分词中的战斗机-jieba库的更多相关文章
- SCWS中文分词,向xdb词库添加新词
SCWS是个不错的中文分词解决方案,词库也是hightman个人制作,总不免有些不尽如人意的地方.有些词语可能不会及时被收入词库中. 幸好SCWS提供了词库XDB导出导入词库的工具(phptool_f ...
- Hanlp在java中文分词中的使用介绍
项目结构 该项目中,.jar和data文件夹和.properties需要从官网/github下载,data文件夹下载 项目配置 修改hanlp.properties: 1 #/Test/src/han ...
- 结巴(jieba)中文分词及其应用实践
中文文本分类不像英文文本分类一样只需要将单词一个个分开就可以了,中文文本分类需要将文字组成的词语分出来构成一个个向量.所以,需要分词. 这里使用网上流行的开源分词工具结巴分词(jieba),它可以有效 ...
- 如何运用jieba库分词
使用jieba库分词 一.什么是jieba库 1.jieba库概述 jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个词语. 2.jieba库的使用:(jieba库支持3种分词模式) 通 ...
- 运用jieba库分词
代码: 统计出团队中文简介中词频 import jieba txt=open("C:\\Users\\Administrator\\Desktop\\介绍.txt","r ...
- NLP舞动之中文分词浅析(一)
一.简介 针对现有中文分词在垂直领域应用时,存在准确率不高的问题,本文对其进行了简要分析,对中文分词面临的分词歧义及未登录词等难点进行了介绍,最后对当前中文分词实现的算法原理(基于词表. ...
- HMM(隐马尔科夫)用于中文分词
隐马尔可夫模型(Hidden Markov Model,HMM)是用来描述一个含有隐含未知参数的马尔可夫过程. 本文阅读了2篇blog,理解其中的意思,附上自己的代码,共同学习. 一.理解隐马尔科夫 ...
- R语言中文分词包jiebaR
R语言中文分词包jiebaR R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大. R语言作为统计学一门语言,一直在小众领域闪耀着光芒.直到大数据 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
随机推荐
- 关于generator异步编程的理解以及如何动手写一个co模块
generator出现之前,想要实现对异步队列中任务的流程控制,大概有这么一下几种方式: 回调函数 事件监听 发布/订阅 promise对象 第一种方式想必大家是最常见的,其代码组织方式如下: fun ...
- SDRAM notebook
/*******************************************************************************/ chapter one * SDR ...
- R语言各种假设检验实例整理(常用)
一.正态分布参数检验 例1. 某种原件的寿命X(以小时计)服从正态分布N(μ, σ)其中μ, σ2均未知.现测得16只元件的寿命如下: 159 280 101 212 224 379 179 264 ...
- 安装hadoop2.7.3
hadoop3与hadoop2.x的变化很大,hadoop3很多东西现在做起来太麻烦了,这里先安装hadoop2.7.3 此贴学习地址http://www.yiibai.com/t/mapreduce ...
- FreeBSD上构架Nginx服务器
这篇文章主要记录作者如何在FreeBSD上构架Nginx服务器.作者采用下载该程序的一个源代码包手动编译的方法,而不是使用包管理工具.这样做有两个原因:首先包质量不能保证,或无效或版本旧:其次需要在编 ...
- SectionIndexer 利用系统的控件,制作比较美观的侧栏索引控件
如上图所示,右侧的索引是系统提供的,具体使用方法,请搜索: SectionIndexer 相关的资料进行开发.
- Oracle12c多租户CDB 与 PDB 参数文件位置探讨、查询 CDB 与 PDB 不同值的参数
一. Oracle12c多租户CDB 与 PDB 参数文件位置CDB的参数文件依然使用12c以前的SPIFLE,pdb的参数文件不会出现在SPFILE中,而是直接从CDB中继承,如果PDB中有priv ...
- Linux 定时任务详解
原文地址:http://edu.codepub.com/2011/0104/28518.php crond分为系统级定时和用户级定时,系统级定时主要编辑/etc/crontab,用户级定时主要利用 ...
- 如何用jQuery实现div随鼠标移动而移动(详解)?----2017-05-12
重点是弄清楚如何获取鼠标现位置与移动后位置,div现在位置与移动后位置: 用jQuery实现div随鼠标移动而移动,不是鼠标自身的位置!!而是div相对于之前位置的移动 代码如下:(注意看绿色部分的解 ...
- hadoop集群中客户端修改、删除文件失败
这是因为hadoop集群在启动时自动进入安全模式 查看安全模式状态:hadoop fs –safemode get 进入安全模式状态:hadoop fs –safemode enter 退出安全模式状 ...