Adaptive gradient descent without descent
概
本文提出了一种自适应步长的梯度下降方法(以及多个变种方法), 并给了收敛性分析.
主要内容
主要问题:
\min_x \: f(x).
\]
局部光滑的定义:
若可微函数\(f(x)\)在任意有界区域内光滑,即
\]
其中\(\mathcal{C}\)有界.
本文的一个基本假设是函数\(f(x)\)凸且局部光滑.
算法1 AdGD

定理1 ADGD-L
定理1. 假设\(f: \mathbb{R}^d \rightarrow \mathbb{R}\) 为凸函数且局部光滑. 则由算法1生成的序列\((x^k)\)收敛到(1)的最优解, 且
\]
其中\(\hat{x}^k := \frac{\sum_{i=1}^k \lambda_i x^i + \lambda_1 \theta_1 x^1}{S_k}\), \(S_k:= \sum_{i=1}^k \lambda_i + \lambda_1 \theta\).
算法2

在\(L\)已知的情况下, 我们可以对算法1进行改进.
定理2
定理2 假设\(f\)凸且\(L\)光滑, 则由算法(2)生成的序列\((x^k)\)同样使得
\]
成立.
算法3 ADGD-accel

这部分没有理论证明, 是作者基于Nesterov中的算法进行的改进.
算法4 Adaptive SGD

这个算法是对SGD的一个改进.
定理4

代码
\(f(x, y) = x^2+50y^2\), 起点为\((30, 15)\).
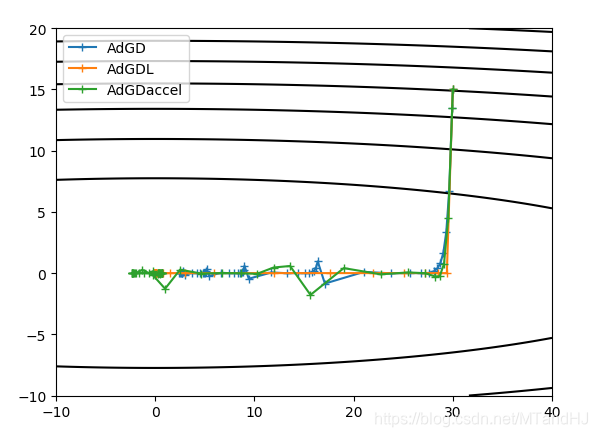
"""
adgd.py
"""
import numpy as np
import matplotlib.pyplot as plt
State = "Test"
class FuncMissingError(Exception): pass
class StateNotMatchError(Exception): pass
class AdGD:
def __init__(self, x0, stepsize0, grad, func=None):
self.func_grad = grad
self.func = func
self.points = [x0]
self.points.append(self.calc_one(x0, self.calc_grad(x0),
stepsize0))
self.prestepsize = stepsize0
self.theta = None
def calc_grad(self, x):
self.pregrad = self.func_grad(x)
return self.pregrad
def calc_one(self, x, grad, stepsize):
return x - stepsize * grad
def calc_stepsize(self, grad, pregrad):
part2 = (
np.linalg.norm(self.points[-1]
- self.points[-2]) /
(np.linalg.norm(grad - pregrad) * 2)
)
if not self.theta:
return part2
else:
part1 = np.sqrt(self.theta + 1) * self.prestepsize
return min(part1, part2)
def update_theta(self, stepsize):
self.theta = stepsize / self.prestepsize
self.prestepsize = stepsize
def step(self):
pregrad = self.pregrad
prex = self.points[-1]
grad = self.calc_grad(prex)
stepsize = self.calc_stepsize(grad, pregrad)
nextx = self.calc_one(prex, grad, stepsize)
self.points.append(nextx)
self.update_theta(stepsize)
def multi_steps(self, times):
for k in range(times):
self.step()
def plot(self):
if self.func is None:
raise FloatingPointError("func is not defined...")
if State != "Test":
raise StateNotMatchError()
xs = np.array(self.points)
x = np.linspace(-40, 40, 1000)
y = np.linspace(-20, 20, 500)
fig, ax = plt.subplots()
X, Y = np.meshgrid(x, y)
ax.contour(X, Y, self.func([X, Y]), colors='black')
ax.plot(xs[:, 0], xs[:, 1], "+-")
plt.show()
class AdGDL(AdGD):
def __init__(self, x0, L, grad, func=None):
super(AdGDL, self).__init__(x0, 1 / L, grad, func)
self.lipschitz = L
def calc_stepsize(self, grad, pregrad):
lk = (
np.linalg.norm(grad - pregrad) /
np.linalg.norm(self.points[-1]
- self.points[-2])
)
part2 = 1 / (self.prestepsize * self.lipschitz ** 2) \
+ 1 / (2 * lk)
if not self.theta:
return part2
else:
part1 = np.sqrt(self.theta + 1) * self.prestepsize
return min(part1, part2)
class AdGDaccel(AdGD):
def __init__(self, x0, stepsize0, convex0, grad, func=None):
super(AdGDaccel, self).__init__(x0, stepsize0, grad, func)
self.preconvex = convex0
self.Theta = None
self.prey = self.points[-1]
def calc_convex(self, grad, pregrad):
part2 = (
(np.linalg.norm(grad - pregrad) * 2) /
np.linalg.norm(self.points[-1]
- self.points[-2])
) / 2
if not self.Theta:
return part2
else:
part1 = np.sqrt(self.Theta + 1) * self.preconvex
return min(part1, part2)
def calc_beta(self, stepsize, convex):
part1 = 1 / stepsize
part2 = convex
return (part1 - part2) / (part1 + part2)
def calc_more(self, y, beta):
nextx = y + beta * (y - self.prey)
self.prey = y
return nextx
def update_Theta(self, convex):
self.Theta = convex / self.preconvex
self.preconvex = convex
def step(self):
pregrad = self.pregrad
prex = self.points[-1]
grad = self.calc_grad(prex)
stepsize = self.calc_stepsize(grad, pregrad)
convex = self.calc_convex(grad, pregrad)
beta = self.calc_beta(stepsize, convex)
y = self.calc_one(prex, grad, stepsize)
nextx = self.calc_more(y, beta)
self.points.append(nextx)
self.update_theta(stepsize)
self.update_Theta(convex)
config.json:
{
"AdGD": {
"stepsize0": 0.001
},
"AdGDL": {
"L": 100
},
"AdGDaccel": {
"stepsize0": 0.001,
"convex0": 2.0
}
}
"""
测试代码
"""
import numpy as np
import matplotlib.pyplot as plt
import json
from adgd import AdGD, AdGDL, AdGDaccel
with open("config.json", encoding="utf-8") as f:
configs = json.load(f)
partial_x = lambda x: 2 * x
partial_y = lambda y: 100 * y
grad = lambda x: np.array([partial_x(x[0]),
partial_y(x[1])])
func = lambda x: x[0] ** 2 + 50 * x[1] ** 2
fig, ax = plt.subplots()
x = np.linspace(-10, 40, 500)
y = np.linspace(-10, 20, 500)
X, Y = np.meshgrid(x, y)
ax.contour(X, Y, func([X, Y]), colors='black')
def process(methods, times=50):
for method in methods:
method.multi_steps(times)
def initial(methods, **kwargs):
instances = []
for method in methods:
config = configs[method.__name__]
config.update(kwargs)
instances.append(method(**config))
return instances
def plot(methods):
for method in methods:
xs = np.array(method.points)
ax.plot(xs[:, 0], xs[:, 1], "+-", label=method.__class__.__name__)
plt.legend()
plt.show()
x0 = np.array([30., 15.])
methods = [AdGD, AdGDL, AdGDaccel]
instances = initial(methods, x0=x0, grad=grad, func=func)
process(instances)
plot(instances)
Adaptive gradient descent without descent的更多相关文章
- 【转】Caffe初试(九)solver及其设置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 #caffe train --solver=*_solver. ...
- 【深度学习】之Caffe的solver文件配置(转载自csdn)
原文: http://blog.csdn.net/czp0322/article/details/52161759 今天在做FCN实验的时候,发现solver.prototxt文件一直用的都是mode ...
- Caffe学习系列(7):solver及其配置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 # caffe train --solver=*_slover ...
- tensorflow 学习(一)
改系列只为记录我学习 udacity 中深度学习课程!! 1. 整个课程分为四个部分,如上图所示. 第一部分将研究逻辑分类器,随机优化以及实际数据训练. 第二部分我们将学习一个深度网络,和使用正则化技 ...
- caffe中各层的作用:
关于caffe中的solver: cafffe中的sover的方法都有: Stochastic Gradient Descent (type: "SGD"), AdaDelta ( ...
- Caffe学习系列(8):solver优化方法
上文提到,到目前为止,caffe总共提供了六种优化方法: Stochastic Gradient Descent (type: "SGD"), AdaDelta (type: &q ...
- Caffe学习系列(二)Caffe代码结构梳理,及相关知识点归纳
前言: 通过检索论文.书籍.博客,继续学习Caffe,千里之行始于足下,继续努力.将自己学到的一些东西记录下来,方便日后的整理. 正文: 1.代码结构梳理 在终端下运行如下命令,可以查看caffe代码 ...
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
随机推荐
- A Child's History of England.11
CHAPTER 4 ENGLAND UNDER ATHELSTAN AND THE SIX BOY-KINGS Athelstan, the son of Edward the Elder, succ ...
- Linux下强制踢掉登陆用户
1.pkill -kill -t tty 例:pkill -kill -t tty1
- echo -e "\033[字背景颜色;字体颜色m字符串\033[0m
格式: echo -e "\033[字背景颜色;字体颜色m字符串\033[0m" 例如: echo -e "\033[41;36m something here \033 ...
- Android: EditText设置属性和设置输入规则
1.EditText输入限制规则 在xml:EditText 设置属性 android:digits="ABCDE123&*" ABCDE123&*是你的限制规则 ...
- 什么是maven(一)
转自博主--一杯凉茶 我记得在搞懂maven之前看了几次重复的maven的教学视频.不知道是自己悟性太低还是怎么滴,就是搞不清楚,现在弄清楚了,基本上入门了.写该篇博文,就是为了帮助那些和我一样对于m ...
- Redis5.0.8 Cluster集群部署
目录 一.Redis Cluster简介 二.部署 三.创建主库 一.Redis Cluster简介 Redis Cluster集群是一种去中心化的高可用服务,其内置的sentinel功能可以提供高可 ...
- Jenkins集成jira
目录 一.Jenkins中Jira插件安装 二.Jenkins中Jira配置 一.Jenkins中Jira插件安装 点击 Manage Jenkins-->Manage Plugins--> ...
- 数据挖掘实战 - 天池新人赛o2o优惠券使用预测
数据挖掘实战 - o2o优惠券使用预测 一.前言 大家好,家人们.今天是2021/12/14号.上次更新是2021/08/29.上篇文章中说到要开两个专题,果不其然我鸽了,这一鸽就是三个多月.今天,我 ...
- [BUUCTF]REVERSE——xor
xor 附件 步骤: 附件很小,直接用ida打开,根据检索得到的字符串,找到程序关键函数 程序很简单,一开始让我们输入一个长度为33的字符串给v6,然后v6从第二个字符开始与前一个字符做异或运算,得到 ...
- [BUUCTF]PWN——ciscn_2019_ne_5
ciscn_2019_ne_5 题目附件 步骤: 例行检查,32位,开启了nx保护 试运行一下程序,看一下程序的大概执行情况 32位ida载入,shift+f12查看程序里的字符串,发现了flag字符 ...