[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 参考文献
(1) 解决问题
现有的异构网络(HIN)嵌入方法本质上可以归结为两个步骤(1)正样本生成和负样本生成(2)在这些样本上训练模型优化目标函数以得到更合适的节点嵌入。目前主流的异构网络嵌入方法存在以下几个问题:
Problem 1: 首先,这些算法一般从原始网络中随机选择节点与中心节点组合生成正样本或者负样本,即,他们的样本生成是任意的并且只限于原始网络中存在的节点。更进一步,现有的GAN设计的生成器没办法生成最具有代表性的假节点,因为这些最具有代表性的假节点甚至没有出现在原始网络中。
Problem 2: 其次,这些方法主要聚焦于捕获HIN中的语义信息,而没有考虑网络中节点的潜在分布,从而在稀疏和存在噪声的真实异构网络中缺乏鲁棒性。
Problem 3: 最后,一些异构嵌入方法依赖于合适的元路径来捕获特定的语义信息,元路径的设计要求领域知识,代价昂贵。
Problem 4: 现有基于GAN的方法都是应用在同构络上的,而且生成器需要学习网络中节点的有限离散分布。因此,他们通常需要去计算一个繁琐的Softmax函数,最终再利用近似技术(如负采样、图softmax)来降低开销。
利用GAN框架解决以上Problems: GAN利用一种博弈的思想来训练判别器模型和生成器模型,生成器模型学习一种潜在的分布,这使得模型对稀疏或噪声数据更加鲁棒,也提供了更好的样本(解决Problem 2)。与先前利用GAN在同质网络上学习图节点嵌入的工作GraphGAN相比,HeGAN能够网络中丰富的异构信息,并且HeGAN的生成器能够直接从一个连续分布中采样潜在节点,不局限于采样原始网络中存在的节点作为假节点,而且可以生成原始网络中不存在的节点的嵌入向量作为假节点,且不需要繁琐的Softmax函数计算(解决Problem 1和Problem 4)。由于HeGAN框架中并没有使用metapath(元路径),不存在Problem 3。
(2) 主要贡献
Contribution 1:是第一个用生成对抗网络(GAN)来做异构网络嵌入的工作。(即将GAN拓展到异构网络中来)
Contribution 2:基于传统GAN,提出一个新颖的框架HeGAN, 不仅利用关系感知型判别器来捕获异构网络中丰富的语义信息,而且设计了一个有效且高效的生成器。
(3) 算法原理
先简单介绍一下一般的GAN,其对抗学习可以看成一个最小最大博弈过程,其目标函数如下公式所示:
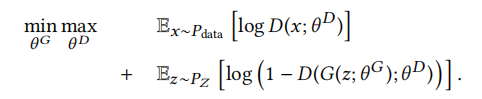
通俗理解上述公式,生成器G试图用预定义的分布PZ生成尽可能接近真实数据的假样本,其中θG表示生成器的参数。相反,判别器D试图去辨别真实网络采样的真样本和生成器生成的假样本,给真样本赋予高概率输出(接近1),给假样本赋予接近0的概率输出。θD为判别器的参数。
接下来介绍一下论文所提算法HeGAN的总体框架: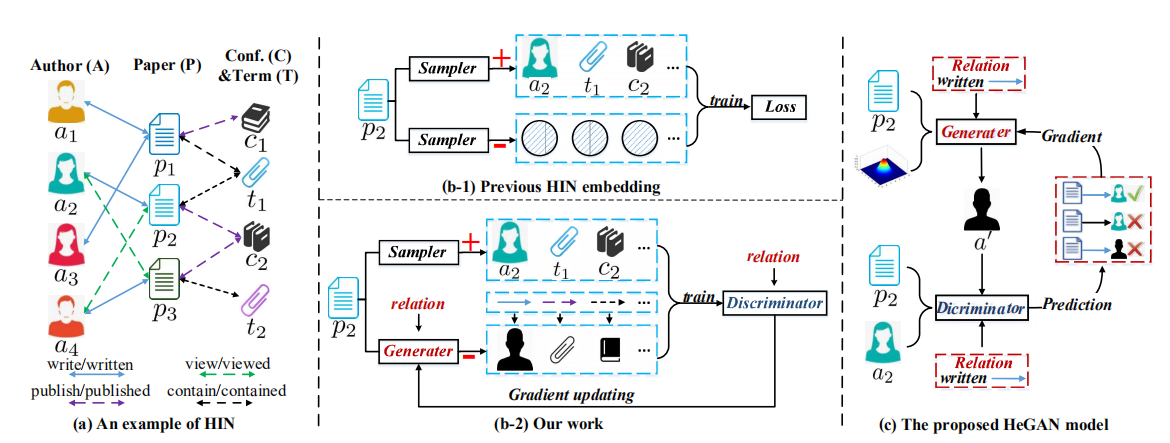
如上图所示,(b-1)是现有HIN嵌入方法的一般做法,从原始网络中采样正样本和负样本来训练模型优化损失。(b-2)是本篇论文的主要工作,即利用生成器生成假样本配合从原始网络中的真样本来训练模型优化损失。(c)是HeGAN模型的总体框架,主要包括判别器和生成器两个部分,其过程如下: 判别器接受来自真实网络的真样本和接受生成器生成的原始网络中不存在的假样本作为输入,预测样本中两节点存在关系r的概率,并且返回梯度来优化生成器的参数和判别器自身的参数。讲人话就是说,更好地判别器促使生成器也产生更好的假样本,两本相互制衡也相互促进,这个过程不断重复,直到达到一个平衡。
现在分别介绍HeGAN判别器和生成器的设计思路和设计细节。
- 设计思路(更进一步明确本文所要解决的两个问题):
- 现有的利用GAN的嵌入方法只是根据与中心节点在图结构上是否有链接来判别一个节点是真的还是假的。例如上图(a)中,给定中心节点p2,a2和a4和p2有链接,那么a2和a4就是真节点,然而我们可以注意到,a2和a4与p2的关系又是不同的,例如,a2写了p2,a4只是看了p2,这种关系强度明显是不同的,原始GAN并没有考虑到这层关系,不能区分关系的强度(即异构网络中的语义不能保留下来)。更进一步说,给定论文p2以及关系类型(如说、写、被写等),HeGAN的判别器能够分离a2和a4,生成器也会产生一个更加接近a2的假样本,因为a2对于p2来说更加重要。
- 现有的研究的有效性和高效性都受到样本生成的限制。它们通常使用某种形式的Softmax对原始网络中的所有节点进行节点分布建模。对于有效性,他们的假样本可能局限于采样原始网络中有的节点,而实际上,最具代表性的假样本可能位于现有节点对应的嵌入向量之间,并不是现有节点。例如给定p2,他们只能从原始网络中节点选择假样本,例如a1和a3。然而a1和a3可能并不与真实样本a2足够相似。为了更好地生成样本 ,我们引入了一个广义的生成器,这个生成器可以产生一个潜在节点,例如图1(c)中的a',这个点不存在于原始图中。如,a'可以是a1和a3的平均,并且与真实样本a2更相似。在效率方面,之前算法采用Softmax函数生成节点分布计算成本较高,必须采用负采样和图Softmax等近似方法。而与之对比,我们的生成器可以在不使用softmax的情况下直接生成假节点。
- 设计细节(HeGAN中的判别器和生成器):
(关系感知型)判别器:首先明确判别器目标是在给定关系下,区分HIN中的真节点和假节点。因此HeGAN的判别器评估了节点对u和v存在关系r的概率。u和r分别是给定的节点和关系,ev是采样节点的嵌入(可以是假节点)。本质上,判别器最终输出一个概率,即给定关系r和节点u,节点u与采样节点v具有关系r的概率。如下公式所示(当<u,v,r>是正样本时,概率应该很高,如果是负样本则概率应该很低)。判别器输出设计如下(Mr为可学习的关系矩阵,每个关系r对应一个矩阵,表示的意思应该是节点对u,v在关系r上相似的权重,详情请看设计原理1中所举的例子):
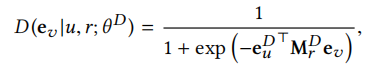
因此,判别器的参数θD包括,由判别器所学习的所有节点向量组成的嵌入矩阵e和所有关系对应矩阵Mr组成的三维张量。
每个三元组<u,v,r>表示一个样本,其归属于以下三种情况之一(受CGAN的启发,每种情况都是判别器损失函数的一部分)。case 1:节点u,v在给定关系r下是相连的。这样一种三元组<u,v,r>是真样本(这个真样本三元组是在原图中采样得到的),判别器对于输入的正样本输出概率要尽可能大,可以用以下损失函数来建模,如下公式所示(D越大损失越小)。
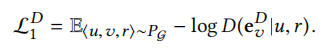
case 2:节点u、v在关系r下没有连接。这样子的三元组<u,v,r>对于判别器来说为假样本(这个假样本三元组是利用原图中采样的正样本得到的,如对于采样的真样本<u,v,r>,把他的关系r换成r'就得到假样本了,并且r'≠r),对于输入的假样本,判别器输出概率要低,值要越小,定义这部分损失如下公式所示(D越小损失越小)。
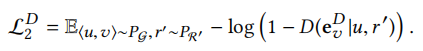
case 3:由关系感知生成器生成假节点作为假样本。也就是说,给定原始网络中的节点u,利用生成器生成假节点v。也就是对于原始图中的真样本<u,v,r>,利用生成器模拟真实节点v生成假节点v'的嵌入(从生成器学习的节点分布(区别于判别器θD)中提取),得到假样本<u,v',r>。之后,判别器目标在于识别这种三元组为假样本,损失函数如下公式所示。(判别器输出概率越低越好,这边设计有点怪,case 2和case 3的样本完全一个可以认为是负样本,一个可以认为是正样本,判别器输出的概率偏向却都是类似的,假设判别器只区分真样本和假样本的话,case 1对应的是真样本,case 2和case 3对应的都是假样本,这倒是没啥毛病!!!)
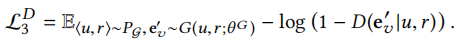
(注意,判别器在对抗过程中只优化自己的参数θD,假节点嵌入ev'是生成器的优化目标)最终判别器的总的损失函数由以上三部分再加上一个正则项组成,如下所示:
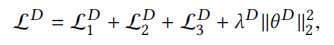
(关系感知型)生成器:同样地,首先明确生成器的目标是模拟真实样本来生成假样本。即给定节点u和关系r,生成器的目标是生成一个在关系r下可能连接到节点u的假节点v'。因此,HeGAN的生成器利用特定关系r对应的关系矩阵Mr来从一个潜在的连续分布中生成假样本的节点嵌入,即利用以下公式所示的高斯分布:
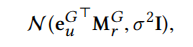
即每个节点对于每个关系都对应一个高斯分布,高斯分布的均值为euMr,方差为σ2I。直观理解,均值代表一个假节点v与u在关系r下连接的连接概率,并且方差表示这个连接潜在的偏差。那么怎么生成假样本呢? 一个最直接的办法就是直接从这个高斯分布中生成样本,并且作者融合了多层感知器MLP到生成器中来增强假样本的表示。因此,生成器设计如下公式所示:
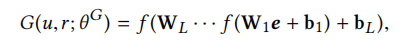
euG为从对应高斯分布中生成节点向量。因此生成器的参数θG包括节点嵌入矩阵,关系矩阵以及多层感知器MLP的参数(权值矩阵和阈值矩阵)。
如前所述,生成器希望通过生成接近真实的假样本来欺骗判别器,从而使判别器给他们高分,即,生成器的目标就是要生成假样本使得判别器判高分,也就是判别器输出D()要大。因此,最终模型最小化以下目标函数来优化生成器的参数θG(D越大,生成器损失越小)。
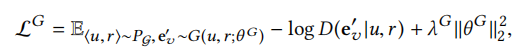
目标函数优化方法:采用迭代优化策略,在每次迭代中,交替训练生成器和判别器。首先,固定θG并且生成假样本来优化θD,从而优化判别器的性能。其次,固定θD,优化θG以产生质量更好的假样本。重复以上过程进行多次迭代,直到模型收敛即可。
(4) 参考文献
Hu B, Fang Y, Shi C. Adversarial learning on heterogeneous information networks[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 120-129.
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks的更多相关文章
- [论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 ...
- 论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)
论文源址:https://arxiv.org/abs/1705.06820 tensorflow(github): https://github.com/HongyangGao/PixelDCN 基于 ...
- 论文阅读:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
前言 CVPR2016 来自Korea的POSTECH这个团队 大部分算法(例如HCF, DeepLMCF)只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,这些做法 ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [论文阅读笔记] Are Meta-Paths Necessary, Revisiting Heterogeneous Graph Embeddings
[论文阅读笔记] Are Meta-Paths Necessary? Revisiting Heterogeneous Graph Embeddings 本文结构 解决问题 主要贡献 算法原理 参考文 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
随机推荐
- Day16_95_IO_循环读取文件字节流read()方法(四)
循环读取文件字节流read()方法(四) 使用 int read(byte[] bytes) 循环读取字节流数据 import java.io.FileInputStream; import java ...
- Insertion Sort and Merge Sort
Insertion Sort(插入排序) 思路:for 循环遍历数组中的每一个数 用while将每次遍历到的数于左侧的数进行对比,将小的排到左边 void InsertionSort(int*A, i ...
- 《疯狂Kotlin讲义》读书笔记6——函数和Lambda表达式
函数和Lambda表达式 Kotlin融合了面向过程语言和面向对象语言的特征,相比于Java,它增加了对函数式编程的支持,支持定义函数.调用函数.相比于C语言,Kotlin支持局部函数(Lambda表 ...
- PowerBI开发 第十八篇:行级安全(RLS)
PowerBI可以通过RLS(Row-level security)限制用户对数据的访问,过滤器在行级别限制数据的访问,用户可以在角色中定义过滤器,通过角色来限制数据的访问.在PowerBI Serv ...
- 锁定项目的 node 版本
一些老项目对 node 版本是有要求的,往往使用默认的新版本包安装不上,scripts 也跑不起来. 之前就遇到过运行一个小程序项目时,根据文档来,第一步安装就出错.本着办法总比问题多的理念,来一个解 ...
- OAuth 2.0 了解了,OAuth 2.1 呢?
OAuth 2.0 OAuth 2.0 是工业级标准授权协议. OAuth 2.0 聚焦于客户端开发者便利性,为网页应用程序.桌面客户端.手机.客厅设备提供特定的授权流程. RFC6749 OAuth ...
- 02- web UI测试与UI Check List
UI英文是 user interface .所以UI测试就是用户界面测试. Web UI测试 用户界面测试:user interface testing,UI Testing指软件中的可见外观及其与用 ...
- 基于Docker安装的MindSpore-1.2 GPU版本
技术背景 在前面一篇博客中,我们介绍过MindSpore-CPU版本的Docker部署以及简单的案例测试,当时官方还不支持GPU版本的Docker容器化部署.经过MindSpore团队的努力,1.2. ...
- php文件的自动加载
<?php spl_autoload_register(function ($class_name) { require_once $class_name . '.php'; });
- hdu4278 小想法
题意: 有几个计数器,从1开始计数,计数器有问题,没有3,8这两个数字,只要出现3或者8,那么直接跳过,如 12579 下一个数字就是 12590 ,给你一个数字,问他实际计数了多少. 思 ...