利用共享内存实现比NCCL更快的集合通信
作者:曹彬 | 旷视 MegEngine 架构师
简介
从 2080Ti 这一代显卡开始,所有的民用游戏卡都取消了 P2P copy,导致训练速度显著的变慢。针对这种情况下的单机多卡训练,MegEngine 中实现了更快的集合通信算法,对多个不同的网络训练相对于 NCCL 有 3% 到 10% 的加速效果。
MegEngine v1.5 版本,可以手动切换集合通信后端为 shm(默认是 nccl),只需要改一个参数。(由于 shm 模式对 CPU 有额外的占用,且只有在特定卡下才能提高效率,因此并没有默认打开)
gm = GradManager()
gm.attach(model.parameters(), callbacks=[dist.make_allreduce_cb("sum", backend="shm")])
目前只实现了单机版本,多机暂不支持
背景
在大规模训练中,数据并行是最简单最常见的训练方式,每张卡运行完全一样的网络结构,然后加上参数同步就可以了。
对于 数据并行的参数同步,目前有两种常用的方法,Parameter Server 和 Gradient AllReduce:
- Parameter Server 方案需要额外机器作为参数服务器来更新参数,而且中心式的通讯方式对带宽的压力很大,增加训练机器的同时通信量也线性增加;
- 而 AllReduce 方案只是参与训练的机器之间互相同步参数,不需要额外的机器,可扩展性好。
MegEngine 目前也是使用 AllReduce 方案作为数据并行的参数同步方案。而在 AllReduce 方案中,大家目前常用的是 NCCL,Nvidia 自家写的 GPU 集合通讯库,通信效率很高。
看到这里,可以得到一个结论,数据并行的情况,用 NCCL 通讯库能达到不错的效果。
到这里就结束了?当然不是,在 2080Ti 8 卡训练的情况下,在多个网络下,我们相对 NCCL 有 3% 到 10% 的性能提升。(以 2080Ti 为例子是因为游戏卡不支持 P2P 通信,相对来说通信较慢,通信时间长,节省通信时间能获得的收益较大)

这是怎么做到的呢,我们一步一步来分析(以下数据都是用 megengine.utils.profiler 导出,相关文档在 profiler文档)。
通常我们是在 backward 阶段同时做 gradient 的同步,我们来看单卡的 backward 耗时,只有 164ms:

再来看 8 卡训练时 backward 的耗时,增长到了 203ms,比单卡的情况下多了 39ms:
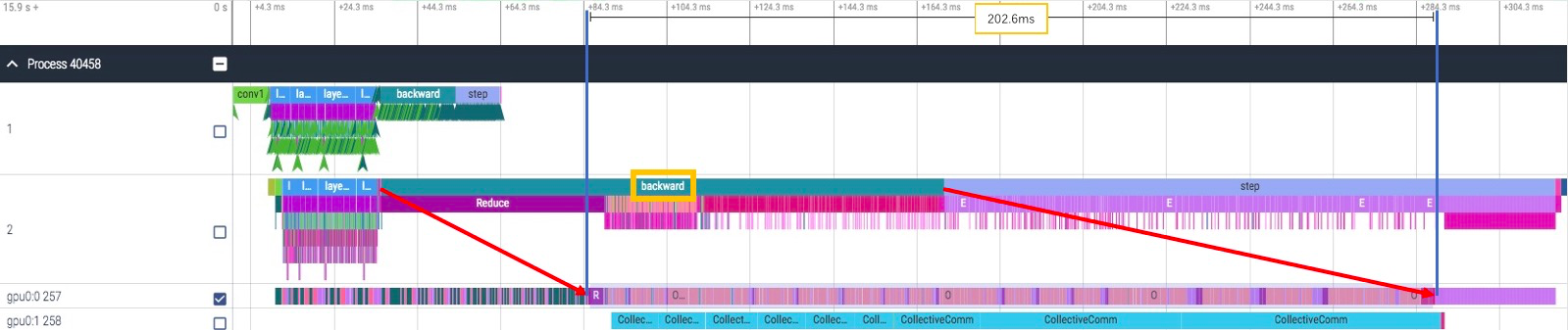
确实,backward 时间变长了不少,可是为什么?我们有没有可能消除它?
1)为什么
一句话:NCCL AllReduce 占用了 cuda 计算资源,所以计算变慢。
具体原因是 NCCL AllReduce 对应的 cuda kernel 需要既做通信又做计算,所以占用了计算对应需要的计算资源,但是大部分时间都花在了通信上,导致计算资源的利用率不够高。
2)能不能消除它
当然是可以的,cuda 计算和通信是可以并行的,让计算和通信运行在两个不同的 cuda stream 上,就可以并行起来,这一点在 cuda 开发者文档中有提到。
3)实际测试计算和通信并行的例子
stream0 进行矩阵乘法运算,stream1 进行拷贝,前后矩阵乘法的速度没有受到影响:

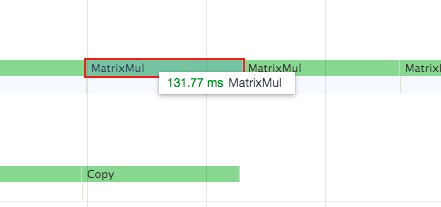
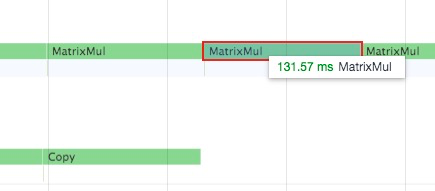
实现思路
这里先介绍一下 AllReduce 的两种实现方法。
1)ReduceScatter + AllGather
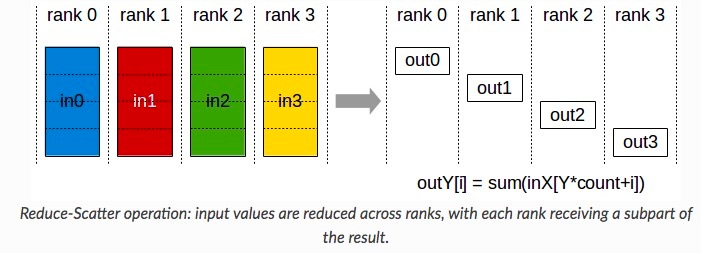
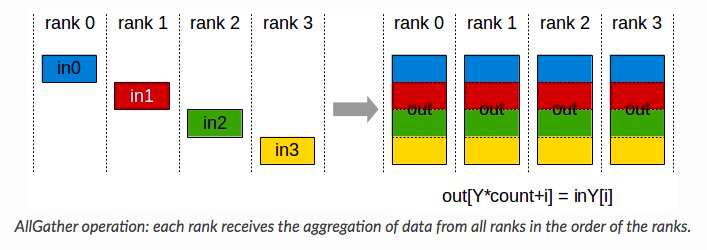
Ring AllReduce 就是用的 ReduceScatter + AllGather 的模式:首先第一轮通信在各个节点上计算出部分和,然后第二轮通信把部分和聚集一下得到最终结果。
2)Reduce + Broadcast
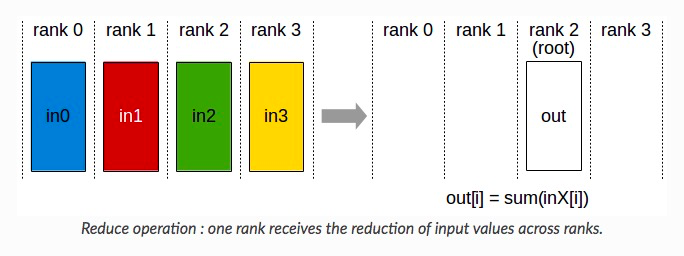
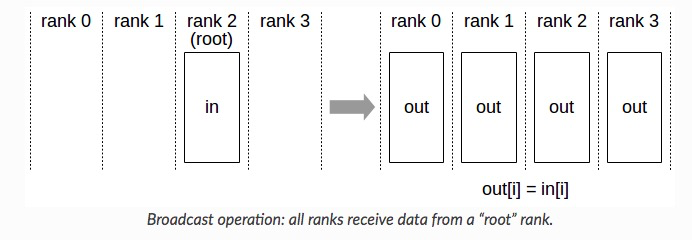
Reduce + Broadcast 的方式像 Parameter Server,会先在一个节点计算出完整的累加和,然后再广播到各个节点上。
新的算法采用的是 Reduce + Broadcast 的方法,首先将数据全部拷贝到 cpu(使用 Shared Memory),然后由 cpu 进行累加,再拷贝回 gpu。
由于直接拷贝累加没有把计算和通信 overlap 起来,我们还采用了类似 Ring AllReduce 的分块策略,让通信和计算充分 overlap,如下图所示。
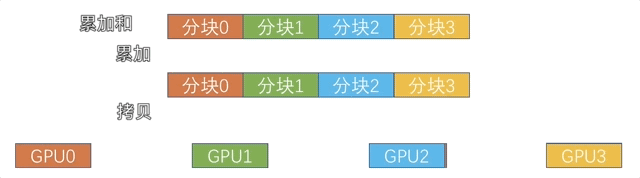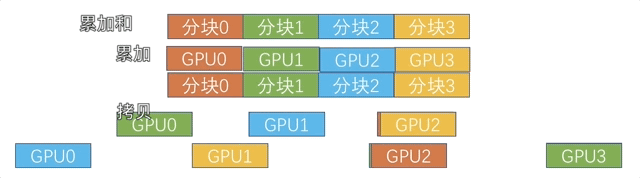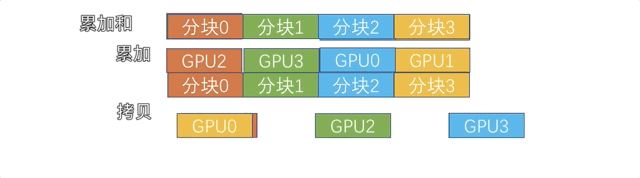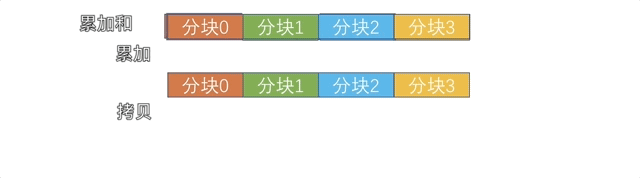
因为用到了 Shared Memory,所以把这个后端简称为 SHM。
实现效果
1)算子性能
相对 NCCL 来说,SHM 的延迟稍微高了一些,带宽低了一些,数据大一些的情况可以达到 NCCL 的 90% 左右的性能。
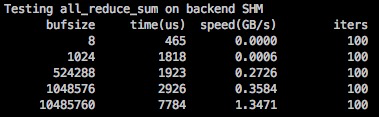
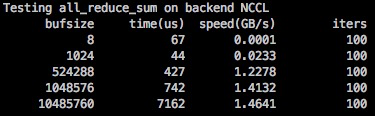
SHM 性能需要在数据包大的情况发挥,和 ParamPack 策略搭配能最大发挥 SHM 的作用(在 MegEngine 中 distributed.make_allreduce_cb 中使用了 ParamPack 策略, 默认打包大小为 10M)。ParamPack 策略是指将参数对应的梯度打包进行发送,减少小包发送,以减少通信延迟增加带宽利用率。
2)实际训练效果
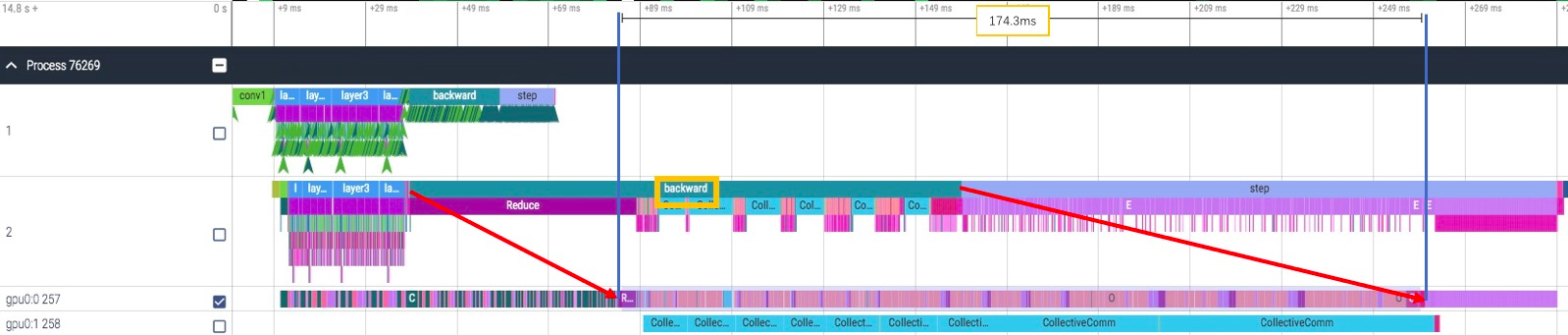
继续使用 ResNet50 8卡训练的例子,SHM 与 NCCL 相比,backward 时间快了近 30ms(203ms->174ms)。
Shared Memory AllReduce 的不足之处/后续改进
1)cpu 占用多
因为占用了 cpu 资源做 reduce 运算,所以在 cpu 资源紧张的情况下会比较慢,需要确定 cpu 资源是否够用再进行使用。
2)额外通信成本
因为 copy 和 reduce 之间有数据依赖关系,copy需要等待上一次的reduce完成才能开始,reduce要等待copy数据就位才能开始,所以中间插入了信号量的同步,引入了额外的通信成本,在分块越多的情况越明显。
3)多进程负载均衡
各个进程的 copy 和 reduce 速度不一致导致了进度不同步的问题,会造成多余的等待时间,根据实际运行速度进行分配任务性能会有进一步的提升。
4)更多的 overlap
目前只用到了 copy 和 reduce 之间的 overlap,但是其实 h2d 和 d2h 拷贝也是可以 overlap 起来的,可以有进一步加速。
利用共享内存实现比NCCL更快的集合通信的更多相关文章
- Windows中利用共享内存来实现不同进程间的通信
Windows中利用共享内存来实现不同进程间的通信 一.msdn详细介绍 https://docs.microsoft.com/zh-cn/windows/win32/memory/sharing-f ...
- [转]Windows环境下利用“共享内存”实现进程间通信的C/C++代码---利用CreateFileMapping和MapViewOfFile
http://blog.csdn.net/stpeace/article/details/39534361 进程间的通信方式有很多种, 上次我们说了最傻瓜的“共享外存/文件”的方法. 那么, 在本文中 ...
- 进程间通信机制(管道、信号、共享内存/信号量/消息队列)、线程间通信机制(互斥锁、条件变量、posix匿名信号量)
注:本分类下文章大多整理自<深入分析linux内核源代码>一书,另有参考其他一些资料如<linux内核完全剖析>.<linux c 编程一站式学习>等,只是为了更好 ...
- 学习笔记:Linux下共享内存的方式实现进程间的相互通信
一.常用函数 函数系列头文件 #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> ft ...
- 『Numpy』内存分析_利用共享内存创建数组
引.内存探究常用函数 id(),查询对象标识,通常返回的是对象的地址 sys.getsizeof(),返回的是 这个对象所占用的空间大小,对于数组来说,除了数组中每个值占用空间外,数组对象还会存储数组 ...
- v76.01 鸿蒙内核源码分析(共享内存) | 进程间最快通讯方式 | 百篇博客分析OpenHarmony源码
百篇博客分析|本篇为:(共享内存篇) | 进程间最快通讯方式 进程通讯相关篇为: v26.08 鸿蒙内核源码分析(自旋锁) | 当立贞节牌坊的好同志 v27.05 鸿蒙内核源码分析(互斥锁) | 同样 ...
- 共享内存是最快的一种IPC方式
在linux进程间通信的方式中,共享内存是一种最快的IPC方式.因此,共享内存用于实现进程间大量的数据传输,共享内存的话,会在内存中单独开辟一段内存空间,这段内存空间有自己特有的数据结构,包括访问权限 ...
- IPC最快的方式----共享内存(shared memory)
在linux进程间通信的方式中,共享内存是一种最快的IPC方式.因此,共享内存用于实现进程间大量的数据传输,共享内存的话,会在内存中单独开辟一段内存空间,这段内存空间有自己特有的数据结构,包括访问权限 ...
- 利用windows api共享内存通讯
主要涉及CreateFile,CreateFileMapping,GetLastError,MapViewOfFile,sprintf,OpenFileMapping,CreateProcess Cr ...
随机推荐
- Bootstrap中宽度大于指定宽度时有空白的解决方法
<div class="container-fluid"></div> 其中container-fluid的作用是占100%
- 动态路由协议与RIP配置
一.动态路由的概述 二.RIP路由协议工作原理 三.水平分割 四.RIP路由协议v1与v2的区别 五.实验配置 一.动态路由的概述 1.定义 动态路由是指利用路由器上运行的动态路由协议定期和其他路由器 ...
- excel VBA使用教程
1.选择文件--选项 2.选择自定义功能区--开发工具的√勾上
- 关于Excel中表格转Markdown格式的技巧
背景介绍 Excel文件转Markdown格式的Table是经常会遇到的场景. Visual Studio Code插件 - Excel to Markdown table Excel to Mark ...
- .Net Core with 微服务 - Consul 配置中心
上一次我们介绍了Elastic APM组件.这一次我们继续介绍微服务相关组件配置中心的使用方法.本来打算介绍下携程开源的重型配置中心框架 apollo 但是体系实在是太过于庞大,还是让我爱不起来.因为 ...
- php解决约瑟夫环
今天偶遇一道算法题 "约瑟夫环"是一个数学的应用问题:一群猴子排成一圈,按1,2,-,n依次编号.然后从第1只开始数,数到第m只,把它踢出圈,从它后面再开始数, 再数到第m只,在把 ...
- HGAME_easyVM
64位的exe,拖入ida64静态分析一波. 一.先是一大堆的赋值语句,有点懵,后面在分析handler的时候,也直接导致了我卡壳,这里还是得注意一下这些局部变量都是临近的,所以可以直接看成一个连续数 ...
- buu crypto 幂数加密
一.这和二进制幂数加密有些不同,可以从数字大小判断出来,超过4了,一般4以上已经可以表达出31以内了,所以是云影密码,以0为分隔符,01248组成的密码 二.python代码解密下 code=&quo ...
- Activiti7 与 Spring Boot 及 Spring Security 整合 踩坑记录
1. 前言 实话实说,网上关于Activiti的教程千篇一律,有参考价值的不多.很多都是老早以前写的,基本都是直接照搬官方提供的示例,要么就是用单元测试跑一下,要么排除Spring Security ...
- STM32笔记二
1.STM32编程通常有两种方法:一种是寄存器编程,另外一种是固件库编程.寄存器编程是基础,而固件库是寄存器编程的基础上升级而来的编程方法,是需要重点掌握的编程方法. 2.STM32F103采用的是C ...