ReplacingMergeTree:实现Clickhouse数据更新
摘要:Clickhouse作为一个OLAP数据库,它对事务的支持非常有限。本文主要介绍通过ReplacingMergeTree来实现Clickhouse数据的更新、删除。
本文分享自华为云社区《Clickhouse如何实现数据更新》,作者: 小霸王。
Clickhouse作为一个OLAP数据库,它对事务的支持非常有限。Clickhouse提供了MUTATION操作(通过ALTER TABLE语句)来实现数据的更新、删除,但这是一种“较重”的操作,它与标准SQL语法中的UPDATE、DELETE不同,是异步执行的,对于批量数据不频繁的更新或删除比较有用,可参考https://altinity.com/blog/2018/10/16/updates-in-clickhouse。除了MUTATION操作,Clickhouse还可以通过CollapsingMergeTree、VersionedCollapsingMergeTree、ReplacingMergeTree结合具体业务数据结构来实现数据的更新、删除,这三种方式都通过INSERT语句插入最新的数据,新数据会“抵消”或“替换”掉老数据,但是“抵消”或“替换”都是发生在数据文件后台Merge时,也就是说,在Merge之前,新数据和老数据会同时存在。因此,我们需要在查询时做一些处理,避免查询到老数据。Clickhouse官方文档提供了使用CollapsingMergeTree、VersionedCollapsingMergeTree的指导,https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/collapsingmergetree/。相比于CollapsingMergeTree、VersionedCollapsingMergeTree需要标记位字段、版本字段,用ReplacingMergeTree来实现数据的更新删除会更加方便,这里着重介绍一下如何用ReplacingMergeTree来实现数据的更新删除。
我们假设一个需要频繁数据更新的场景,如某市用户用电量的统计,我们知道,用户的用电量每分每秒都有可能发生变化,所以会涉及到数据频繁的更新。首先,创建一张表来记录某市所有用户的用电量。
CREATE TABLE IF NOT EXISTS default.PowerConsumption_local ON CLUSTER default_cluster
(
User_ID UInt64 COMMENT '用户ID',
Record_Time DateTime DEFAULT toDateTime(0) COMMENT '电量记录时间',
District_Code UInt8 COMMENT '用户所在行政区编码',
Address String COMMENT '用户地址',
Power UInt64 COMMENT '用电量',
Deleted BOOLEAN DEFAULT 0 COMMENT '数据是否被删除'
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/default.PowerConsumption_local/{shard}', '{replica}', Record_Time)
ORDER BY (User_ID, Address)
PARTITION BY District_Code;
CREATE TABLE default.PowerConsumption ON CLUSTER default_cluster AS default.PowerConsumption_local
ENGINE = Distributed(default_cluster, default, PowerConsumption_local, rand());
PowerConsumption_local为本地表,PowerConsumption为对应的分布式表。其中PowerConsumption_local使用ReplicatedReplacingMergeTree表引擎,第三个参数‘Record_Time’表示相同主键的多条数据,只会保留Record_Time最大的一条,我们正是利用ReplacingMergeTree的这一特性来实现数据的更新删除。因此,在选择主键时,我们需要确保主键唯一。这里我们选择(User_ID, Address)来作为主键,因为用户ID加上用户的地址可以确定唯一的一个电表,不会出现第二个相同的电表,所以对于某个电表多条数据,只会保留电量记录时间最新的一条。
然后我们向表中插入10条数据:
INSERT INTO default.PowerConsumption VALUES (0, '2021-10-30 12:00:00', 3, 'Yanta', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (1, '2021-10-30 12:10:00', 2, 'Beilin', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (2, '2021-10-30 12:15:00', 1, 'Weiyang', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (3, '2021-10-30 12:18:00', 1, 'Gaoxin', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (4, '2021-10-30 12:23:00', 2, 'Qujiang', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (5, '2021-10-30 12:43:00', 3, 'Baqiao', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (6, '2021-10-30 12:45:00', 1, 'Lianhu', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (7, '2021-10-30 12:46:00', 3, 'Changan', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (8, '2021-10-30 12:55:00', 1, 'Qianhan', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (9, '2021-10-30 12:57:00', 4, 'Fengdong', rand64() % 1000 + 1, 0);
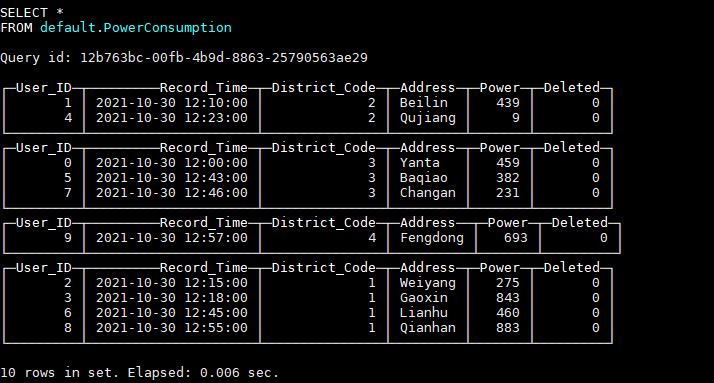
表中数据如图所示:
假如现在我们要行政区编码为1的所有用户数据都需要更新,我们插入最新的数据:
INSERT INTO default.PowerConsumption VALUES (2, now(), 1, 'Weiyang', rand64() % 100 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (3, now(), 1, 'Gaoxin', rand64() % 100 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (6, now(), 1, 'Lianhu', rand64() % 100 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (8, now(), 1, 'Qianhan', rand64() % 100 + 1, 0);
插入最新数据后,表中数据如图所示:
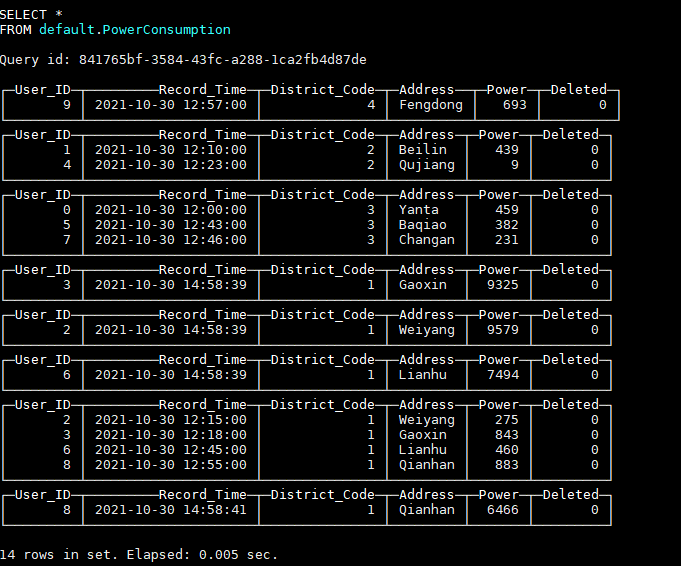
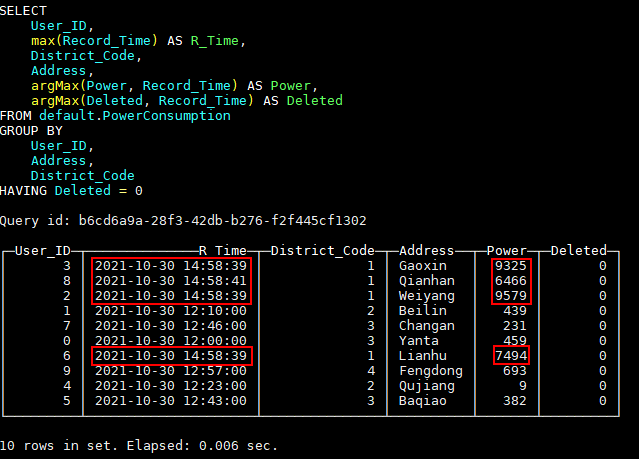
可以看到,此时新插入的数据与老数据同时存在于表中,因为后台数据文件还没有进行Merge,“替换”还没有发生,这时就需要对查询语句做一些处理来过滤掉老数据,函数argMax(a, b)可以按照b的最大值取a的值,所以通过如下查询语句就可以只获取到最新数据:
SELECT
User_ID,
max(Record_Time) AS R_Time,
District_Code,
Address,
argMax(Power, Record_Time) AS Power,
argMax(Deleted, Record_Time) AS Deleted
FROM default.PowerConsumption
GROUP BY
User_ID,
Address,
District_Code
HAVING Deleted = 0;
查询结果如下图:
为了更方便我们查询,这里可以创建一个视图:
CREATE VIEW PowerConsumption_view ON CLUSTER default_cluster AS
SELECT
User_ID,
max(Record_Time) AS R_Time,
District_Code,
Address,
argMax(Power, Record_Time) AS Power,
argMax(Deleted, Record_Time) AS Deleted
FROM default.PowerConsumption
GROUP BY
User_ID,
Address,
District_Code
HAVING Deleted = 0;
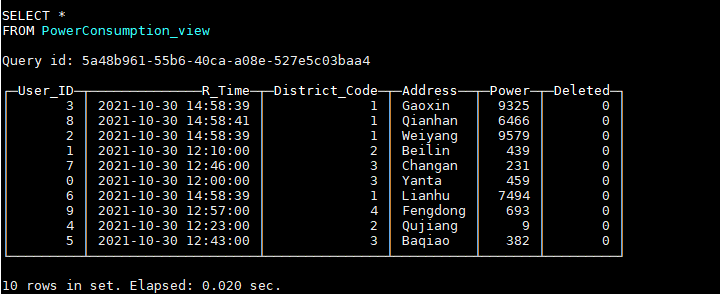
通过该视图,可以查询到最新的数据:
假如现在我们又需要删除用户ID为0的数据,我们需要插入一条User_ID字段为0,Deleted字段为1的数据:
INSERT INTO default.PowerConsumption VALUES (0, now(), 3, 'Yanta', null, 1);
查询视图,发现User_ID为0的数据已经查询不到了:
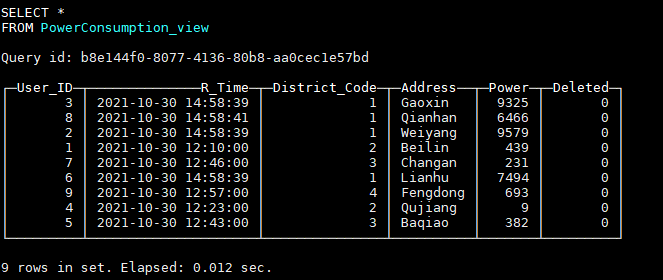
通过如上方法,我们可以实现Clickhouse数据的更新、删除,就好像在使用OLTP数据库一样,但我们应该清楚,实际上老数据真正的删除是在数据文件Merge时发生的,只有在Merge后,老数据才会真正物理意义上的删除掉。
ReplacingMergeTree:实现Clickhouse数据更新的更多相关文章
- ClickHouse(10)ClickHouse合并树MergeTree家族表引擎之ReplacingMergeTree详细解析
目录 建表语法 数据处理策略 资料分享 参考文章 MergeTree拥有主键,但是它的主键却没有唯一键的约束.这意味着即便多行数据的主键相同,它们还是能够被正常写入.在某些使用场合,用户并不希望数据表 ...
- clickhouse核心引擎MergeTree子引擎
在clickhouse使用过程中,针对数据量和查询场景,MergeTree是最常用也是较为合适的表引擎.针对特定的业务,MergeTree的子引擎可以针对不同的业务而定,但都基于MergeTree引擎 ...
- clickhouse入门到实战及面试
第一章. clickhouse入门 一.ClickHouse介绍 ClickHouse(开源)是一个面向列的数据库管理系统(DBMS),用于在线分析处理查询(OLAP). 关键词:开源.面向列.联机分 ...
- 彪悍开源的分析数据库-ClickHouse
https://zhuanlan.zhihu.com/p/22165241 今天介绍一个来自俄罗斯的凶猛彪悍的分析数据库:ClickHouse,它是今年6月开源,俄语社区为主,好酒不怕巷子深. 本文内 ...
- Clickhouse v18编译记录
简介 ClickHouse是"战斗民族"俄罗斯搜索巨头Yandex公司开源的一个极具"战斗力"的实时数据分析数据库,是面向 OLAP 的分布式列式DBMS,圈内 ...
- Linux系统:Centos7下搭建ClickHouse列式存储数据库
本文源码:GitHub·点这里 || GitEE·点这里 一.ClickHouse简介 1.基础简介 Yandex开源的数据分析的数据库,名字叫做ClickHouse,适合流式或批次入库的时序数据.C ...
- ClickHouse
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告 1 安装前的准备1.1 Cent ...
- Clickhouse单机部署以及从mysql增量同步数据
背景: 随着数据量的上升,OLAP一直是被讨论的话题,虽然druid,kylin能够解决OLAP问题,但是druid,kylin也是需要和hadoop全家桶一起用的,异常的笨重,再说我也搞不定,那只能 ...
- clickhouse数据库
https://www.jianshu.com/p/a5bf490247ea https://www.cnblogs.com/davygeek/p/8018292.html 开源分布式数据库 htt ...
随机推荐
- TP5数据库数据变动日志记录设计
根据网友的设计进行了部分调整: 用户分为管理员admin表和用户user表 记录操作表数据 增删改: insert/delete/update <?php /** * OperateLog.ph ...
- Docker系列(12)- 部署Tomcat
#官方的使用:我们之前的启动都是后台,停止容器后,容器还是可以看到#docker run -it --rm,一般用来测试,用完就会删除容器,镜像还在[root@localhost ~]# docker ...
- Groovy系列(5)- Groovy IO操作
IO操作 Groovy为I/O操作提供了许多帮助方法,虽然你可以在Groovy中用标准Java代码来实现I/O操作,不过Groovy提供了大量的方便的方式来操作File.Stream.Reader等等 ...
- 鸿蒙源码分析系列(总目录) | 百万汉字注解 百篇博客分析 | 深入挖透OpenHarmony源码 | v8.23
百篇博客系列篇.本篇为: v08.xx 鸿蒙内核源码分析(总目录) | 百万汉字注解 百篇博客分析 | 51.c.h .o 百篇博客.往期回顾 在给OpenHarmony内核源码加注过程中,整理出以下 ...
- P6222-「P6156 简单题」加强版【莫比乌斯反演】
正题 题目链接:https://www.luogu.com.cn/problem/P6222 题目大意 给出\(k\),\(T\)组询问给出\(n\)求 \[\sum_{i=1}^n\sum_{j=1 ...
- AT2567-[ARC074C]RGB Sequence【dp】
正题 题目链接:https://www.luogu.com.cn/problem/AT2567 题目大意 长度为\(n\)的包含三种颜色\(RGB\)的序列,\(m\)个限制\([l,r,k]\)表示 ...
- Python如何连接Mysql及基本操作
什么要做python连接mysql,一般是解决什么问题的 做自动化测试时候,注册了一个新用户,产生了多余的数据,下次同一个账号就无法注册了,这种情况怎么办呢?自动化测试都有数据准备和数据清理的操作,如 ...
- GoLang设计模式08 - 命令模式
命令模式是一种行为型模式.它建议将请求封装为一个独立的对象.在这个对象里包含请求相关的全部信息,因此可以将其独立执行. 在命令模式中有如下基础组件: Receiver:唯一包含业务逻辑的类,命令对象会 ...
- Python:PNG图像生成MP4
Python:PNG图像生成MP4 需求 需要将多张*.PNG图像,生成mp4格式的视频文件. 实现 利用Python中image库生成*.gif格式图像,但是图片未经压缩,文件体量较大. movie ...
- mysql安装教程,mysql安装配置教程
MySQL的安装教程 一.MYSQL的安装 首先登入官网下载mysql的安装包,官网地址:https://dev.mysql.com/downloads/mysql/ 一般下载这个就好,现在的最新版本 ...