jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库
——jieba库!
这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚至是根据猜测的词义形成字典!
这么好用的库不去了解实在是可惜啊!!!
那么第一步,我们当然是先安装它了!
步骤很简单!
就是我们以往的cmd命令行安装即可;
接下来让我们了解一下它的基本语法吧!
jieba库有三个基本的模式:精确模式、全模式、搜索引擎模式
精确模式:试图将语句最精确的切分,不存在冗余数据,适合做文本分析
全模式:将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据
搜索引擎模式:在精确模式的基础上,对长词再次进行切分
于是我们来尝试一下:
第一步:首先是精准模式:
上图

哇!!真的可以准确地分词诶!!不过……我知道我可以很伟大……但也没必要拆了我名字把……哈哈哈哈
第二步:全模式

哟~好吧,我用亲生经历告诉大家,其实这jieba库还是有它识别的局限的,我现在又“伟大”,又“大帅”了哈哈哈
不过我发现,该模式下,一个标点符号后就会多出“//”来区分断点,而且少掉了标点符号,显然它是对主体的词汇进行操作了!
第三步:搜索引擎模式
虽然不知道是什么模式,不过听上去就很高大上!
不多说,先试!

emmm……看这输出结果我并不能看出与第一步模式有什么不同,也许我还得深入研究!
接下来我看可以开始一些简单的应用了,
下面贴一段代码:
def get_text():
txt = open("NEWS.txt", "r", encoding='UTF-8').read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格
return txt file_txt = get_text()
words = file_txt.split() # 对字符串进行分割,获得单词列表
counts = {} for word in words:
if len(word) == :
continue
else:
counts[word] = counts.get(word, ) + items = list(counts.items())
items.sort(key=lambda x: x[], reverse=True) for i in range():
word, count = items[i]
print("{0:<5}->{1:>5}".format(word, count))
很显然,我在桌面上放了一个名为“NEWS”的txt文件(其实是Python目录里的一个说明的一部分哈哈哈),然后用着代码去计算里面一些长度的词的个数(该代码适合英文)
结果是:

挺好用!
当然,在这里介绍的只是一些初步,jieba库还有好多值得一试的好玩功能,你甚至可以结合字典,搜索关键字等等……
接下来!!!是词云部分的制作!
虽然我们有很多词云自动生成的网站,但是自己编写出来的可运行程序会不会更加有成就感呢!
有一种形式:
(1)打开taglue官网,点击import words,把运行的结果copy过来。
(2)选择形状,在这里是网上下载的图片进行的导入。
(3)选择字体。
(4)点击Visualize生成图片。
当然啦~其实这也不是什么高深莫测的题目,我们可是拥有强大的第三方python库的啊!!wordcloud——你值得拥有!
一样滴先cmd安装,接着还有确保jieba库和matploylib的安装
下面是代码实现:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba def create_word_cloud(filename):
text = open("百年孤独.txt".format(filename)).read() wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist) wc = WordCloud(
background_color="black",
max_words=,
font_path='simsun.ttf',
height=,
width=,
max_font_size=,
random_state=,
) myword = wc.generate(wl)
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('img_book.png') if __name__ == '__main__':
create_word_cloud('mytext')
通过放在桌面的《百年孤独》文本搜索素材
效果如图:
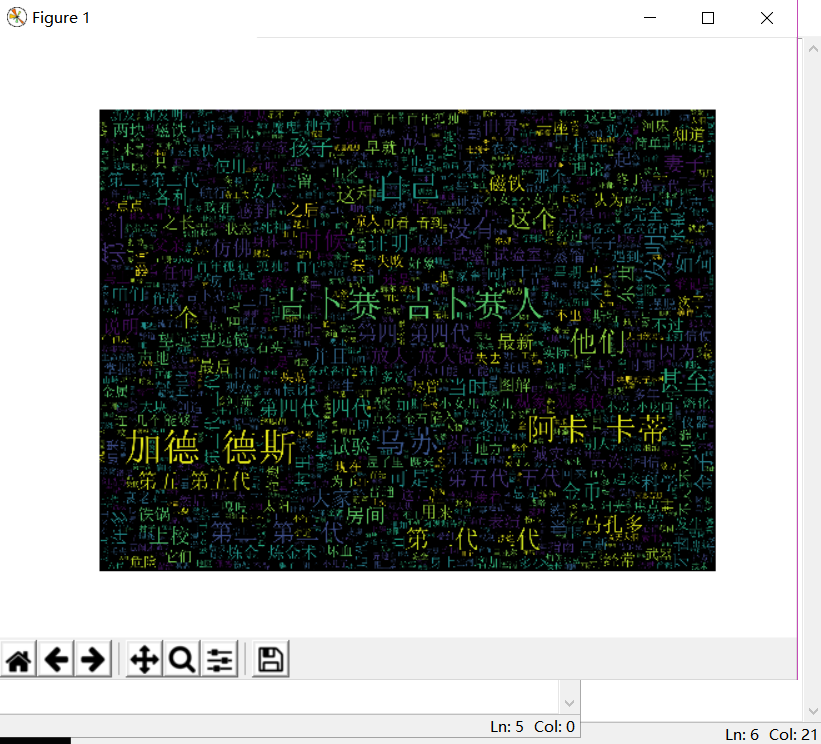
我还发现了下面的按钮还有一些比较好玩的功能比如调节大小

在这个数值下会覆盖全框哦!
是不是很赞呢~快去自己试试看怎么实现吧~~
jieba库与好玩的词云的学习与应用实现的更多相关文章
- jieba库和好玩的词云
首先,通过pip3 install jieba安装jieba库,随后在网上下载<斗破>. 代码如下: import jieba.analyse path = '小说路径' fp = ope ...
- jieba库的使用与词云
一.准备 在制作词云之前我们需要自行安装三个库,它们分别是:jieba, wordcloud, matplotlib 安装方法基本一致,下面我以安装wordcloud的过程为例. 第一步,按下Win+ ...
- python jieba 库分词结合Wordcloud词云统计
import jieba jieba.add_word("福军") jieba.add_word("少安") excludes={"一个", ...
- jieba 库的使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- Jieba库使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- jieba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jirba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
随机推荐
- 风火轮SMC532使用
2018年3月份申请了一个院创,要做一个基于NFC技术的考勤设备,想法是用手机的NFC将学号信息传导考勤机,由考勤机统计缺勤信息,因为自己的拖延症,一直拖到现在.现在一边写毕业论文一边准备院创答辩,又 ...
- springmvc 开发流程图
- Quartz.NET 入门(转)
概述 Quartz.NET是一个开源的作业调度框架,非常适合在平时的工作中,定时轮询数据库同步,定时邮件通知,定时处理数据等. Quartz.NET允许开发人员根据时间间隔(或天)来调度作业.它实现了 ...
- ABP core学习之二 IIS部署.NET CORE
本文是关于IIS部署.NET CORE的总结,以后有碰到问题将陆续添加 IIS部署.NET CORE总结 一.服务器环境 首先确定自己项目的core版本,然后下载对应的包在服务器上安装 下载地址: h ...
- 算法——八皇后问题(eight queen puzzle)之回溯法求解
八皇后谜题是经典的一个问题,其解法一共有种! 其定义: 首先定义一个8*8的棋盘 我们有八个皇后在手里,目的是把八个都放在棋盘中 位于皇后的水平和垂直方向的棋格不能有其他皇后 位于皇后的斜对角线上的棋 ...
- MAC本apache+php配置虚拟域名时踩的坑
昨天在调试Mac自带的Apache+PHP配置域名时,调试的让我怀疑人生.顿时心里一万个草泥马,我就是配置个虚拟域名啊,这么让我受伤 . 1 首先检查一下Apache是否开启, qutao@bogon ...
- 推荐前端开发手机调试打印神器console.log()
下面说的这个插件很牛,相信很多人都不知道,但找问题的时候很需要,直接上干货如下: vConsole:一个轻量.可拓展.针对手机网页的前端开发者调试面板. 下载 vConsole 的最新版本.(不要直接 ...
- 【Git】git rebase报错new blank line at EOF.处理
执行git rebase报错如下: First, rewinding head to replay your work on top of it... Applying: 本次提交信息 .git/re ...
- Python3学习十四
1. JS基本概念 网景和sun联合开发javascript javascript 三个部分:ECMAScript 语法 DOM(document object model) BOM(b ...
- python Request模块
---恢复内容开始--- Request的五种请求方式: request.get() request.post() request.head() requst.put() request.patch( ...