『高性能模型』HetConv: HeterogeneousKernel-BasedConvolutionsforDeepCNNs
论文地址:HetConv
一、现有网络加速技术
1、卷积加速技术
作者对已有的新型卷积划分如下:标准卷积、Depthwise 卷积、Pointwise 卷积、群卷积(相关介绍见『高性能模型』深度可分离卷积和MobileNet_v1),后三种卷积可以取代标准卷积,使用方式一般是 Depthwise + Pointwise 或者是 Group + Pointwise 这样的两层取代(已有网络架构中的)标准卷积的一层,成功的在不损失精度的前提下实现了 FLOPs 提升,但是带来副作用是提高了网络延迟(latency),所谓 latency 直观来说就是网络的层数增加了,由于GPU加速、并行计算要求前一层的结果出来后后一层才能开始运算,所以层数加多并不利于这些工具,作者使用 latency 衡量这一因素。
2、网络压缩技术
模题型压缩作者认为主要成果有:connection pruning 、filter pruning 和 quantization(量子化),其中作者认为 filter pruning 比较主流(花了一定篇幅介绍),且不需要特殊的硬件/软件才能实现,但其问题在于:
a、训练步骤繁琐
b、存在精度损失
其一般步骤是:训练好原模型;对模型参数权重进行分析;裁剪模型参数;重新(迭代)训练弥补精度损失。可以看到十分繁琐,这里多说一句,因为我并不太了解模型剪枝,简单的调研了一下,其原理是我们假设模型参数绝对值越大则其约重要,所以对一个卷积核种所有值的绝对值进行求和,然后排序就知道哪些核不重要了(Pruning filters for efficient convnets)。
3、重看网络加速问题
我们上面提到的都是对已有网络进行加速,或者是剪枝,或者是替换,实际上网络加速有两个大方向:
a、妥协网络精度,目的是在低端硬件上运行,在精度和准确率之间寻求平衡点,一般会重新设计一个网络结构
b、保持网络 FLOPs 不变,突破精度,一般体现在对现有网络进行更复杂化的改造升级
作者基于以上两种思路的共同诉求,提出了新的 HetConv(多相卷积),以同一个卷积层内的 filter 大小不再一致为创新点,达到即降低 FLOPs 又不损失精度的效果。
相比已有卷积加速技术 HetConv 对标准卷积是1换1的过程,不会带来 latency;相比网络剪枝,训练时常大大缩短,训练精度不会打折。
二、HetConv
1、原理介绍
HetConv 的核由3*3以及1*1两种组成,将全部卷积核划分为若干组,每组除含有一个3*3的核外其他均为1*1的核。下图所示为相同的核数(M)不同的每组中的核数(P)的 HetConv 层对比示意,对比对象为相应层中的某个卷积核。注意理解 P 的意义,后面将会大量参考此参数。
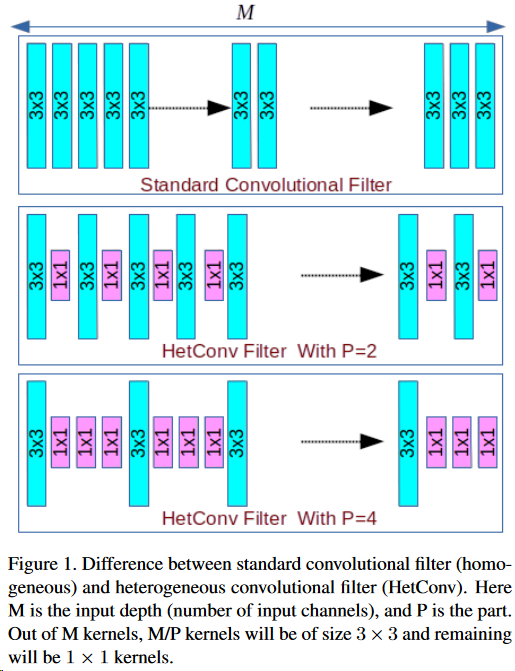
当然,如果某一层的卷积核们完全一致这个网络的语义信息很明显是有问题的,所以单层的核实际分布如下:
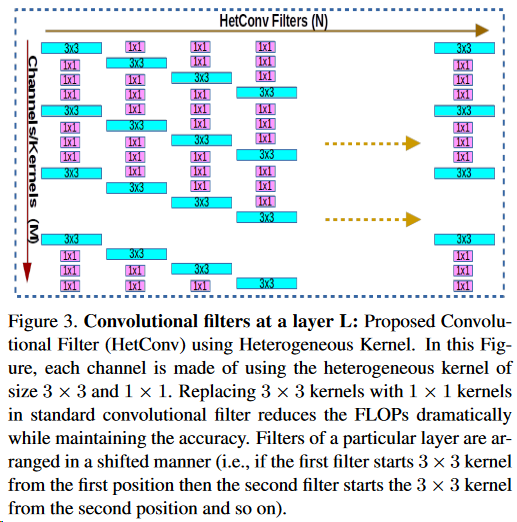
这样看来我们就很熟悉了:将 Depthwise 和 Pointwise 融合到同一层中,当然这个说法不完全准确,不过其设计思路应该就是这样。
2、性能分析
之后作者分别对比了 D+P、G+P 和 HetConv 的复杂度,计算过程很简单(对卷积复杂度实在不熟悉的话参见:『高性能模型』卷积复杂度以及Inception系列),且个人觉得计算过程有瑕疵以及对比方式不是很有说服力,故感兴趣的话看原文第3节吧。
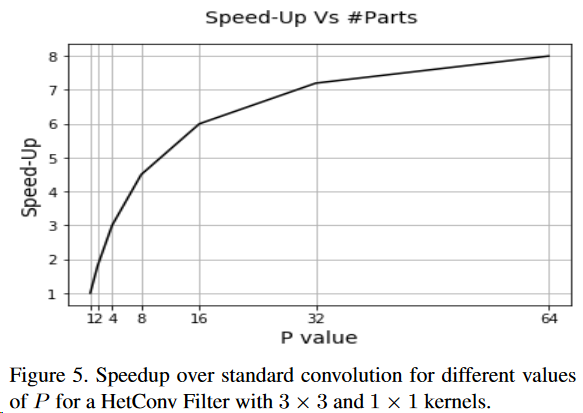
最后作者说每组中核心数(P)越大加越快,符合直觉:
3、个人杂谈
个人感觉这个卷积设计应该能够起到加速作用(相对已有方法),但是准确度不太相信能够如作者所说媲美 D+P 、 G+P 或者标准卷积,所以本文将贴出作者的实验分析,且想看看后续是否有人验证其实用性。另外感觉实现起来有点麻烦(不修改框架源码的话),创建3*3的核并置零1*1的空余位好说,如何高效的锁定其值为0感觉现有 API 实现比较麻烦(每次更新参数后修改一次太低效了),哎,源码苦手。不过要是这个东西真的有用,后续各大框架都会跟进就是了。
三、实验分析
VGG-16 on CIFAR-10
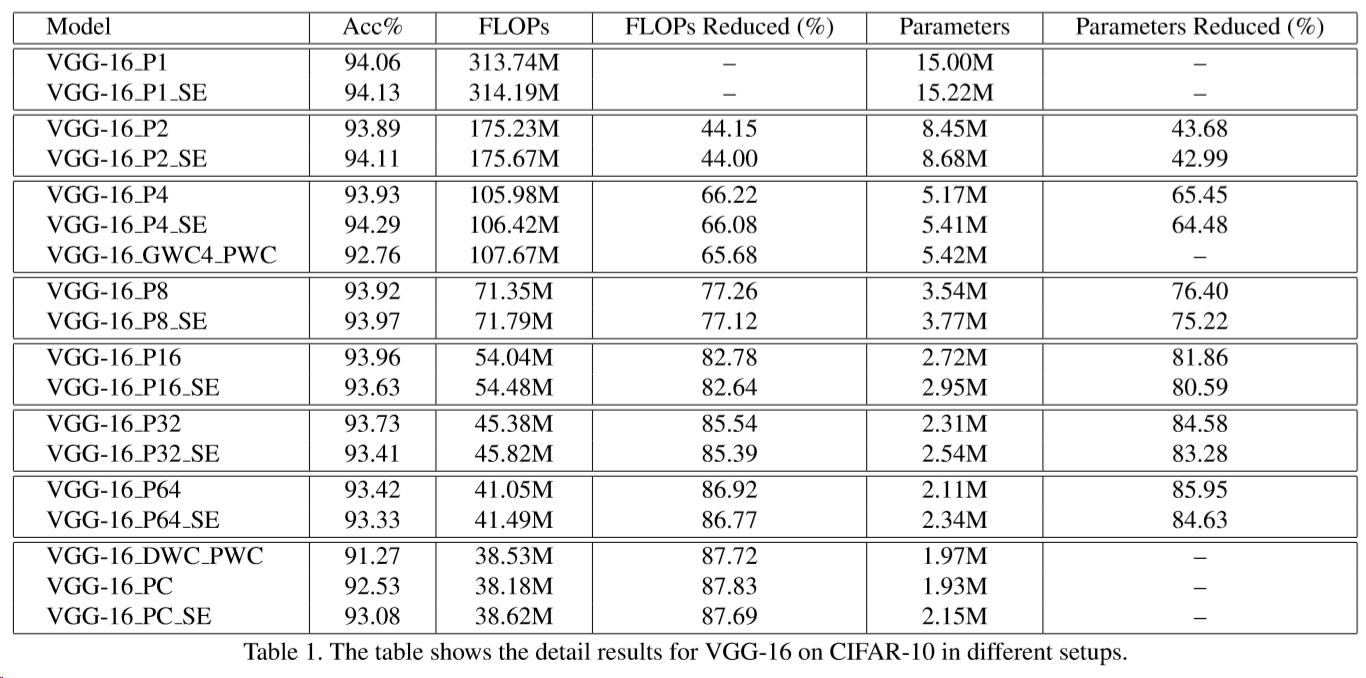
最基本的实验是基于 VGG16 和 cifar-10 的,结果如上表所示,实验思路就是将不同的加速卷积(HetConv、D+P、G+P)取代 VGG16 的原有卷积层,上表中的后缀表示网络层组成明细:
XXX Pα: XXX is the architecture, and part value is P = α;
XXX Pα SE: SE for Squeeze-and-Excitation with reduction-ratio = 8;
XXX GWCβ PWC: GWCβ PWC is the groupwise convolution with group size β followed by pointwise convolution;
XXX DWC PWC: DWC PWC is epthwise convolution followed by pointwise convolution;
XXX PC: PC is part value P = number of input channels (input depth).
SE 网络的论文我还没怎么看,就知道其原理大概是给每个特征加了个权重,所以暂时不了解 reduction-ratio 参数,不过这对本篇论文的理解影响不大。
第三行(P4 开头)展示了 HetConv 相对 Group 卷积的优势,最后一行展示了其相对深度可分离卷积的优势,而整个表格则反映了 P 值对网络的影响,综合来看,HetConv 确实是又好又快。
与其他压缩方法比较
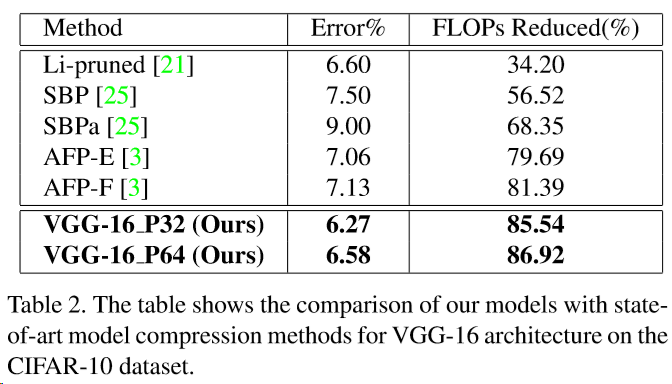
上图展示了模型压缩方法之间的比较,其他方法论文列表如下:
3:Auto-balanced filter pruning for efficient convolutional neural networks. AAAI, 2018.
21:Pruning filters for efficient convnets. ICLR, 2017.
25:Structured bayesian pruning via log-normal multiplicative noise. In NIPS, pages 6775–6784, 2017.
之后作者使用 ResNet、 MobileNet 并使用 ImageNet 数据集进行了实验,实验内容都和上面的相似,几点意外是加了 SE 的 ResNet 过拟合了(cifar-10)所以准确率低了一点,替换了 HetConv 的 MobileNet 效能更强劲,准确率反超了 使用 D+P 组合的基本模型,实验结果表格这里就不贴了,感兴趣的话查看原文即可。
『高性能模型』HetConv: HeterogeneousKernel-BasedConvolutionsforDeepCNNs的更多相关文章
- 『高性能模型』轻量级网络ShuffleNet_v1及v2
项目实现:GitHub 参考博客:CNN模型之ShuffleNet v1论文:ShuffleNet: An Extremely Efficient Convolutional Neural Netwo ...
- 『高性能模型』轻量级网络MobileNet_v2
论文地址:MobileNetV2: Inverted Residuals and Linear Bottlenecks 前文链接:『高性能模型』深度可分离卷积和MobileNet_v1 一.Mobil ...
- 『高性能模型』卷积复杂度以及Inception系列
转载自知乎:卷积神经网络的复杂度分析 之前的Inception学习博客: 『TensorFlow』读书笔记_Inception_V3_上 『TensorFlow』读书笔记_Inception_V3_下 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- 『高性能模型』深度可分离卷积和MobileNet_v1
论文原址:MobileNets v1 TensorFlow实现:mobilenet_v1.py TensorFlow预训练模型:mobilenet_v1.md 一.深度可分离卷积 标准的卷积过程可以看 ...
- 『TensorFlow Internals』笔记_源码结构
零.资料集合 知乎专栏:Bob学步 知乎提问:如何高效的学习 TensorFlow 代码?. 大佬刘光聪(Github,简书) 开源书:TensorFlow Internals,强烈推荐(本博客参考书 ...
- 2017-2018-2 1723 『Java程序设计』课程 结对编程练习-四则运算-准备阶段
2017-2018-2 1723 『Java程序设计』课程 结对编程练习-四则运算-准备阶段 在一个人孤身奋斗了将近半个学期以后,终于迎来的我们的第一次团队协作共同编码,也就是,我们的第一个结对编程练 ...
- 『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)
深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新 ...
- 似魔鬼的 『 document.write 』
在平时的工作中,楼主很少用 document.write 方法,一直觉得 document.write 是个危险的方法.楼主不用,并不代表别人不用,最近给维护的项目添了一点代码,更加深了我对 &quo ...
随机推荐
- 主线程 RunLoop 学习笔记
以下为主RunLoop 的输出,能够看到不同的source0,source1,observer ---------------------------------- CFRunLoop{wakeup ...
- Hashtable几种常用的遍历方法
Hashtable 在System.Collection是命名空间李Hashtable是程序员经常用到的类,它以快速检索著称,是研发人员开发当中不可缺少的利器. Hashtable表示键/值对的集合, ...
- 2017-2018-2 20155228 《网络对抗技术》 实验五:MSF基础应用
2017-2018-2 20155228 <网络对抗技术> 实验五:MSF基础应用 1. 实践内容 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.具体需 ...
- 打return
var zz=xx(); alert(zz); zz=yy(); alert(zz); function xx(){ var i=1,j=2; return i+j; } function yy(){ ...
- sys模块
#python run_case.py #在terminal中执行.py文件 在terminal中执行.py文件: 注: 无法使用terminal来打开那个文件 会显示如下:python: can't ...
- 叮咚,你的Lauce上线了!
哈,2014 - 2016 - 2018,虽然每隔两年才有那么一篇随笔,博客园,我还是爱你的~ 嗯,2018,马上又要失业了,我这是自带黑属性啊啊啊哈,工作了4年多的项目要被砍掉了, 倒不是说非要这个 ...
- Jquery小功能实例
下拉框内容选中左右移动 <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Sele ...
- java内存机制和GC垃圾回收机制
Java 内存区域和GC机制 转载来源于:https://www.cnblogs.com/zhguang/p/3257367.html 感谢 目录 Java垃圾回收概况 Java内存区域 Java对象 ...
- Java笔记 #06# 自定义简易参数校验框架——EasyValidator
索引 一.校验效果演示 二.校验器定义示例 定义一个最简单的校验器 正则校验器 三.EasyValidator的实现 四.更好的应用姿势——配合注解和面向切面 “参数校验”属于比较无聊但是又非常硬性的 ...
- 原创《分享(Angular 和 Vue)按需加载的项目实践优化方案》
针对前端优化的点有很多,例如:图片压缩,雪碧图,js/css/html 文件的压缩合并, cdn缓存, 减少重定向, 按需加载 等等 最近有心想针对 ionic项目 和 vue项目,做一个比较大的优 ...