MySQL索引管理
一.索引介绍
1.什么是索引
1.索引好比一本书的目录,它能让你更快的找到自己想要的内容.
2.让获取的数据更有目的性,从而提高数据库索引数据的性能.
2.索引类型介绍
1.BTREE:B+树索引
2.HASH:HASH索引
3.FULLTEXT:全文索引
4.RTREE:R树索引
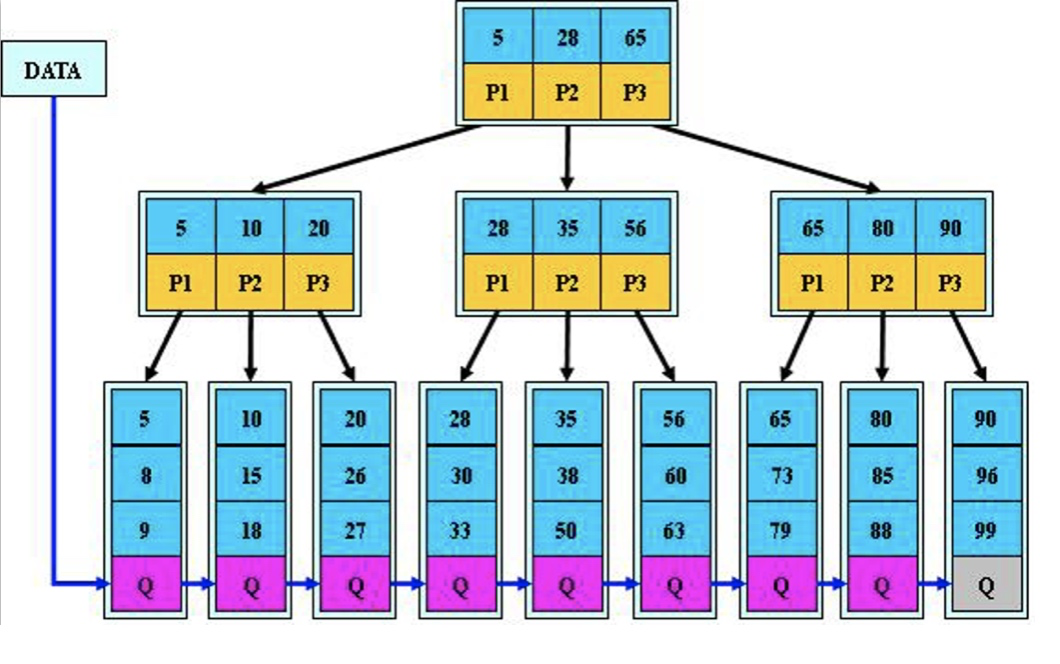
B+tree树索引
3.索引管理
索引建立在表的列上(字段)的。
在where后面的列建立索引才会加快查询速度。
pages<---索引(属性)<----查数据。
二.创建索引
1.索引分类
主键索引
普通索引*****
唯一索引
2.添加索引
#创建索引
alter table test add index index_name(name);
#创建索引
create index index_name on test(name);
#查看索引
desc table;
#查看索引
show index from table;
#删除索引
alter table test drop key index_name;
#添加主键索引(略)
#添加唯一性索引
alter table student add unique key uni_xxx(xxx);
#查看表中数据行数
select count(*) from city;
#查看去重数据行数
select count(distinct name) from city;
3. 前缀索引和联合索引
前缀索引
根据字符的前N个字符创建索引
alter table test add index idx_name(name(10));
避免对大列建索引
如果有,就使用前缀索引
联合索引
多个字段建立一个索引
例:
where a.女生 and b.身高 and c.体重 and d.身材好
index(a,b,c)
特点:前缀生效特性
a,ab,ac,abc,abcd 可以走索引或部分走索引
b bc bcd cd c d ba ... 不走索引
原则:把最常用来作为调节查询的列放在最前面
#创建people表
create table people (id int,name varchar(20),age tinyint,money int ,gender enum('m','f'));
#创建联合索引
alter table people add index idx_gam(gender,age,money);
三.explain详解
explain命令使用方法
mysql> explain select name,countrycode from city where id=1;
explain命令应用
查询数据的方式
1.全表扫描
1)在explain语句结果中type为ALL
2)什么时候出现全表扫描?
- 2.1 业务确实要获取所有数据
- 2.2 不走索引导致的全表扫描
- 2.2.1 没索引
- 2.2.2 索引创建有问题
- 2.2.3 语句有问题
生产中,mysql在使用全部扫描时的性能是极其差的,所以MySQL尽量避免出现全表扫描
2.索引扫描
2.1 常见的索引扫描类型:
1)index
2)range
3)ref
4)eq_ref
5)const
6)system
7)null
从上到下,性能从差到好,我们至少要达到range级别
index:Full Index Scan,index与ALL区别为index类型只遍历索引树。
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<,>查询
mysql> alter table city add index idx_city(population);
mysql> explain select * from city where population>30000000;
ref: 使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配摸个单独值得记录
mysql> alter table city drop key idx_code;
mysql> explain select * from city where countrycode='chn';
mysql> explain select * from city where countrycode in ('CHN','USA');
mysql> explain select * from city where countrycode='CHN' union all select * from city where countrycode='USA';
eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件A
join B
on A.sid=B.sid
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这类型访问.
如将主键置于where列表中,MySQL就能将该查询转换为一个常量
mysql> explain select * from city where id=1000;
NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
mysql> explain select * from city where id=1000000000000000000000000000;
Extra(拓展)
Using temporary
Using filesort 使用了默认的文件排序(如果使用了索引,会避免这类排序)
Using join buffer
如果出现Using filesort请检查order by ,group by ,distinct,join 条件列上没有索引
mysql> explain select * from city where countrycode='CHN' order by population;
当order by语句中出现Using filesort,那就尽量让排序值在where条件中出现
mysql> explain select * from city where population>30000000 order by population;
mysql> select * from city where population=2870300 order by population;
key_len:越小越好
前缀索引去控制
rows:越小越好
四.建立索引的原则(规范)
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。
那么索引设计原则又是怎样的?
1.选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如:
学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。
如果使用姓名的话,可能存在同名现象,从而降低查询速度。
主键索引和唯一键索引,在查询中使用是效率最高的。
select count(*) from world.city;
select count(distinct countrycode) from world.city;
select count(distinct countrycode,population ) from world.city;
注意:如果重复值较多,可以考录采用联合索引
2.为经常需要排序,分组和联合操作的字段建立索引
例如:
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。
如果为其建立索引,可以有效地避免排序操作
3.为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。
因此,为这样的字段建立索引,可以提高整个表的查询速度。
- 3.1 经常查询
- 3.2 列值的重复值少
注:如果经常作为条件的列,重复值特别多,可以建立联合索引
4.尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索
会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
5.限制索引的数目
索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
6.删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
重点关注:
1.没有查询条件,或者查询条件没有建立索引
#全表扫描
select * from table;
select * from tab where 1=1;
在业务数据库中,特别是数据量比较大的表,是没有全表扫描这种需求。
1)对用户查看是非常痛苦的。
2)对服务器来讲毁灭性的。
3)SQL改写成以下语句:
#情况1
#全表扫描
select * from table;
#需要在price列上建立索引
selec * from tab order by price limit 10;
#情况2
#name列没有索引
select * from table where name='zhangsan';
1、换成有索引的列作为查询条件
2、将name列建立索引
2.查询结果集是原表中的大部分数据,应该是25%以上
mysql> explain select * from city where population>3000 order by population;
1)如果业务允许,可以使用limit控制。
2)结合业务判断,有没有更好的方式。如果没有更好的改写方案就尽量不要在mysql存放这个数据了,放到redis里面。
3.索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。
重建索引就可以解决
4.查询条件使用函数在索引列上或者对索引列进行运算,运算包括(+,-,*等)
#例子
错误的例子:select * from test where id-1=9;
正确的例子:select * from test where id=10;
5.隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误
mysql> create table test (id int ,name varchar(20),telnum varchar(10));
mysql> insert into test values(1,'zs',''),(2,'l4',120),(3,'w5',119),(4,'z4',112);
mysql> explain select * from test where telnum=120;
mysql> alter table test add index idx_tel(telnum);
mysql> explain select * from test where telnum=120;
mysql> explain select * from test where telnum=120;
mysql> explain select * from test where telnum='';
6. <> ,not in 不走索引
mysql> select * from tab where telnum <> '';
mysql> explain select * from tab where telnum <> '';
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit
or或in尽量改成union
EXPLAIN SELECT * FROM teltab WHERE telnum IN ('','');
#改写成
EXPLAIN SELECT * FROM teltab WHERE telnum=''
UNION ALL
SELECT * FROM teltab WHERE telnum=''
7.like "%_" 百分号在最前面不走
#走range索引扫描
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%';
#不走索引
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110';
%linux%类的搜索需求,可以使用Elasticsearch -------> ELK
8.单独引用联合索引里非第一位置的索引列
CREATE TABLE t1 (id INT,NAME VARCHAR(20),age INT ,sex ENUM('m','f'),money INT);
ALTER TABLE t1 ADD INDEX t1_idx(money,age,sex);
DESC t1
SHOW INDEX FROM t1
#走索引的情况测试
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 AND sex='m';
#部分走索引
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30;
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND sex='m';
#不走索引
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=20
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=30 AND sex='m';
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE sex='m';
MySQL索引管理的更多相关文章
- MySQL 索引管理与执行计划
1.1 索引的介绍 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息.如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息. ...
- 二十三、mysql索引管理详解
一.索引分类 分为聚集索引和非聚集索引. 聚集索引 每个表有且一定会有一个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采用B+树结构保存在文件中,叶子节点存储主键的值以及对应记录的数据,非 ...
- 第六章· MySQL索引管理及执行计划
一.索引介绍 1.什么是索引 1)索引就好比一本书的目录,它能让你更快的找到自己想要的内容. 2)让获取的数据更有目的性,从而提高数据库检索数据的性能. 2.索引类型介绍 1)BTREE:B+树索引 ...
- MySQL索引管理及执行计划
一.索引介绍 二.explain详解 三.建立索引的原则(规范)
- 知识点:Mysql 索引原理完全手册(1)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) Mysql-索引原理完全手 ...
- MySQL索引原理以及查询优化
转载自:https://www.cnblogs.com/bypp/p/7755307.html MySQL索引原理以及查询优化 一.介绍 1.什么是索引? 一般的应用系统,读写比例在10:1左右,而且 ...
- day 7-19 Mysql索引原理与查询优化
一,介绍 1.什么是索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语 ...
- 【mysql】索引原理-MySQL索引原理以及查询优化
转载:https://www.cnblogs.com/bypp/p/7755307.html 一.介绍 1.什么是索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性 ...
- mysql 索引原理及查询优化 -转载
转载自 mysql 索引原理及查询优化 https://www.cnblogs.com/panfb/p/8043681.html 潘红伟 mysql 索引原理及查询优化 一 介绍 为何要有索引? ...
随机推荐
- Sql server 2014 数据库还原奇异现象
用A库来还原B库 对正在使用的B库执行还原,还原时修改数据库名称,还原出错,提示数据库正在使用.删除B库,仍然提示正在使用,感觉像僵尸 重启SQL SERVER,因B库已删除,在A库上点击 ...
- Numpy数组数据文件的读写
一.引言 读写数据文件的重要性就不必多说了. 二.读取列表形式数据的文件 1.我们写几行CSV格式(列表形式,两值之间逗号隔开)的数据. id,height,age 1,175,20 2,168,18 ...
- Salesforce 小知识:大量“子记录”的处理方法
大量"子记录"的存放 例子:系统中导入了很多"联系人"(Contact)记录,它们没有具体所属的"客户"(Account)记录.那么我们就要 ...
- python 生成图形验证码
文章链接:https://mp.weixin.qq.com/s/LYUBRNallHcjnhJb1R3ZBg 日常在网站使用过程中经常遇到图形验证,今天准备自己做个图形验证码,这算是个简单的功能,也适 ...
- 原生Js交互之DSBridge
文章链接:https://mp.weixin.qq.com/s/Iqd0dKM-ZW4UwkIgSTnvYg 在上一篇文章「android 记一次富文本加载之路」中 介绍了关于android加载富文本 ...
- SpringMVC从认识到细化了解
目录 SpringMVC的介绍 介绍: 执行流程 与strut2的对比 基本运行环境搭建 基础示例 控制器的编写 控制器创建方式: 请求映射问题: 获取请求提交的参数 通过域对象(request,re ...
- win8.1 AMD 屏幕亮度无法调整
lenovo z465 AMD处理器. win8.1 pro系统 屏幕亮度无法调整解决办法: 1:当然是先去本地服务里禁用"Sensor Monitoring Service&qu ...
- Go语言学习笔记-流程控制(二)
Go语言流程控制 字典类型Map 1.上节遗留:map字典类型 变量声明:var myMap map[string] PersonInfo 其中,myMap是变量名,string是键的类型,Perso ...
- Checkpoint 和Breakpoint
参考:http://www.cnblogs.com/qiangshu/p/5241699.htmlhttp://www.cnblogs.com/biwork/p/3366724.html 1. Che ...
- 树莓派3b+ Ubuntu 16.04 MATA系统 ssh远程登陆后修改主机名、用户密码和用户名
写在前面: 刚刚开始写博客,记录下自己的学习过程,备忘. 最近在使用树莓派做智能小车的开发,使用的是树莓派3b+,安装的是Ubuntu 16.04 MATA 系统,安装系统后需要修改主机名,登陆密码以 ...