Dynamic attention in tensorflow
新代码在contrib\seq2seq\python\ops\attention_decoder_fn.py
和之前代码相比 不再采用conv的方式来计算乘,直接使用乘法和linear
给出了两种attention的实现 传统的"bahdanau": additive (Bahdanau et al., ICLR'2015) Neural Machine Translation by Jointly Learning to Align and Translate
以及"luong": multiplicative (Luong et al., EMNLP'2015) Effective Approaches to Attention-based Neural Machine Translation
这里以 bahdanau为例
还是按照 Grammar as a Foreign Language的公式
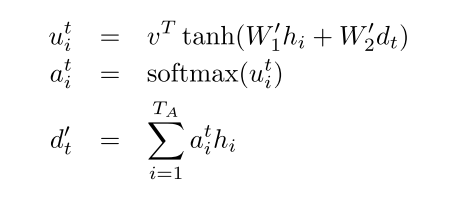
对应代码里面
将input encoder outputs 也就是输入的attention states作为 attention values
也就是在prepare_attention中
attention_values = attention_states
那么attention keys 对应 W_1h_i的部分,采用linear来实现
attention_keys = layers.linear(
attention_states, num_units, biases_initializer=None, scope=scope)
在创建score function的
_create_attention_score_fn 中完整定义了计算过程
这里去掉luong的实现部分 仅仅看bahdanau部分
with variable_scope.variable_scope(name, reuse=reuse):
if attention_option == "bahdanau":
#这里对应第一个公式最右面 query_w对应W_2, query是对应d_t
query_w = variable_scope.get_variable(
"attnW", [num_units, num_units], dtype=dtype)
#对应第一个公式最左侧的v
score_v = variable_scope.get_variable("attnV", [num_units], dtype=dtype)
def attention_score_fn(query, keys, values):
"""Put attention masks on attention_values using attention_keys and query.
Args:
query: A Tensor of shape [batch_size, num_units].
keys: A Tensor of shape [batch_size, attention_length, num_units].
values: A Tensor of shape [batch_size, attention_length, num_units].
Returns:
context_vector: A Tensor of shape [batch_size, num_units].
Raises:
ValueError: if attention_option is neither "luong" or "bahdanau".
"""
if attention_option == "bahdanau":
# transform query W_2*d_t
query = math_ops.matmul(query, query_w)
# reshape query: [batch_size, 1, num_units]
query = array_ops.reshape(query, [-1, 1, num_units])
# attn_fun 对应第一个公式的最左侧结果(=左侧) math_ops.reduce_sum(v * math_ops.tanh(keys + query), [2]) * + reduce_sum操作即是dot操作
scores = _attn_add_fun(score_v, keys, query)
# Compute alignment weights
# scores: [batch_size, length]
# alignments: [batch_size, length]
# TODO(thangluong): not normalize over padding positions.
#对应第二个公式计算softmax结果
alignments = nn_ops.softmax(scores)
# Now calculate the attention-weighted vector.
alignments = array_ops.expand_dims(alignments, 2)
#利用softmax得到的权重 计算attention向量的加权加和
context_vector = math_ops.reduce_sum(alignments * values, [1])
context_vector.set_shape([None, num_units])
#context_vector即对应 第三个公式 =的左侧
return context_vector
再看下计算出contenxt_vector之后的使用,这个方法正如论文中所说也和之前旧代码基本一致
也就是说将context和query进行concat之后通过linear映射依然得到num_units的长度 作为attention
def _create_attention_construct_fn(name, num_units, attention_score_fn, reuse):
"""Function to compute attention vectors.
Args:
name: to label variables.
num_units: hidden state dimension.
attention_score_fn: to compute similarity between key and target states.
reuse: whether to reuse variable scope.
Returns:
attention_construct_fn: to build attention states.
"""
with variable_scope.variable_scope(name, reuse=reuse) as scope:
def construct_fn(attention_query, attention_keys, attention_values):
context = attention_score_fn(attention_query, attention_keys,
attention_values)
concat_input = array_ops.concat([attention_query, context], 1)
attention = layers.linear(
concat_input, num_units, biases_initializer=None, scope=scope)
return attention
return construct_fn
最终的使用,cell_output就是attention,而next_input是cell_input和attention的concat
# construct attention
attention = attention_construct_fn(cell_output, attention_keys,
attention_values)
cell_output = attention
# argmax decoder
cell_output = output_fn(cell_output) # logits
next_input_id = math_ops.cast(
math_ops.argmax(cell_output, 1), dtype=dtype)
done = math_ops.equal(next_input_id, end_of_sequence_id)
cell_input = array_ops.gather(embeddings, next_input_id)
# combine cell_input and attention
next_input = array_ops.concat([cell_input, attention], 1)
Dynamic attention in tensorflow的更多相关文章
- 论文翻译:2020_A Recursive Network with Dynamic Attention for Monaural Speech Enhancement
论文地址:基于动态注意的递归网络单耳语音增强 论文代码:https://github.com/Andong-Li-speech/DARCN 引用格式:Li, A., Zheng, C., Fan, C ...
- Dynamic seq2seq in tensorflow
v1.0中 tensorflow渐渐废弃了老的非dynamic的seq2seq接口,已经放到 tf.contrib.legacy_seq2seq目录下面. tf.contrib.seq2seq下面的实 ...
- 可视化展示attention(seq2seq with attention in tensorflow)
目前实现了基于tensorflow的支持的带attention的seq2seq.基于tf 1.0官网contrib路径下seq2seq 由于后续版本不再支持attention,迁移到melt并做了进一 ...
- Effective Tensorflow[转]
Effective TensorFlow Table of Contents TensorFlow Basics Understanding static and dynamic shapes Sco ...
- seq2seq attention
1.seq2seq:分为encoder和decoder a.在decoder中,第一时刻输入的是上encoder最后一时刻的状态,如果用了双向的rnn,那么一般使用逆序的最后一个时刻的输出(网上说实验 ...
- attention
attention: 时序的刻画 attention 在recommendation 中的应用: 年龄的增长, 对于商品的喜好 Dynamic attention deeo model:
- tensorflow 控制流操作,条件判断和循环操作
Control flow operations: conditionals and loops When building complex models such as recurrent neura ...
- 论文解读(GATv2)《How Attentive are Graph Attention Networks?》
论文信息 论文标题:How Attentive are Graph Attention Networks?论文作者:Shaked Brody, Uri Alon, Eran Yahav论文来源:202 ...
- [论文阅读] RNN 在阿里DIEN中的应用
[论文阅读] RNN 在阿里DIEN中的应用 0x00 摘要 本文基于阿里推荐DIEN代码,梳理了下RNN一些概念,以及TensorFlow中的部分源码.本博客旨在帮助小伙伴们详细了解每一步骤以及为什 ...
随机推荐
- SuperWebSocket与Cocos2dx通信时执行不了命令的问题
要修改WebSocketSession.cs 中的方法 string IWebSocketSession.GetAvailableSubProtocol(string protocol) { if ( ...
- Intellij IDEA使用Docker插件部署应用
1.安装Docker插件 配置Docker Api,在API URL中填入api的地址,记得Docker后台程序启动是要配置 -H tcp://0.0.0.0:2375 开放远程地址端口,注意这里的i ...
- 安装 VS2017 的正确姿势
自从装了长城带宽,我的肠子就变成青色的了. 国内的网络环境,真的是有很大的不同,有的人装 VS 的时候,号称满速,有的人(其实就是我)要等它下载很久,还告诉我有个组件没有安装成功.很久很久以前,VS ...
- Servlet(7)—ServletConfig接口和SevletContext接口
ServletConfig接口 1. 可以获取当前Servlet在web.xml中的配置信息(用的不多) 2. 在不使用"硬编码"的情况下,将部署状态信息传递给Servlet.这个 ...
- 轻量级的Web框架——Nancy
最近想找一个简单的.Net下的轻量级Web框架,作为用户的本地的一个WebServer,实现同浏览器程序的一些简单交互,并调用本地服务,实现类似浏览器插件的功能.它有如下几点要求: 简单,能快速账务, ...
- CSS魔法堂:改变单选框颜色就这么吹毛求疵!
前言 是否曾经被业务提出"能改改这个单选框的颜色吧!让它和主题颜色搭配一下吧!",然后苦于原生不支持换颜色,最后被迫自己手撸一个凑合使用.若抛开input[type=radio] ...
- [web 前端] css3 transform方法常用属性
cp from : https://www.cnblogs.com/chrxc/p/5126569.html css3中transform方法是一个功能强大的属性,可以对元素进行移动.缩放.转动.拉长 ...
- 在Mac平台上安装配置ELK时的一些总结
一.前言 大数据处理是流行的一些表现,在不断壮大的数据处理中,怎么样处理数据才是我们继续做好开发的正道.本文章来自网络,不敢原创,但是也有很大借鉴. 二.MAC安装ELK 首先是安装elast ...
- 【SQL 代码】SQL 语句记录(不定时更新)
1.数值四舍五入,小数点后保留2位 round() 函数是四舍五入用,第一个参数是我们要被操作的数据,第二个参数是设置我们四舍五入之后小数点后显示几位. numeric 函数的2个参数,第一个表示数据 ...
- Docker 集群Swarm创建和Swarm Web管理
关于Docker Swarm更多的介绍请查看<Docker管理工具-Swarm部署记录> 一.环境配置 1.安装环境 # cat /etc/redhat-release CentOS Li ...