JVM、Gc工作机制详解
JVM主要包括四个部分:
- 类加载器(ClassLoad)
- 执行引擎
- 内存区:
- 本地方法接口:类似于jni调本地native方法
内存区包括四个部分:
1.方法区:包含了静态变量、常量池、构造函数等
2.Java堆:java实例或者是对象
3.Java栈:java栈总是和线程关联在一起,每当创建一个线程时,JVM就会为这个线程创建一个对应的java栈。在这个java栈中又会包含多个栈帧,每运行一个方法就创建一个栈帧,用于存储局部变量表、操作栈、方法返回值等。每 一个方法从调用直至执行完成的过程,就对应一个栈帧在java栈中入栈到出栈的过程。所以java栈是现成私有的。
4.程序计数器:保存线程执行的内存地址
5.本地方法栈(Native Method Stack):和java栈的作用差不多,只不过是为JVM使用到的native方法服务的。
内存分配
内存分配主要有3种方法:静态分配、栈式分配、堆式分配
静态分配:主要是静态存储区,存放静态变量、全局static数据和常量,在程序编译的时候就被分配,在整个程序运行的过程中都存在。
栈式分配:一般存放方法中的局部变量(基础数据类型和局部对象),方法执行结束后变量所持有的内存都会被释放,栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
堆式分配:又称动态分配,一般是new出来的对象,会被gc回收。
垃圾检测、回收算法
垃圾检测的方法:
1.引用计数法:给一个对象添加引用计数器,每当有个地方引用它,计数器就加1;引用失效就减1,当计数器为0的时候就会被回收,但是这个方法有一个缺陷是如果两个对象互相引用,但是没有被其他的对象引用,那这两个对象肯定是垃圾对象,但是此刻的计数器不会为0,不会被回收。
2.可达性分析法:

这个算法的基本思路就是通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论的话来说,就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。如图3-1所示,对象object 5、object 6、object 7虽然互相有关联,但是它们到GC Roots是不可达的,所以它们将会被判定为是可回收的对象。
在Java语言中,可作为GC Roots的对象包括下面几种:
1.虚拟机栈(栈帧中的本地变量表)中引用的对象。
2.方法区中类静态属性引用的对象。
3.方法区中常量引用的对象。
4.本地方法栈中JNI(即一般说的Native方法)引用的对象。
垃圾回收的算法:
1.标记清除:这种算法分为两个阶段,第一步是从根节点标记所有被引用的对象,第二步是从这个堆中清除其他未被引用的对象,这种算法有一个弊端是清除后的内存是不连续的,产生了很多的碎片。

2.复制:将内存划分为两个相等大小的区域,每次只使用其中的一个区域,将正在使用的对象复制到另外一片内存中,还可以进行相应的整理,这种算法的缺点是需要两倍的内存。
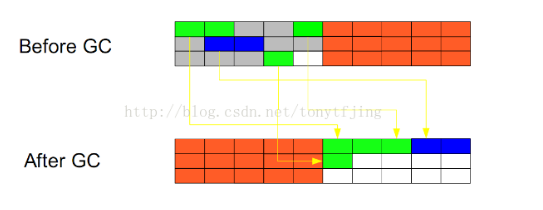
3.标记-整理:复制算法的高效性是建立在存活对象少、垃圾对象多的前提下的。这种情况在新生代经常发生,但是在老年代更常见的情况是大部分对象都是存活对象。如果依然使用复制算法,由于存活的对象较多,复制的成本也将很高。
标记-压缩算法是一种老年代的回收算法,它在标记-清除算法的基础上做了一些优化。首先也需要从根节点开始对所有可达对象做一次标记,但之后,它并不简单地清理未标记的对象,而是将所有的存活对象压缩到内存的一端。之后,清理边界外所有的空间。这种方法既避免了碎片的产生,又不需要两块相同的内存空间,因此,其性价比比较高。

4.分代收集算法:将对象按其生命周期的不同划分成:年轻代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation)。其中持久代主要存放的是类信息,所以与java对象的回收关系不大,与回收息息相关的是年轻代和年老代。
JVM、Gc工作机制详解的更多相关文章
- JVM结构、GC工作机制详解
JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知,JVM主要包括四个部分 ...
- JVM结构、GC工作机制详解(转)
原文地址:http://blog.csdn.NET/tonytfjing/article/details/44278233 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JV ...
- 【转载】JVM结构、GC工作机制详解
文章主要分为以下四个部分 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知, ...
- 转 Java虚拟机5:Java垃圾回收(GC)机制详解
转 Java虚拟机5:Java垃圾回收(GC)机制详解 Java虚拟机5:Java垃圾回收(GC)机制详解 哪些内存需要回收? 哪些内存需要回收是垃圾回收机制第一个要考虑的问题,所谓“要回收的垃圾”无 ...
- Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.存储机制 1.基础描述 NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据 ...
- Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.工作机制 1.基础描述 DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度.校验.时 ...
- Session的工作机制详解和安全性问题(PHP实例讲解)
我们先简单的了解一些http的知识,从而理解该协议的无状态特性.然后,学习一些关于cookie的基本操作.最后,我会一步步阐述如何使用一些简单,高效的方法来提高你的php应用程序的安全性以及稳定行. ...
- 【系统之音】WindowManager工作机制详解
前言 目光所及,皆有Window!Window,顾名思义,窗口,它是应用与用户交互的一个窗口,我们所见到视图,都对应着一个Window.比如屏幕上方的状态栏.下方的导航栏.按音量键调出来音量控制栏.充 ...
- Java虚拟机5:Java垃圾回收(GC)机制详解
哪些内存需要回收? 哪些内存需要回收是垃圾回收机制第一个要考虑的问题,所谓“要回收的垃圾”无非就是那些不可能再被任何途径使用的对象.那么如何找到这些对象? 1.引用计数法 这个算法的实现是,给对象中添 ...
随机推荐
- iOS-微信支付商户支付下单id非法
最近在APP中WKWebView中调用微信支付的时候,一直报商户支付下单id非法.看了n边微信文档,度娘了n次-----仍未解决.因为安卓的支付是没有问题的所以就跟安卓兄弟要了最终调用微信的字符串: ...
- Angular使用总结 --- 如何正确的操作DOM
无奈接手了一个旧项目,上一个老哥在Angular项目中大量使用了JQuery来操作DOM,真的是太不讲究了.那么如何优雅的使用Angular的方式来操作DOM呢? 获取元素 1.ElementRef ...
- HoloLens开发手记 - 使用Windows设备控制台 Using Windows Device Portal
Windows设备控制台允许你通过Wi-Fi或USB来远程控制你的HoloLens设备.设备控制台是HoloLens上的一个Web Server,你可以通过PC的浏览器来连接到它.设备控制台包含了很多 ...
- @pathvariable和@RequestParam的区别
@PathVariable 获取的是请求路径url中的值: (http://xxx.xxx.com/get_10.html,侧重于请求的URL路径里面的{xx}变量 ) //获取url中某部分的值 @ ...
- Docker hv-sock proxy (vsudd) is not reachable
Docker hv-sock proxy (vsudd) is not reachable Docker hv-sock proxy (vsudd) is not reachable at Docke ...
- maven-assembly-plugin的使用
maven-assembly-plugin使用描述(拷自 maven-assembly-plugin 主页) The Assembly Plugin for Maven is primarily in ...
- Filebeat的Registry文件解读
你可能没有注意但很重要的filebeat小知识 Registry文件 Filebeat会将自己处理日志文件的进度信息写入到registry文件中,以保证filebeat在重启之后能够接着处理未处理过的 ...
- maven -maven.test.skip skipTests
-DskipTests,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下. -Dmaven.test.skip=true,不执行测试用例,也不编译测试 ...
- 源码编译安装MySQL8.0
源码编译安装MySQL8.0 0.前期准备条件 查看linux的版本 [root@mysql etc]# cat /etc/redhat-release CentOS Linux release 7. ...
- 解决SQL Server 2008安装时提示:重新启动计算机 失败
a.重启机器,再进行安装,如果发现还有该错误,请按下面步骤: b.在开始->运行中输入regedit c.到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet ...