Python入门 来点栗子
查天气(1)
http://wthrcdn.etouch.cn/weather_mini?citykey=101280804
http://wthrcdn.etouch.cn/WeatherApi?citykey=101280804
http://bbs.crossincode.com/forum.php?mod=viewthread&tid=8&extra=page%3D4
http://bbs.crossincode.com/forum.php?mod=viewthread&tid=9&extra=page%3D4
查天气(2)
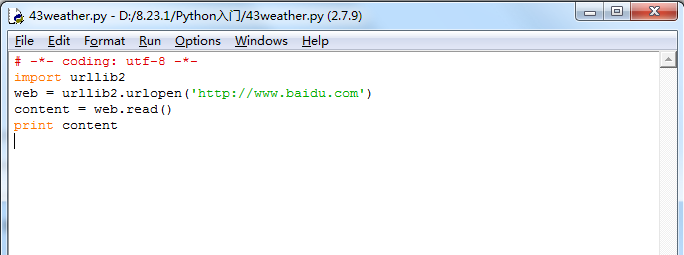
# -*- coding: utf-8 -*-
import urllib2
web = urllib2.urlopen('http://www.baidu.com')
content = web.read()
print content
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city
cityname = raw_input('你想查哪个城市的天气?\n')
citycode = city.get(cityname)
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html' % citycode)
content = urllib2.urlopen(url).read()
print content
http://www.weather.com.cn/data/cityinfo/101280800.html

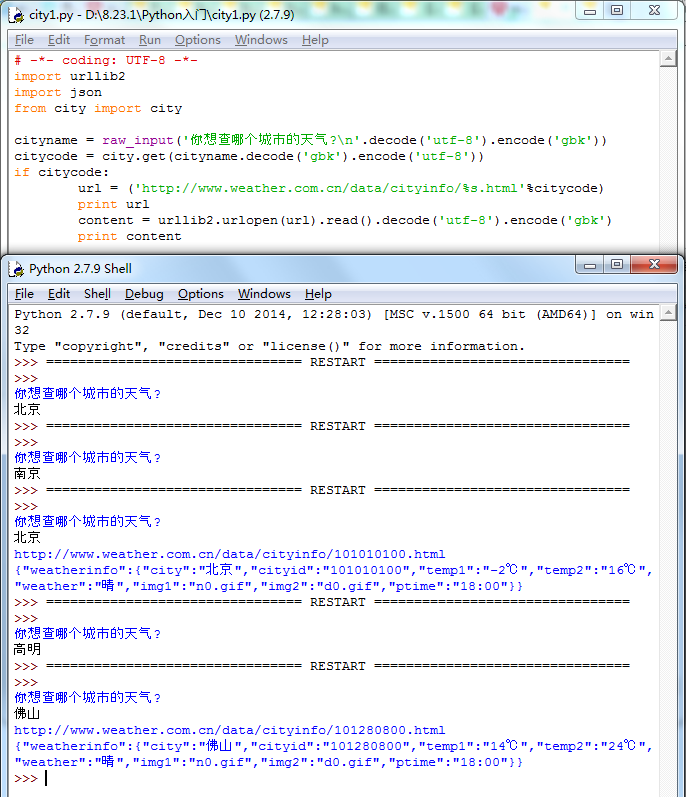
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
print content
查天气(3)
看一下我们已经拿到的json格式的天气数据:
{"weatherinfo":{"city":"佛山","cityid":"101280800","temp1":"14℃","temp2":"24℃","weather":"晴","img1":"n0.gif","img2":"d0.gif","ptime":"18:00"}}
{
"weatherinfo":{
"city":"佛山",
"cityid":"101280800",
"temp1":"14℃",
"temp2":"24℃",
"weather":"晴",
"img1":"n0.gif",
"img2":"d0.gif",
"ptime":"18:00"}
}
直接在命令行中看到的应该是没有换行和空格的一长串字符,这里我把格式整理了一下。可以看出,它像是一个字典的结构,但是有两层。最外层只有一个key--“weatherinfo”,它的value是另一个字典,里面包含了好几项天气信息,现在我们最关心的就是其中的temp1,temp2和weather。
虽然看上去像字典,但它对于程序来说,仍然是一个字符串,只不过是一个满足json格式的字符串。我们用python中提供的另一个模块json提供的loads方法,把它转成一个真正的字典。
import json
data = json.loads(content)
这时候的data已经是一个字典,尽管在控制台中输出它,看上去和content没什么区别,只是编码上有些不同:
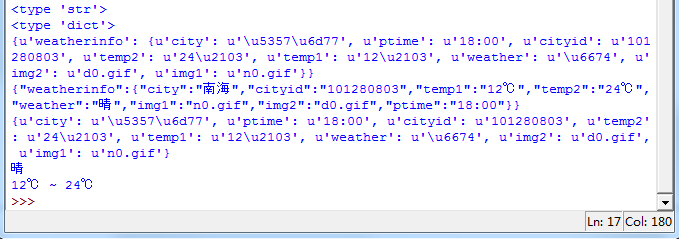
{u'weatherinfo': {u'city': u'\u4f5b\u5c71', u'ptime': u'18:00', u'cityid': u'101280800', u'temp2': u'24\u2103', u'temp1': u'14\u2103', u'weather': u'\u6674', u'img2': u'd0.gif', u'img1': u'n0.gif'}}
但如果你用type方法看一下它们的类型:
print type(content)
print type(data)
就知道区别在哪里了。
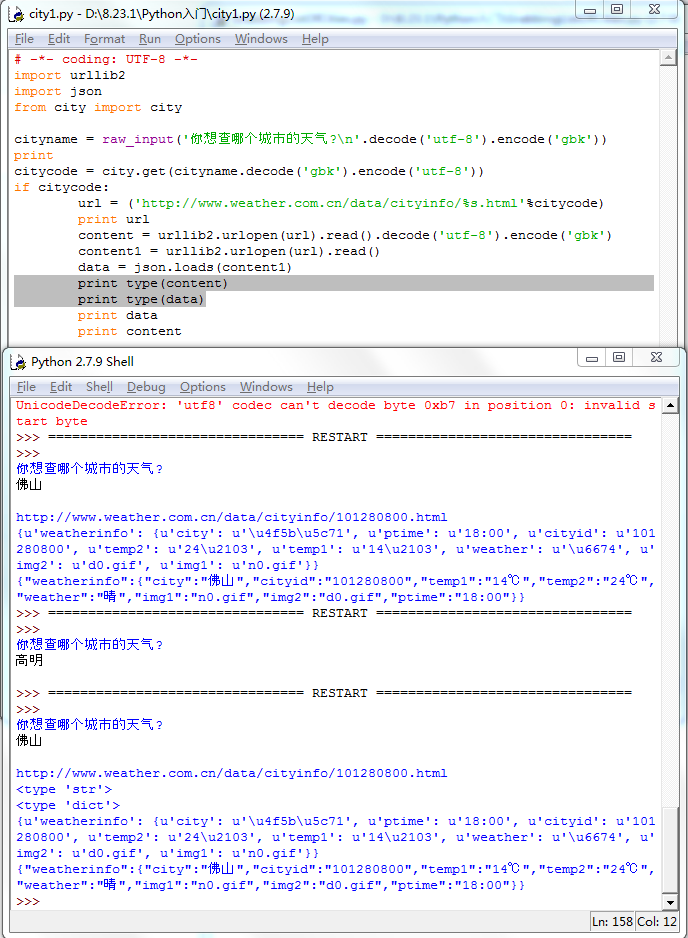
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
content1 = urllib2.urlopen(url).read()
data = json.loads(content1)
print type(content)
print type(data)
print data
print content
之后的事情就比较容易了。
result = data['weatherinfo']
str_temp = ('%s\n%s ~ %s') % (
result['weather'],
result['temp1'],
result['temp2'] )
print str_temp
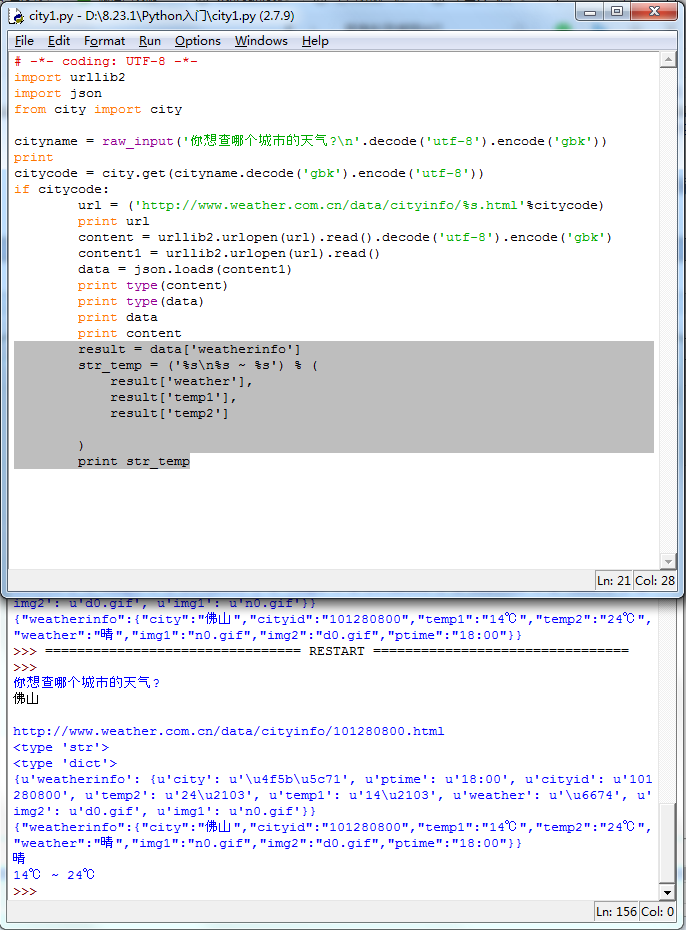
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
content1 = urllib2.urlopen(url).read()
data = json.loads(content1)
print type(content)
print type(data)
print data
print content
result = data['weatherinfo']
str_temp = ('%s\n%s ~ %s') % (
result['weather'],
result['temp1'],
result['temp2'] )
print str_temp
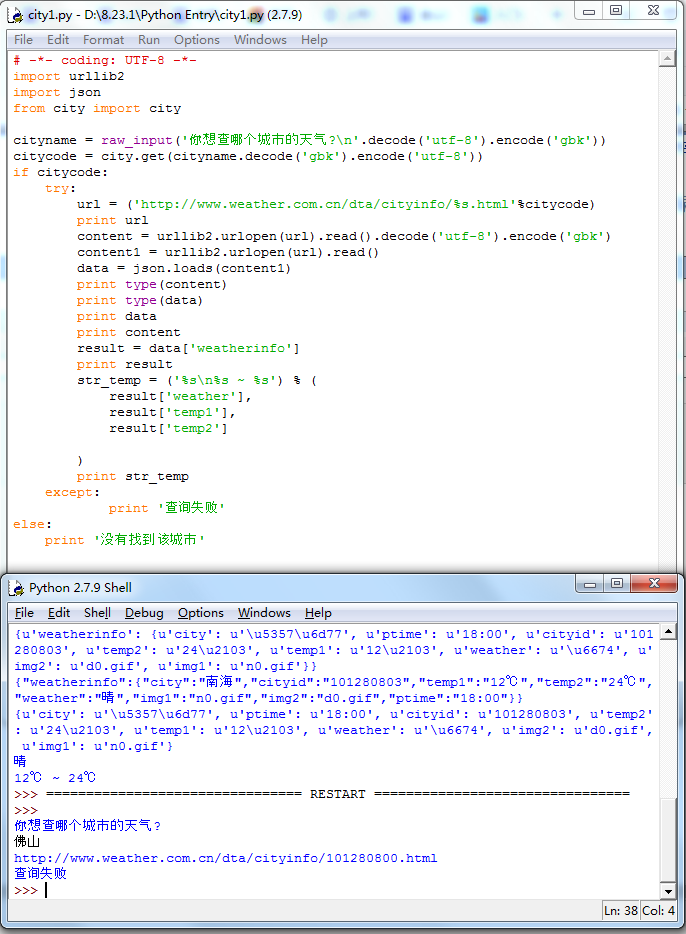
为了防止在请求过程中出错,我加上了一个异常处理。
try:
###
###
except:
print '查询失败'
以及没有找到城市时的处理:
if citycode:
###
###
else:
print '没有找到该城市'
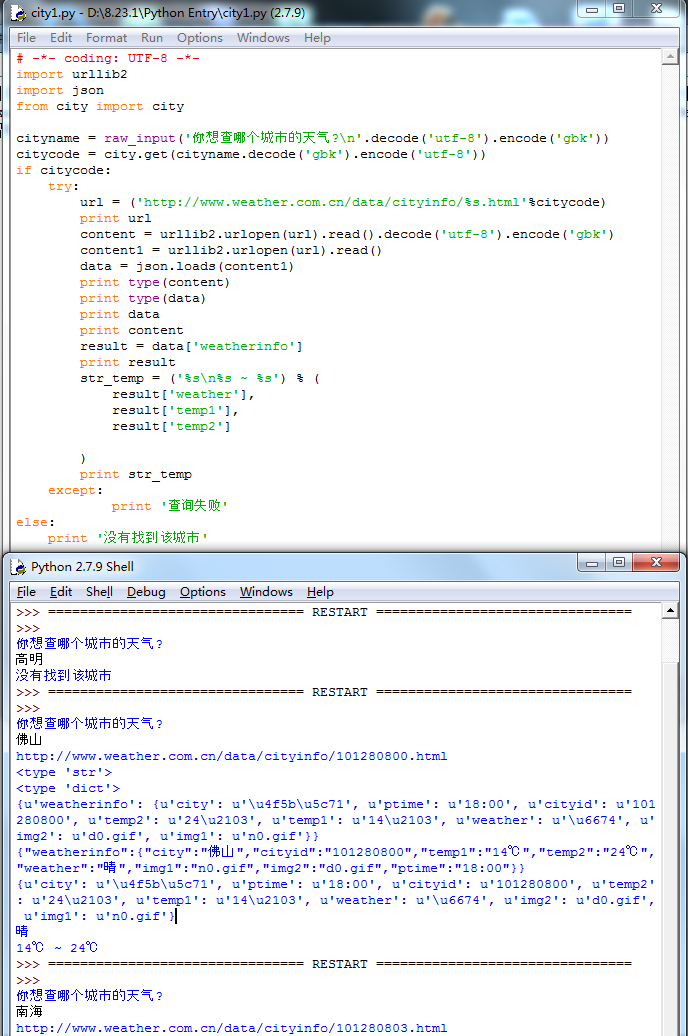
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
try:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
content1 = urllib2.urlopen(url).read()
data = json.loads(content1)
print type(content)
print type(data)
print data
print content
result = data['weatherinfo']
print result
str_temp = ('%s\n%s ~ %s') % (
result['weather'],
result['temp1'],
result['temp2'] )
print str_temp
except:
print '查询失败'
else:
print '没有找到该城市'
查天气(4)
这一课算是“查天气”程序的附加内容。没有这一课,你也查到天气了。但了解一下城市代码的抓取过程,会对网页抓取有更深的理解。
天气网的城市代码信息结构比较复杂,所有代码按层级放在了很多xml为后缀的文件中。而这些所谓的“xml”文件又不符合xml的格式规范,导致在浏览器中无法显示,给我们的抓取又多加了一点难度。
首先,抓取省份的列表:
# -*- coding: UTF-8 -*-
import urllib2 url1 = 'http://m.weather.com.cn/data3/city.xml' content1 = urllib2.urlopen(url1).read() provinces = content1.split(',') print content1
输出content1可以查看全部省份代码:
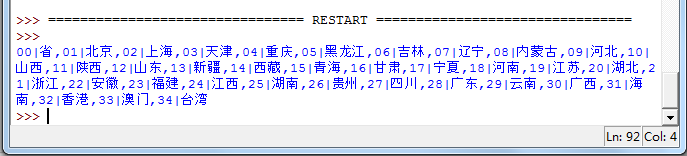
对于每个省,抓取城市列表:
url = 'http://m.weather.com.cn/data3/city%s.xml'
for p in provinces:
p_code = p.split('|')[0]
url2 = url % p_code
content2 = urllib2.urlopen(url2).read()
cities = content2.split(',')
print content2.decode('utf-8')
输出content2可以查看此省份下所有城市代码:
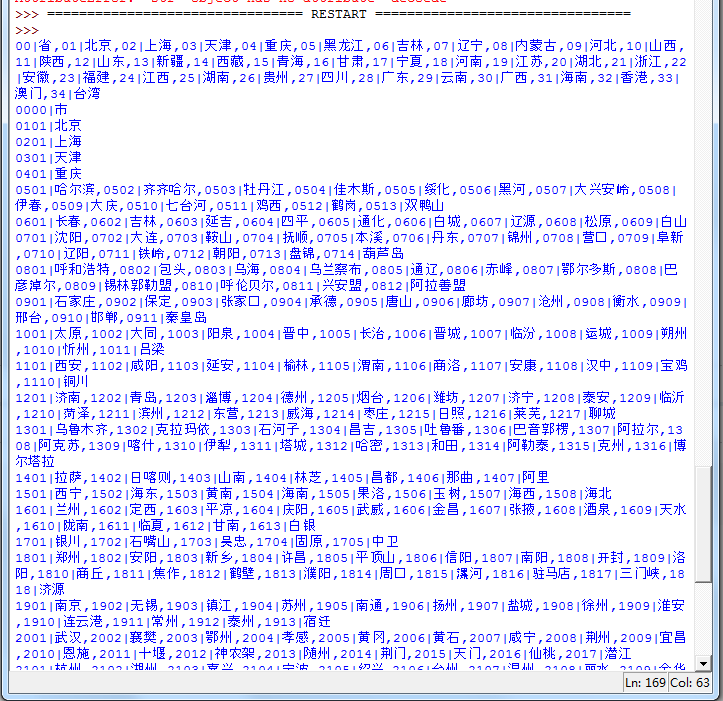
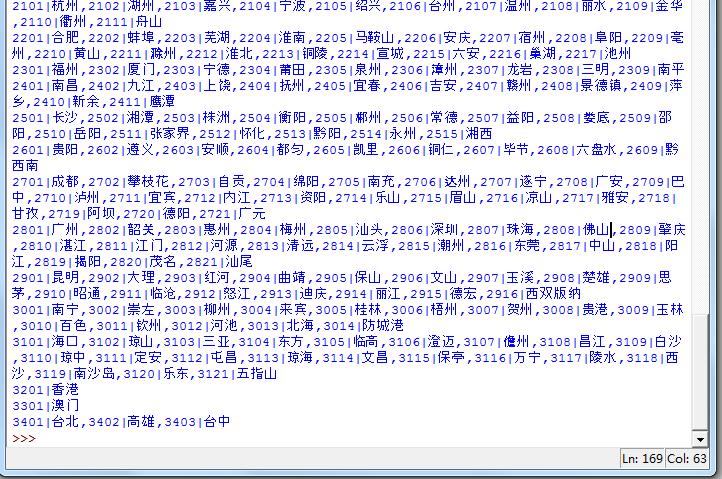
再对于每个城市,抓取地区列表:
for c in cities[:3]:
c_code = c.split('|')[0]
url3 = url % c_code
content3 = urllib2.urlopen(url3).read()
districts = content3.split(',')
print content3.decode('utf-8')
content3是此城市下所有地区代码:
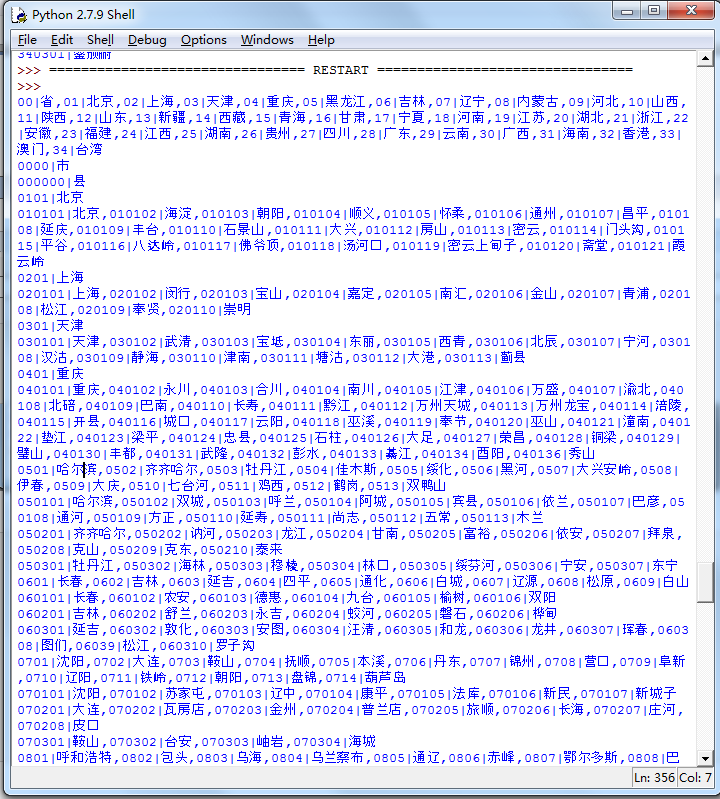
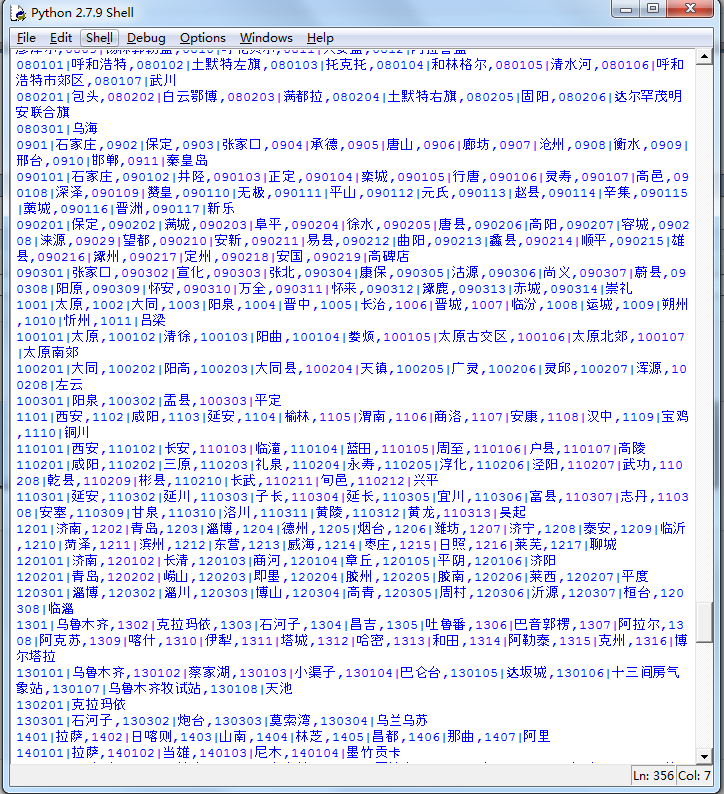
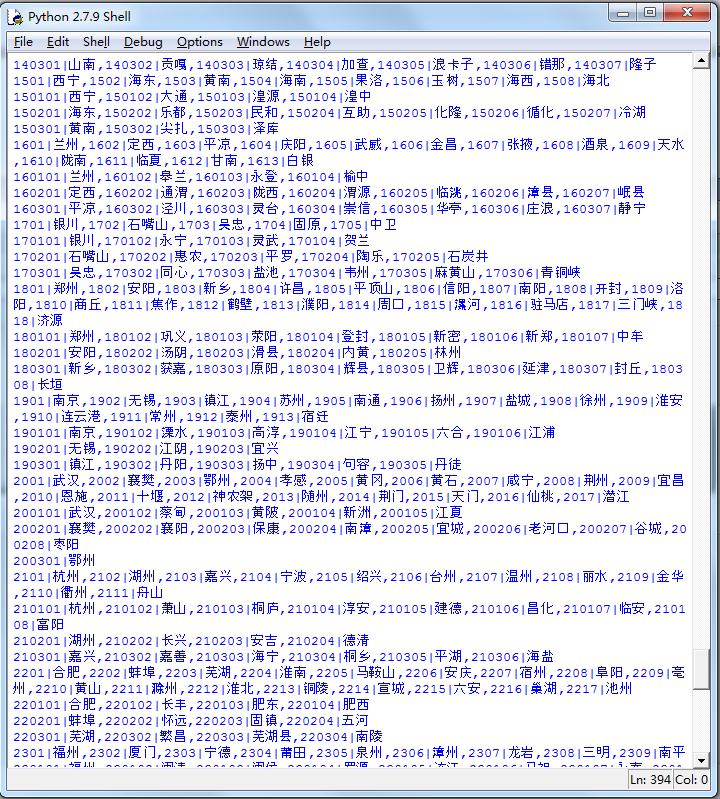

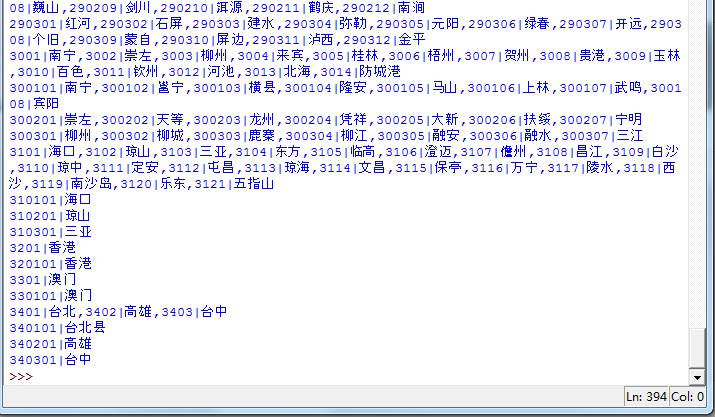
最后,对于每个地区,我们把它的名字记录下来,然后再发送一次请求,得到它的最终代码:
Python入门 来点栗子的更多相关文章
- python入门之小栗子
1 点球小游戏: from random import choice score=[0,0]direction=['left','center','right'] def kick(): print ...
- PYTHON 学习笔记1 PYTHON 入门 搭建环境与基本类型
简介 Python,当然大家听到这个名词不再是有关于像JAVA 一样的关于后台,我们学习Python 的目的在于对于以后数据分析和机器学习AI 奠定基础,Python 在数据分析这一块,可谓是有较好的 ...
- python入门简介
Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC ...
- python入门学习课程推荐
最近在学习自动化,学习过程中,越来越发现coding能力的重要性,不会coding,基本不能开展自动化测试(自动化工具只是辅助). 故:痛定思痛,先花2个星期将python基础知识学习后,再进入自动化 ...
- Python运算符,python入门到精通[五]
运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算.例如:2+3,其操作数是2和3,而运算符则是“+”.在计算器语言中运算符大致可以分为5种类型:算术运算符.连接运算符.关系运算符.赋值运 ...
- Python基本语法[二],python入门到精通[四]
在上一篇博客Python基本语法,python入门到精通[二]已经为大家简单介绍了一下python的基本语法,上一篇博客的基本语法只是一个预览版的,目的是让大家对python的基本语法有个大概的了解. ...
- Python基本语法,python入门到精通[二]
在上一篇博客Windows搭建python开发环境,python入门到精通[一]我们已经在自己的windows电脑上搭建好了python的开发环境,这篇博客呢我就开始学习一下Python的基本语法.现 ...
- visual studio 2015 搭建python开发环境,python入门到精通[三]
在上一篇博客Windows搭建python开发环境,python入门到精通[一]很多园友提到希望使用visual studio 2013/visual studio 2015 python做demo, ...
- python入门教程链接
python安装 选择 2.7及以上版本 linux: 一般都自带 windows: https://www.python.org/downloads/windows/ mac os: https:/ ...
随机推荐
- (转) Arcgis4js实现链家找房的效果
http://blog.csdn.net/gisshixisheng/article/details/71009901 概述 买房的各位亲们不知是否留意过链家的"地图找房",这样的 ...
- antiSMASH数据库:微生物次生代谢物合成基因组簇查询和预测
2017年4月28日,核酸研究(Nucleic Acids Research)杂志上,在线公布了一个可搜索微生物次生代谢物合成基因组簇的综合性数据库antiSMASH数据库 4.0版,前3版年均引用2 ...
- Linux 之CentOS7使用firewalld打开关闭防火墙与端口
一.firewalld的基本使用 启动: systemctl start firewalld 关闭: systemctl stop firewalld 查看状态: systemctl status f ...
- 想学Python?这里有一个最全面的职位分析
Python从2015年开始,一直处于火爆的趋势,目前Python工程师超越Java.Web前端等岗位,起薪在15K左右,目前不管是小公司还是知名大公司都在热招中. 当然,每个城市对岗位的需求也不尽相 ...
- How To:防火墙规则去重
主要命令 iptables-save| awk ' !x[$0]++ | iptables-restore 演示: [root@testname ~]# iptables -vL Chain INPU ...
- 原型链、构造函数、箭头函数、se6数组去重
原型链 例子如下: var arr = [1, 2, 3]; 其原型链为:arr ----> Array.prototype ----> Object.prototype ----> ...
- 数据结构与算法(4) -- list、queue以及stack
今天主要给大家介绍几种数据结构,这几种数据结构在实现原理上较为类似,我习惯称之为类list的容器.具体有list.stack以及queue. list的节点Node 首先介绍下node,也就是组成li ...
- web前端学习总结--HTML
web三要素: 浏览器:向服务器发起请求,下载服务器中的网页(HTML),然后执行HTML显示出内容 服务器:接受浏览器的请求,发送相应的页面到浏览器 HTTP协议:浏览器与服务器的通讯协议. HTM ...
- 2019-02-13 Python爬虫问题 NotImplementedError: Only the following pseudo-classes are implemented: nth-of-type.
soup=BeautifulSoup(html.text,'lxml') #data=soup.select('body > div.main > div.ctr > div > ...
- Vue项目搭建及原理四
四.Vue-cli工作原理及Vue实例创建,工作原理 (一)Vue-cli原理 1.webpack其实使用了node.js的express网页服务器来进行处理网页相关的数据,相当于使用一个类似apac ...