分布式缓存--系列1 -- Hash环/一致性Hash原理
当前,Memcached、Redis这类分布式kv缓存已经非常普遍。从本篇开始,本系列将分析分布式缓存相关的原理、使用策略和最佳实践。
我们知道Memcached的分布式其实是一种“伪分布式”,也就是它的服务器结点之间其实是相互无关联的,之间没有网络拓扑关系,由客户端来决定一个key是存放到哪台机器。
具体来讲,假设我有多台memcached服务器,编号分别为m0,m1,m2,…。对于一个key,由客户端来决定存放到哪台机器,那最简单的hash公式就是 key % N,其中N是机器的总数。
但这有个问题,一旦机器数变少,或者增加机器,N发生变化,那之前存放的数据就全部无效了。因为你按照新的N值取模计算出的机器编号,和当时按旧的N值取模算出的机器编号肯定是不等的,也就意味着绝大部分缓存会失效。
这个问题的解决办法就是用1种特别的Hash函数,尽可能使得,增加机器/减少机器时,缓存失效的数目降到最低,这就是Hash环,或者叫一致性Hash。
有兴趣朋友可以关注公众号“架构之道与术”, 获取最新文章。
或扫描如下二维码:

Hash环
上面说的Hash函数,只经过了1次hash,即把key hash到对应的机器编号。
而Hash环有2次Hash:
(1)把所有机器编号hash到这个环上
(2)把key也hash到这个环上。然后在这个环上进行匹配,看这个key和哪台机器匹配。
具体来讲,如下:
假定有这样一个Hash函数,其值空间为(0到2的32次方-1) ,也就是说,其hash值是个32位无整型数字 ,这些数字组成一个环。
然后,先对机器进行hash(比如根据机器的ip),算出每台机器在这个环上的位置; 再对key进行hash,算出该key在环上的位置,然后从这个位置往前走,遇到的第一台机器就是该key对应的机器,就把该(key, value) 存储到该机器上。
如下图所示:
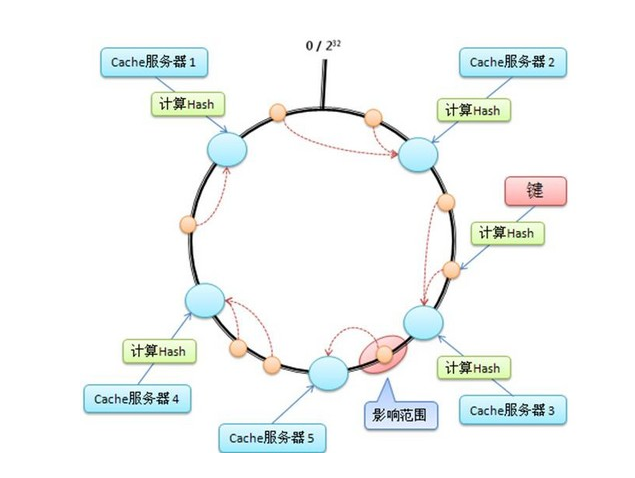
首先计算出每台Cache服务器在环上的位置(图中的大圆圈);然后每来一个(key, value),计算出在环上的位置(图中的小圆圈),然后顺时针走,遇到的第1个机器,就是其要存储的机器。
这里的关键点是:当你增加/减少机器时,其他机器在环上的位置并不会发生改变。这样只有增加的那台机器、或者减少的那台机器附近的数据会失效,其他机器上的数据都还是有效的。
数据倾斜问题
当你机器不多的时候,很可能出现几台机器在环上面贴的很近,不是在环上均匀分布。这将会导致大部分数据,都会集中在某1台机器上。
为了解决这个问题,可以引入“虚拟机器”的概念,也就是说:1台机器,我在环上面计算出多个位置。怎么弄呢? 假设用机器的ip来hash,我可以在ip后面加上几个编号, ip_1, ip_2, ip_3, .. 把1台物理机器生个多个虚拟机器的编号。
数据首先映射到“虚拟机器上”,再从“虚拟机器”映射到物理机器上。因为虚拟机器可以很多,在环上面均匀分布,从而保证数据均匀分布到物理机器上面。
ZK的引入
上面我们提到了服务器的机器增加、减少,问题是客户端怎么知道呢?
一种笨办法就是手动的,当服务器机器增加、减少时候,重新配置客户端,重启客户端。
另外一种,就是引入ZK,服务器的节点列表注册到ZK上面,客户端监听ZK。发现结点数发生变化,自动更新自己的配置。
当然,不用ZK,用一个其他的中心结点,只要能实现这种更改的通知,也是可以的。
分布式缓存--系列1 -- Hash环/一致性Hash原理的更多相关文章
- 分布式缓存 - hash环/一致性hash
一 引言 当前memcached,redis这类分布式kv缓存已经非常普遍.我们知道memcached的分布式其实是一种"伪分布式",也就是它的服务器节点之间其实是无关联的,之间没 ...
- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 分布式理论系列(二)一致性算法:2PC 到 3PC 到 Paxos 到 Raft 到 Zab
分布式理论系列(二)一致性算法:2PC 到 3PC 到 Paxos 到 Raft 到 Zab 本文介绍一致性算法: 2PC 到 3PC 到 Paxos 到 Raft 到 Zab 两类一致性算法(操作原 ...
- hash·余数hash和一致性hash
网站的伸缩性架构中,分布式的设计是现在的基本应用. 在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法 一.余数Hash 简单的路由算法可以使用余数Hash: ...
- 【分布式缓存系列】Redis实现分布式锁的正确姿势
一.前言 在我们日常工作中,除了Spring和Mybatis外,用到最多无外乎分布式缓存框架——Redis.但是很多工作很多年的朋友对Redis还处于一个最基础的使用和认识.所以我就像把自己对分布式缓 ...
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
前言: 自从CYQ.Data框架出了数据库读写分离.分布式缓存MemCache.自动缓存等大功能之后,就进入了频繁的细节打磨优化阶段. 从以下的更新列表就可以看出来了,3个月更新了100条次功能: 3 ...
- 【分布式缓存系列】集群环境下Redis分布式锁的正确姿势
一.前言 在上一篇文章中,已经介绍了基于Redis实现分布式锁的正确姿势,但是上篇文章存在一定的缺陷——它加锁只作用在一个Redis节点上,如果通过sentinel保证高可用,如果master节点由于 ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
随机推荐
- sencha touch 入门系列 (九) sencha touch 布局layout
布局用来描述你应用程序中组件的大小和位置,在sencha touch中,为我们提供了下面几种布局: 1.HBox: HBox及horizontal box布局,我们这里将其称为水平布局,下面是一段演示 ...
- 删除编辑文件警告Swap file “…” already exists!
Linux下多个用户同时编辑一个文件,或编辑时非正常关闭,再下次编辑打开文件时均为显示如下警告信息: Swap file "test.xml.swp" already exists ...
- 电力项目十八--DOM对象的ajax
Ajax操作的核心对象:xmlreq = new XMLHttpRequest(); 第一步:在dictionaryIndex.jsp中添加: <script type="text/j ...
- This function has none of DETERMINISTIC, NO SQL
错误信息: [Err] 1418 - This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declara ...
- Thinkphp --- 路由定义
thinkPHP的路由: thinkphp下的 conf 下可以进行配置:(154行) /* 系统变量名称设置 */ 'VAR_MODULE' => 'm', // 默认模块获取变量 'VAR_ ...
- mongodb拆库分表脚本
脚本功能: 1. 将指定的报告文件按照指定的字段.切库切表策略切分 2. 将切分后的文件并发导入到对应的Mongodb中 3. 生成日志文件和done标识文件 使用手册: -h 打印帮助信息,并 ...
- 阿里云服务器被挖矿程序minerd入侵的终极解决办法[转载]
突然发现阿里云服务器CPU很高,几乎达到100%,执行 top c 一看,吓一跳,结果如下: root 386m S : /tmp/AnXqV -B -a cryptonight -o stratum ...
- jq简单城市二级联动实现
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Android官方架构组件介绍之LiveData
LiveData LiveData是一个用于持有数据并支持数据可被监听(观察).和传统的观察者模式中的被观察者不一样,LiveData是一个生命周期感知组件,因此观察者可以指定某一个LifeCycle ...
- Network of Schools---poj1236(强连通分量)
题目链接 题意:学校有一些单向网络,现在需要传一些文件 求:1,求最少需要向几个学校分发文件才能让每个学校都收到, 2,需要添加几条网络才能从任意一个学校分发都可以传遍所有学校. 解题思路(参考大神的 ...