Stacking方法详解
集成学习方法主要分成三种:bagging,boosting 和 Stacking。这里主要介绍Stacking。
stacking严格来说并不是一种算法,而是精美而又复杂的,对模型集成的一种策略。
首先来看一张图。
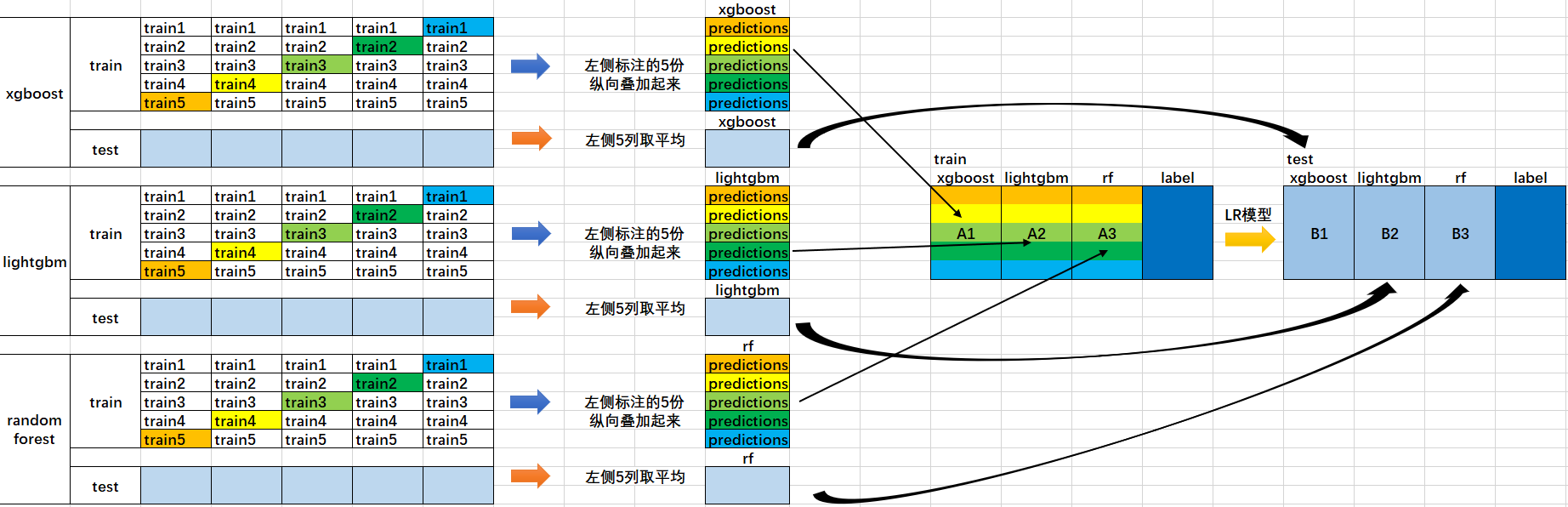
1、首先我们会得到两组数据:训练集和测试集。将训练集分成5份:train1,train2,train3,train4,train5。
2、选定基模型。这里假定我们选择了xgboost, lightgbm 和 randomforest 这三种作为基模型。比如xgboost模型部分:依次用train1,train2,train3,train4,train5作为验证集,其余4份作为训练集,进行5折交叉验证进行模型训练;再在测试集上进行预测。这样会得到在训练集上由xgboost模型训练出来的5份predictions,和在测试集上的1份预测值B1。将这五份纵向重叠合并起来得到A1。lightgbm和randomforest模型部分同理。
3、三个基模型训练完毕后,将三个模型在训练集上的预测值作为分别作为3个"特征"A1,A2,A3,使用LR模型进行训练,建立LR模型。
4、使用训练好的LR模型,在三个基模型之前在测试集上的预测值所构建的三个"特征"的值(B1,B2,B3)上,进行预测,得出最终的预测类别或概率。
做stacking,首先需要安装mlxtend库。安装方法:进入Anaconda Prompt,输入命令 pip install mlxtend 即可。
stacking主要有几种使用方法:
1、最基本的使用方法,即使用基分类器所产生的预测类别作为meta-classifier“特征”的输入数据
from sklearn import datasets iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np basemodel1 = XGBClassifier()
basemodel2 = lgb.LGBMClassifier()
basemodel3 = RandomForestClassifier(random_state=1) lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3],
meta_classifier=lr) print('5-fold cross validation:\n') for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf],
['xgboost',
'lightgbm',
'Random Forest',
'StackingClassifier']): scores = model_selection.cross_val_score(basemodel,X, y,
cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
2、这一种是使用第一层所有基分类器所产生的类别概率值作为meta-classfier的输入。需要在StackingClassifier 中增加一个参数设置:use_probas = True。
另外,还有一个参数设置average_probas = True,那么这些基分类器所产出的概率值将按照列被平均,否则会拼接。
例如:
基分类器1:predictions=[0.2,0.2,0.7]
基分类器2:predictions=[0.4,0.3,0.8]
基分类器3:predictions=[0.1,0.4,0.6]
1)若use_probas = True,average_probas = True,
则产生的meta-feature 为:[0.233, 0.3, 0.7]
2)若use_probas = True,average_probas = False,
则产生的meta-feature 为:[0.2,0.2,0.7,0.4,0.3,0.8,0.1,0.4,0.6]
from sklearn import datasets iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np basemodel1 = XGBClassifier()
basemodel2 = lgb.LGBMClassifier()
basemodel3 = RandomForestClassifier(random_state=1)
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3],
use_probas=True,
average_probas=False,
meta_classifier=lr) print('5-fold cross validation:\n') for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf],
['xgboost',
'lightgbm',
'Random Forest',
'StackingClassifier']): scores = model_selection.cross_val_score(basemodel,X, y,
cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
3、这一种方法是对基分类器训练的特征维度进行操作的,并不是给每一个基分类器全部的特征,而是赋予不同的基分类器不同的特征。比如:基分类器1训练前半部分的特征,基分类器2训练后半部分的特征。这部分的操作是通过sklearn中的pipelines实现。最终通过StackingClassifier组合起来。
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from xgboost.sklearn import XGBClassifier
from sklearn.ensemble import RandomForestClassifier iris = load_iris()
X = iris.data
y = iris.target
#基分类器1:xgboost
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)),
XGBClassifier())
#基分类器2:RandomForest
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)),
RandomForestClassifier()) sclf = StackingClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression()) sclf.fit(X, y)
StackingClassifier使用API和参数说明:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。

Stacking方法详解的更多相关文章
- 集成学习总结 & Stacking方法详解
http://blog.csdn.net/willduan1/article/details/73618677 集成学习主要分为 bagging, boosting 和 stacking方法.本文主要 ...
- session的使用方法详解
session的使用方法详解 Session是什么呢?简单来说就是服务器给客户端的一个编号.当一台WWW服务器运行时,可能有若干个用户浏览正在运正在这台服务器上的网站.当每个用户首次与这台WWW服务器 ...
- Kooboo CMS - Html.FrontHtml[Helper.cs] 各个方法详解
下面罗列了方法详解,每一个方法一篇文章. Kooboo CMS - @Html.FrontHtml().HtmlTitle() 详解 Kooboo CMS - Html.FrontHtml.Posit ...
- HTTP请求方法详解
HTTP请求方法详解 请求方法:指定了客户端想对指定的资源/服务器作何种操作 下面我们介绍HTTP/1.1中可用的请求方法: [GET:获取资源] GET方法用来请求已被URI识别的资源.指定 ...
- ecshop后台增加|添加商店设置选项和使用方法详解
有时候我们想在Ecshop后台做个设置.radio.checkbox 等等来控制页面的显示,看看Ecshop的设计,用到了shop_config这个商店设置功能 Ecshop后台增加|添加商店设置选项 ...
- (转)Spring JdbcTemplate 方法详解
Spring JdbcTemplate方法详解 文章来源:http://blog.csdn.net/dyllove98/article/details/7772463 JdbcTemplate主要提供 ...
- C++调用JAVA方法详解
C++调用JAVA方法详解 博客分类: 本文主要参考http://tech.ccidnet.com/art/1081/20050413/237901_1.html 上的文章. C++ ...
- windows.open()、close()方法详解
windows.open()方法详解: window.open(URL,name,features,replace)用于载入指定的URL到新的或已存在的窗口中,并返回代表新窗口的Win ...
- CURL使用方法详解
php采集神器CURL使用方法详解 作者:佚名 更新时间:2016-10-21 对于做过数据采集的人来说,cURL一定不会陌生.虽然在PHP中有file_get_contents函数可以获取远程 ...
随机推荐
- c# 数据集调试工具插件
DataSetSpySetup,调试期查看dataset数据集的记录内容, Debug DataSet
- 内存表 FDMemTable ClientDataSet CreateDataSet 动态创建字段
https://community.embarcadero.com/index.php/blogs/entry/firedac-in-memory-dataset-tfdmemtable Client ...
- GitHub中README.md文件的编辑和使用
最近对它的README.md文件颇为感兴趣.便写下这贴,帮助更多的还不会编写README文件的同学们. README文件后缀名为md.md是markdown的缩写,markdown是一种编辑博客的语言 ...
- CentOS上安装 jdk
先下载最新的jdk版本 文件名:jdk-8u5-linux-x64.rpm 将文件通过winscp上传到/usr/local目录中 rpm -ivh jdk-8u5-linux-x64.rpm 系统会 ...
- sql注入及事务
Statement会有一个关于sql注入的bug ,所以基本不使用 一般使用PreparedStatement import java.sql.Connection;import java.sql.P ...
- ios7 导航栏适配
ios ui开发过程中,经常会使用到导航栏,默认的样式比较单一,所以经常需要修改导航栏的样式 ios4: - (void)drawRect:(CGRect)rect { UIImage *image ...
- ORA-01795: maximum number of expressions in a list is 1000
今天发现查询Oracle用In查询In的元素不可以超过1000个还需要分成多个1000查询记录博客备忘!! Load Test的时候发现这么如下这个错误.... ORA-01795: maximum ...
- send anywhere真的好用啊
手机和电脑互传文件,方便很多.
- Golang基本结构之练习(day2)
笔记: . 任何一个代码文件隶属于一个包 . import 关键字,引用其他包: import(“fmt”) import(“os”) 通常习惯写成: import ( “fmt” “os” ) . ...
- jQuery绑定事件的四種方式
这篇文章主要介绍的是jQuery绑定事件的四种方式相关内容,下面我们就与大家一起分享. jQuery绑定事件的四种方式 jQuery提供了多种绑定事件的方式,每种方式各有其特点,明白了它们之间的异同点 ...