IDEA开发Spark的漫漫摸索(一)
系统:Win10
01 安装IDEA
IDEA版本:IntelliJ IDEA 2017.2.1 64位
使用的学生授权下载的ultimate版本,此处不赘叙安装过程。
02安装编译环境
Spark可以通过Maven和SBT两种方式进行编译,再通过make-distribution.sh脚本生成部署包。考虑到更适用于java语言,选择Maven进行编译。Maven方式编译需要Maven工具,且需要在联网状态下载依赖包。
先在Apache官网下载相应的Maven压缩包,我下载的是apche-maven-3.5.0-bin.zip,在想要安装的位置将压缩包解压。压缩包里面有一个READ.ME文档,我没按那个操作来,直接百度的安装教程来的。
虽然说是安装教程,但实际上只是将整个文件夹放在想放的位置,再配置一下环境变量。
需要配置的环境变量有两个。
新加一个环境变量,命名为M2_HOME,值就是解压的文件夹路径,比如我的是D:\Program Files\apache-maven-3.5.0。
找到另外一个环境变量Path,在后面加上一个值 %M2_HOME%\bin;
关于环境变量,需要提出注意的:一个是不要把之前的值删掉了,我第一次自己配环境就把前面的值删掉了,结果很麻烦才弄好。再就是,win7和win10的显示有所不同,win7的要注意值后面的;千万不能掉,win10每个值的单独的,后面不用加;。
在环境变量配置结束后,要来测试一下环境是否配置成功。测试的方法就是通过cmd调出命令提示符窗口,输入mvn -v 查看。

得到如图结果则说明Maven安装成功。
使用命令mvn help:system 会下载相应的包到本地仓库。

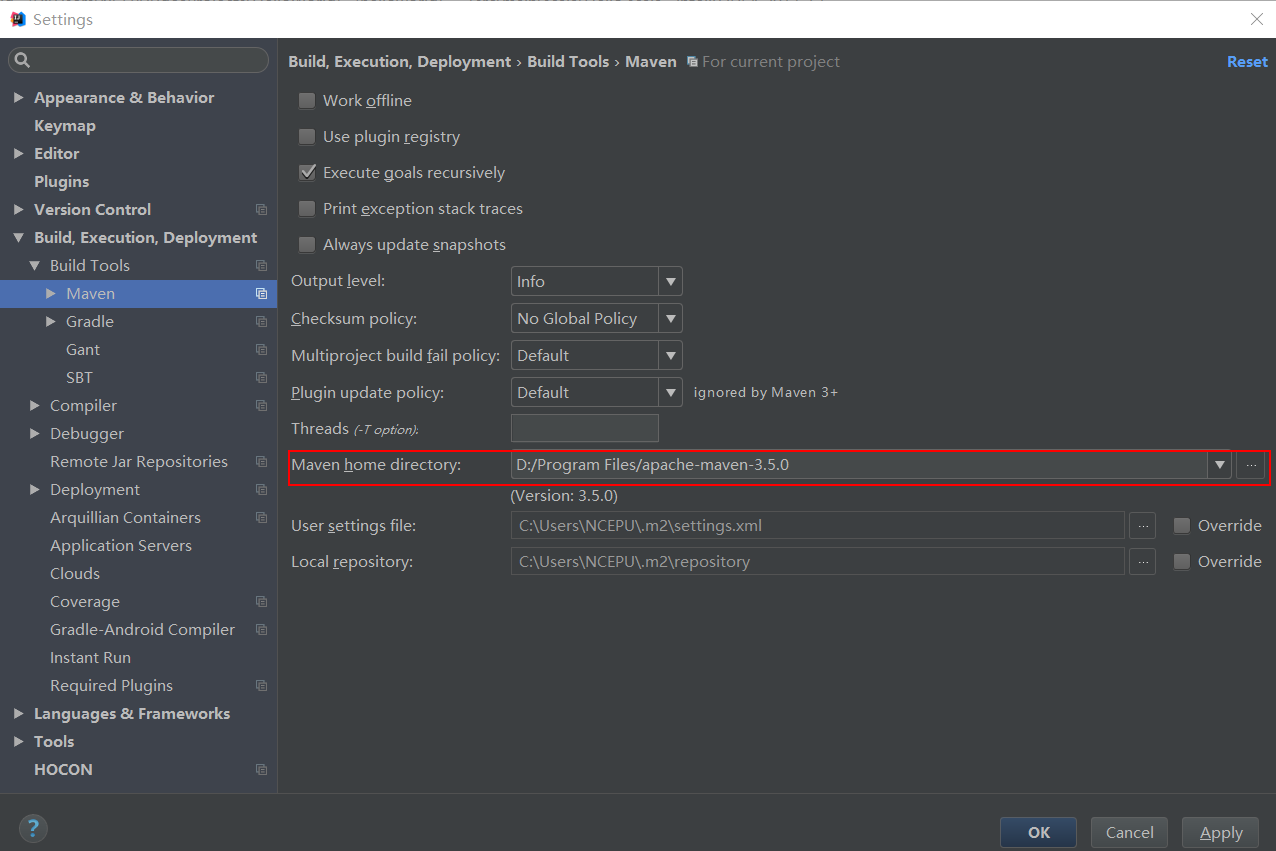
随后将下载好的Maven配置到IDEA中,File→Setting→Build,Execution,Deployment→Build Tools→Maven,点击Maven home directory选择刚才安装的Maven。
03 配置JDK
jdk版本:jdk1.8.0_31

这是在安装IDEA中创建的第一个项目。先前已经安装过JDK,但是此处IDEA不能自动识别,‘’Project SDK‘’后显示“no SDK”。所以,在此处选择手动加入。点击右上角的"New..."来查找JDK所在的位置,然后将整个JDK的包加入,就可以了。
可能由于版本或者其他的原因,有的时候不会在创建项目的时候就要求必须配置JDK。在这种情况下, 我们可以选择File——>Project Structure进行配置设置界面。
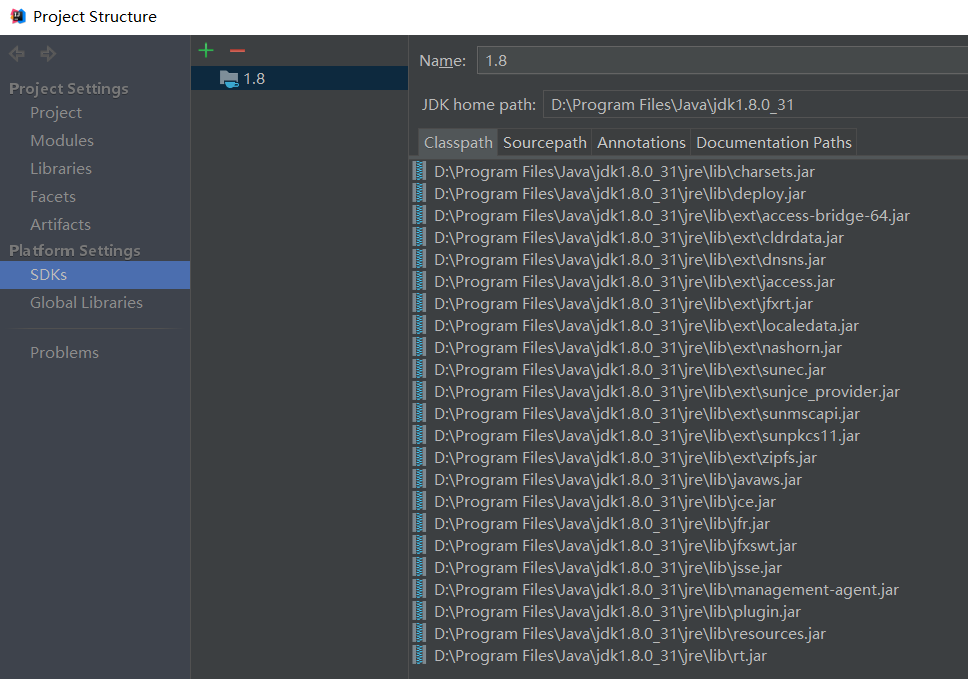
Platform Setteings/SDKs 中间那栏显示的是已经配置好的JDK,如果想要加入新的JDK,就点击中间栏上方的“+”来添加。
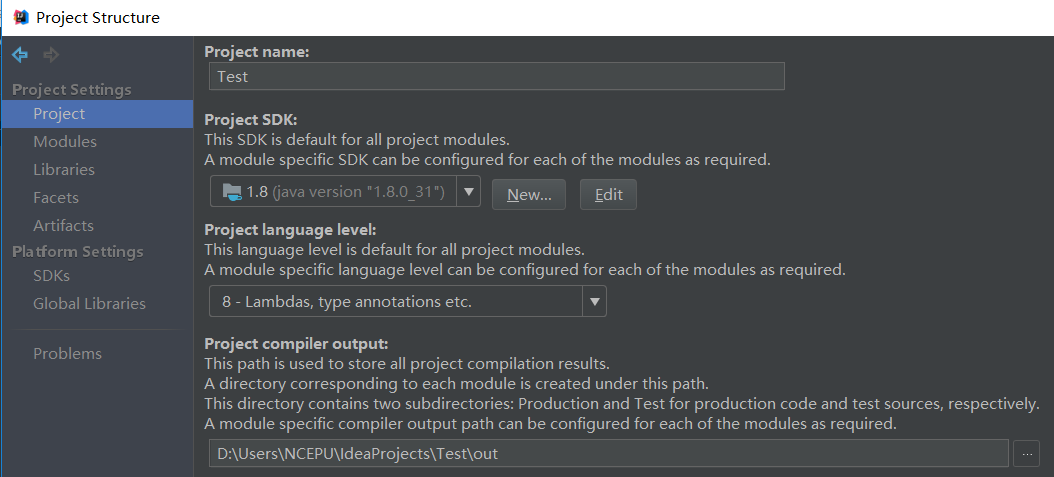
也可以在Project Settings/Project 处,找到Project SDK,点击“New...”来实现JDK的添加。
04 安装Scala插件
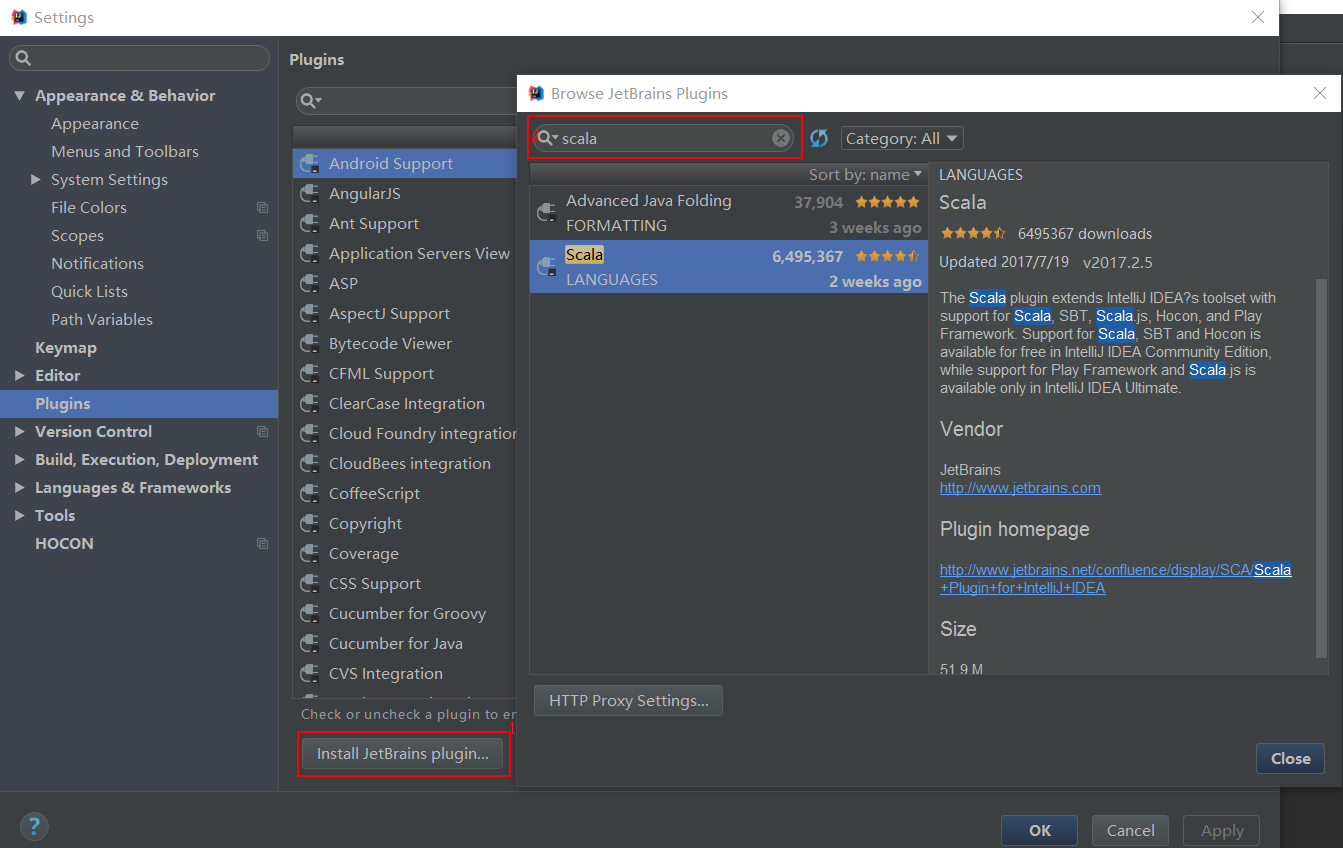
先点击Install JetBrains plugins,接着在插件的搜索栏里输入“scala”,出现搜索结果,选择scala,点击“Install”进行安装。(图中我已经提前完成安装,所以没有Installa按钮)
IDEA开发Spark的漫漫摸索(一)的更多相关文章
- IDEA开发Spark的漫漫摸索(二)
1 新建Maven项目 特别提醒,Maven项目中有GropId和ArtifactId.GroupId是项目组织唯一的标识符,实际对应JAVA的包的结构,是main目录里java的目录结构.一般Gru ...
- 使用scala开发spark入门总结
使用scala开发spark入门总结 一.spark简单介绍 关于spark的介绍网上有很多,可以自行百度和google,这里只做简单介绍.推荐简单介绍连接:http://blog.jobbole.c ...
- 利用Scala语言开发Spark应用程序
Spark内核是由Scala语言开发的,因此使用Scala语言开发Spark应用程序是自然而然的事情.如果你对Scala语言还不太熟悉,可 以阅读网络教程A Scala Tutorial for Ja ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
- windows下Idea结合maven开发spark和本地调试
本人的开发环境: 1.虚拟机centos 6.5 2.jdk 1.8 3.spark2.2.0 4.scala 2.11.8 5.maven 3.5.2 在开发和搭环境时必须注意版本兼容的问题 ...
- 使用IDEA开发SPARK提交remote cluster执行
开发环境 操作系统:windows 开发工具:IntelliJ IDEA 14.1.1 需要安装scala插件 编译环境:jdk 1.7 scala 2.10.4 使用IDEA开发spark应用 ...
- FusionInsight大数据开发---Spark应用开发
Spark应用开发 要求: 了解Spark基本原理 搭建Spark开发环境 开发Spark应用程序 调试运行Spark应用程序 YARN资源调度,可以和Hadoop集群无缝对接 Spark适用场景大多 ...
- 【机器学习之一】python开发spark环境搭建
环境 spark-1.6 python3.5 一.python开发spark原理使用python api编写pyspark代码提交运行时,为了不破坏spark原有的运行架构,会将写好的代码首先在pyt ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
随机推荐
- linux命令学习笔记(61):tree 命令
shendu@shenlan:~$ tree 程序“tree”尚未安装. 您可以使用以下命令安装: sudo apt-get install tree shendu@shenlan:~$ sudo a ...
- freeMarker(十四)——XML处理指南之必要的XML处理
学习笔记,选自freeMarker中文文档,译自 Email: ddekany at users.sourceforge.net 1.基本内容 假设程序员在数据模型中放置了一个XML文档,就是名为 d ...
- Metasploit的使用下篇——漏洞攻击
一.上文总结 上篇当中主要通过开启的端口对目标主机进行攻击,最后成功做到了连接不过却不能查看到telnet的登陆用户名和密码,目前来看有两个原因:第一.我对于靶机telnet的设置有问题,没有设置相应 ...
- ACM学习历程—SGU 275 To xor or not to xor(xor高斯消元)
题目链接:http://acm.sgu.ru/problem.php?contest=0&problem=275 这是一道xor高斯消元. 题目大意是给了n个数,然后任取几个数,让他们xor和 ...
- BZOJ4695:最假女选手
浅谈区间最值操作和历史最值问题:https://www.cnblogs.com/AKMer/p/10225100.html 题目传送门:https://lydsy.com/JudgeOnline/pr ...
- 洛谷【P1138】第k小整数
题目传送门:https://www.luogu.org/problemnew/show/P1138 桶排: 对于值域在可以接受的范围内时,我们可以用不依赖比较的桶排去将数据排序.因为桶排不依赖比较排序 ...
- python中全局变量的使用
python中在module定义的变量可以认为是全局变量, 而对于全局变量的赋值有个地方需要注意. test.py ------------------------------------------ ...
- linux python 更新版本
更新python: 第1步:更新gcc,因为gcc版本太老会导致新版本python包编译不成功 代码如下: #yum -y install gcc 系统会自动下载并安装或更新,等它自己结束 第2步:下 ...
- HDOJ1059(多重背包)
1.解法一:多重背包 #include<iostream> #include<cstdio> using namespace std; #define MAX(a,b) (a& ...
- puppet插件fact和hiera(puppet自动化系列3)
四.Fact插件 4.1 使用pluginsync进行发布 这种方法比较特殊,节点factpath目录里除了编写好的rb文件之外,还需要在puppet模块中引用,运行一次之后才会转换成fact.通常在 ...