Hadoop实战:明星搜索指数统计,找出人气王
项目介绍
本项目我们使用明星搜索指数数据,分别统计出搜索指数最高的男明星和女明星。
数据集
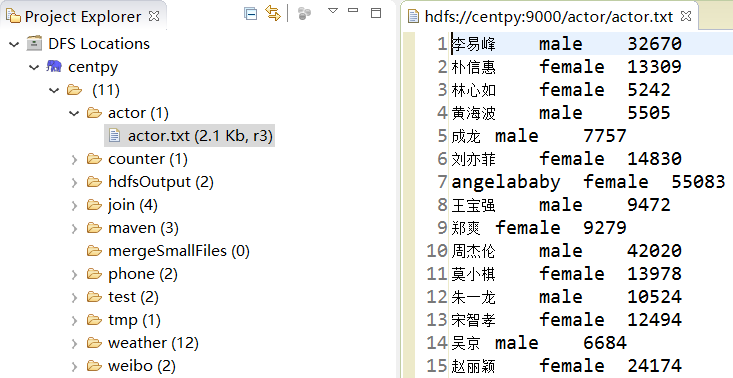
明星搜索指数数据集,如下图所示。猛戳此链接下载数据集
思路分析
基于项目的需求,我们通过以下几步完成:
1、编写 Mapper类,按需求将数据集解析为 key=gender,value=name+hotIndex,然后输出。
2、编写 Combiner 类,合并 Mapper 输出结果,然后输出给 Reducer。
3、编写 Partitioner 类,按性别,将结果指定给不同的 Reduce 执行。
4、编写 Reducer 类,分别统计出男、女明星的最高搜索指数。
5、编写 run 方法执行 MapReduce 任务。
MapReduce Java 项目
设计的MapReduce如下所示:
Map = {key = gender, value = name+hotIndex}
Reduce = {key = name, value = gender+hotIndex}
Map
每次调用map(LongWritable key, Text value, Context context)解析一行数据。每行数据存储在value参数值中。然后根据'\t'分隔符,解析出明星姓名,性别和搜索指数。
public static class ActorMapper extends Mapper< Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//value=name+gender+hotIndex
String[] tokens = value.toString().split("\t");
String gender = tokens[].trim();//性别
String nameHotIndex = tokens[] + "\t" + tokens[];//名称和搜索指数
context.write(new Text(gender), new Text(nameHotIndex));
}
}
map()函数期望的输出结果Map = {key = gender, value = name+hotIndex}
Combiner
对 map 端的输出结果,先进行一次合并,减少数据的网络输出。
public static class ActorCombiner extends Reducer< Text, Text, Text, Text> {
private Text text = new Text();
@Override
public void reduce(Text key, Iterable< Text> values, Context context) throws IOException, InterruptedException {
int maxHotIndex = Integer.MIN_VALUE;
int hotIndex = ;
String name="";
for (Text val : values) {
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[]);
if(hotIndex>maxHotIndex){
name = valTokens[];
maxHotIndex = hotIndex;
}
}
text.set(name+"\t"+maxHotIndex);
context.write(key, text);
}
}
Partitioner
根据明星性别对数据进行分区,将 Mapper 的输出结果均匀分布在 reduce 上。
public static class ActorPartitioner extends Partitioner< Text, Text> {
@Override
public int getPartition(Text key, Text value, int numReduceTasks) {
String sex = key.toString();
if(numReduceTasks==)
return ;
//性别为male 选择分区0
if(sex.equals("male"))
return ;
//性别为female 选择分区1
if(sex.equals("female"))
return % numReduceTasks;
//其他性别 选择分区2
else
return % numReduceTasks;
}
}
Reduce
调用reduce(key, Iterable< Text> values, context)方法来处理每个key和values的集合。我们在values集合中,计算出明星的最大搜索指数。
public static class ActorReducer extends Reducer< Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable< Text> values, Context context) throws IOException, InterruptedException {
int maxHotIndex = Integer.MIN_VALUE;
String name = " ";
int hotIndex = ;
for (Text val : values) {
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[]);
if (hotIndex > maxHotIndex) {
name = valTokens[];
maxHotIndex = hotIndex;
}
}
context.write(new Text(name), new Text( key + "\t"+ maxHotIndex));
}
}
reduce()函数期望的输出结果Reduce = {key = name, value = gender+max(hotIndex)}
Run 驱动方法
在 run 方法中,设置任务执行各种信息。
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();//读取配置文件
Path mypath = new Path(args[]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = new Job(conf, "star");//新建一个任务
job.setJarByClass(Star.class);//主类
job.setNumReduceTasks();//reduce的个数设置为2
job.setPartitionerClass(ActorPartitioner.class);//设置Partitioner类
job.setMapperClass(ActorMapper.class);//Mapper
job.setMapOutputKeyClass(Text.class);//map 输出key类型
job.setMapOutputValueClass(Text.class);//map 输出value类型
job.setCombinerClass(ActorCombiner.class);//设置Combiner类
job.setReducerClass(ActorReducer.class);//Reducer
job.setOutputKeyClass(Text.class);//输出结果 key类型
job.setOutputValueClass(Text.class);//输出结果 value类型
FileInputFormat.addInputPath(job, new Path(args[]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[]));// 输出路径
job.waitForCompletion(true);//提交任务
return ;
}
编译和执行 MapReduce作业
1、myclipse将项目编译和打包为star.jar,使用SSH将 star.jar上传至hadoop的$HADOOP_HOME目录下。
2、使用cd $HADOOP_HOME切换到当前目录,通过命令行执行Hadoop作业
hadoop jar star.jar zimo.hadoop.Star.Star
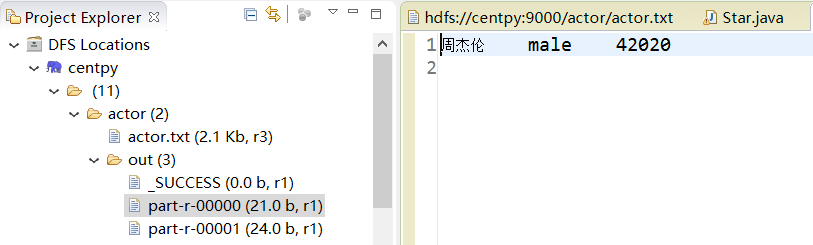
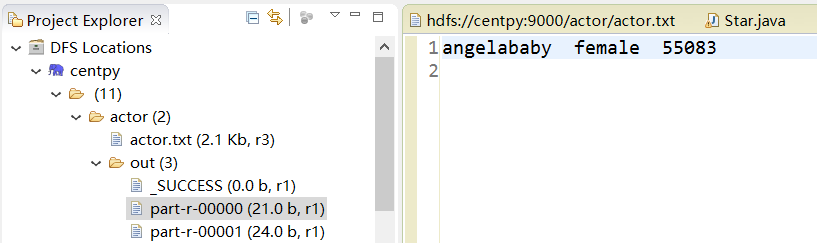
运行结果
你可以在DFS Locations界面下查看输出目录。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
Hadoop实战:明星搜索指数统计,找出人气王的更多相关文章
- MapReduce明星搜索指数统计,找出人气王
我们继续通过项目强化掌握Combiner和Partitioner优化Hadoop性能 1.项目介绍 本项目我们使用明星搜索指数数据,分别统计出搜索指数最高的男明星和女明星. 2.数据集 3.分析 基于 ...
- 通过代码审计找出网站中的XSS漏洞实战(三)
一.背景 笔者此前录制了一套XSS的视频教程,在漏洞案例一节中讲解手工挖掘.工具挖掘.代码审计三部分内容,准备将内容用文章的形式再次写一此,前两篇已经写完,内容有一些关联性,其中手工XSS挖掘篇地址为 ...
- 通过Web安全工具Burp suite找出网站中的XSS漏洞实战(二)
一.背景 笔者6月份在慕课网录制视频教程XSS跨站漏洞 加强Web安全,里面需要讲到很多实战案例,在漏洞挖掘案例中分为了手工挖掘.工具挖掘.代码审计三部分内容,手工挖掘篇参考地址为快速找出网站中可能存 ...
- Dijkstra 算法,用于对有权图进行搜索,找出图中两点的最短距离
Dijkstra 算法,用于对有权图进行搜索,找出图中两点的最短距离,既不是DFS搜索,也不是BFS搜索. 把Dijkstra 算法应用于无权图,或者所有边的权都相等的图,Dijkstra 算法等同于 ...
- C语言:对传入sp的字符进行统计,三组两个相连字母“ea”"ou""iu"出现的次数,并将统计结果存入ct所指的数组中。-在数组中找出最小值,并与第一个元素交换位置。
//对传入sp的字符进行统计,三组两个相连字母“ea”"ou""iu"出现的次数,并将统计结果存入ct所指的数组中. #include <stdio.h& ...
- Python list去重及找出,统计重复项
http://bbs.chinaunix.net/thread-1680208-1-1.html 如何找出 python list 中有重复的项 http://www.cnblogs.com/feis ...
- 机器学习进阶-项目实战-信用卡数字识别 1.cv2.findContour(找出轮廓) 2.cv2.boudingRect(轮廓外接矩阵位置) 3.cv2.threshold(图片二值化操作) 4.cv2.MORPH_TOPHAT(礼帽运算突出线条) 5.cv2.MORPH_CLOSE(闭运算图片内部膨胀) 6. cv2.resize(改变图像大小) 7.cv2.putText(在图片上放上文本)
7. cv2.putText(img, text, loc, text_font, font_scale, color, linestick) # 参数说明:img表示输入图片,text表示需要填写的 ...
- [leetcode] 230. Kth Smallest Element in a BST 找出二叉搜索树中的第k小的元素
题目大意 https://leetcode.com/problems/kth-smallest-element-in-a-bst/description/ 230. Kth Smallest Elem ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
随机推荐
- DSP/BIOS程序启动顺序
基于TI的DSP芯片的应用程序分为两种:一般应用程序:DSP/BIOS应用程序. 为简化编程,TI提供了一套C的编程接口,它以API和宏的形式封装了TI的所有硬件模块,这套接口统称DSP/BIOS.D ...
- 测试-Swagger:目录
ylbtech-测试-Swagger:目录 1.返回顶部 1. https://swagger.io/ 2.Swagger Editor http://swagger.io/swagger-edito ...
- RPG游戏地牢设计的29个要点
转自:http://www.gameres.com/491660.html Troy 是一名 RPG 开发者,以整理了一些自己开发地下城 RPG 的经验,开发者不妨参考一下: 1.地下城应该有个地方无 ...
- mac tree 命令
mac下默认是没有 tree命令的,不过我们可以使用find命令模拟出tree命令的效果,如显示当前目录的 tree 的命令: find . -print | sed -e 's;[^/]*/;|__ ...
- 奇异值分解(SVD)详解
2012-04-10 17:38 45524人阅读 评论(18) 收藏 举报 分类: 数学之美 版权声明:本文为博主原创文章,未经博主允许不得转载. SVD分解 SVD分解是LSA的数学基础,本文是 ...
- k8s 基础 k8s架构和组件
k8s 的总架构图
- nginx gzip
# 开启gzip gzip on; # 启用gzip压缩的最小文件,小于设置值的文件将不会压缩 gzip_min_length 1k; # gzip 压缩级别,1-10,数字越大压缩的越好,也 ...
- Java探索之旅(1)——概述与控制台输入
使用的课本: Java语言程序设计(基础篇)----西电 李娜(译) 原著: Introduction to Java Progrmming(Eighth Edition) -----Y.Daniel ...
- [51nod1094]和为k的连续区间
法一:暴力$O({n^2})$看脸过 #include<bits/stdc++.h> using namespace std; typedef long long ll; ],sum[]; ...
- Windows命令快捷打开
Win+R或者在搜索中输入: control -- 控制面板 mstsc -- 远程连接 SnippingTool -- 截图工具