Python爬虫学习 - day2 - 站点登陆
利用Python完成简单的站点登陆
最近学习到了爬虫,瞬时觉得很高大上,想取什么就取什么,感觉要上天。这里分享一个简单的登陆抽屉新热榜的教程(因为它不需要验证码,目前还没有学会图像识别。哈哈),供大家学习。
需要的知识点储备
本次爬虫脚本依赖两个模块:requests模块,BeautifulSoup模块。其中requests模块完成url的请求,而BeautifulSoup模块负责解析Html标签。
主要的用法在上一讲已经列出,这里不再赘述。
思路
和爬取图片的思路是相同的,首先我们人工登陆一次,确认每次交互发送接受的数据。
打开首页查看交互信息
在浏览器里访问 http://dig.chouti.com/ 打开控制台,查看网络请求信息,发现在get请求的应答信息中包涵了cookies。
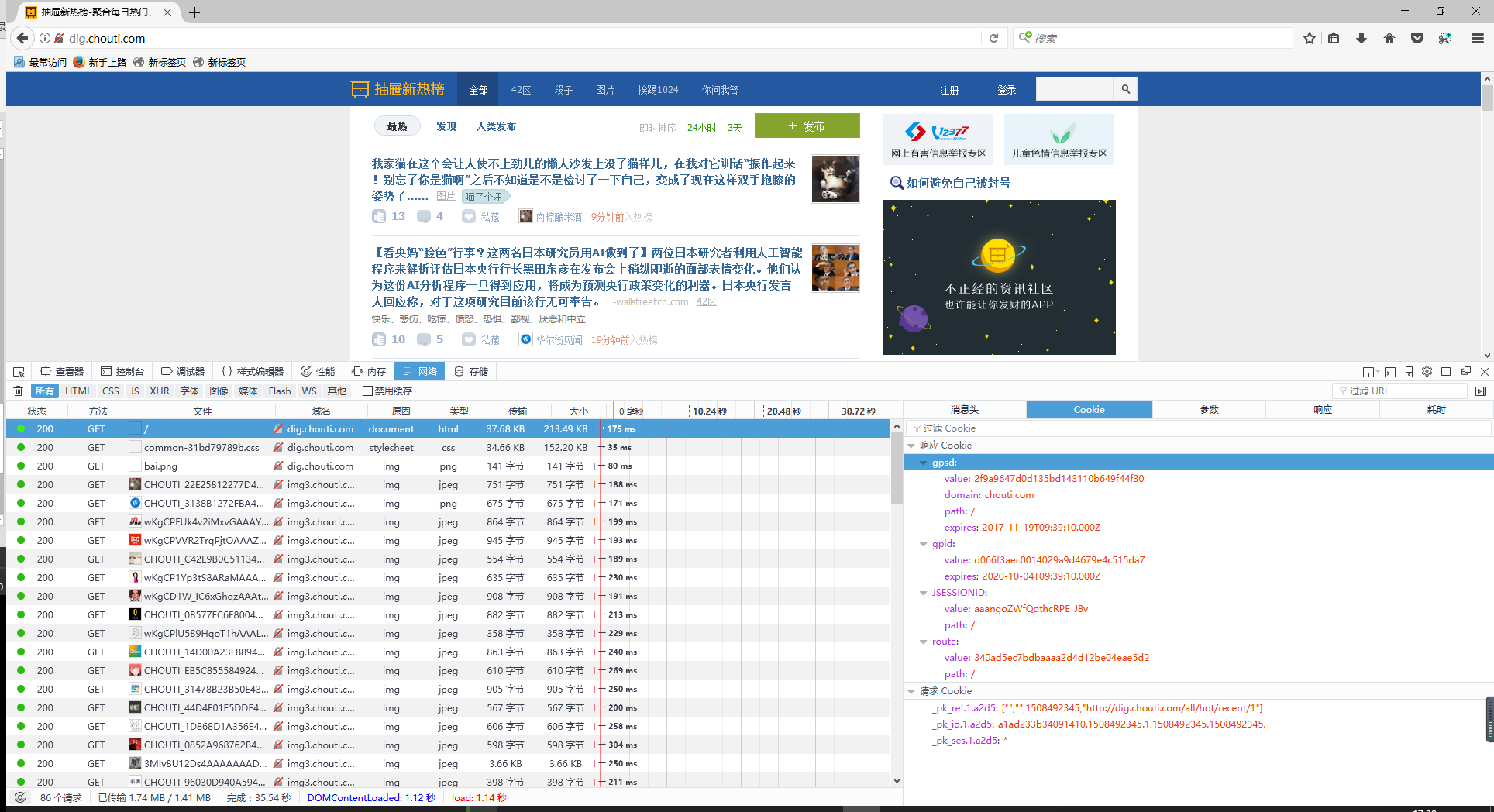
点击登陆后的交互信息
点击登陆后查看网络信息,发现只发送了用户名、密码、以及是否保存密码等参数。
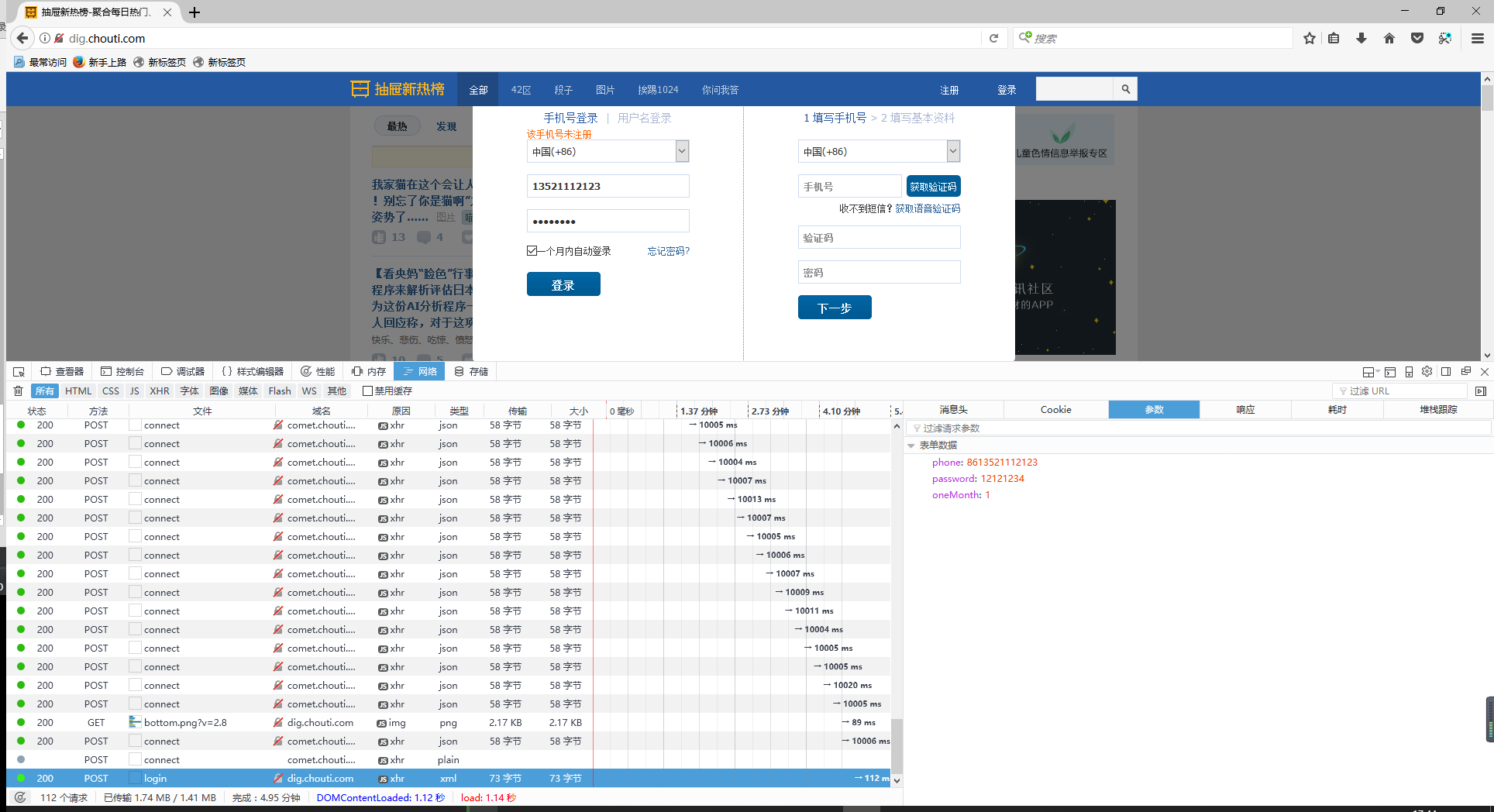
疑问:我们知道为了防止xss攻击,网站都会做一些基础的防护,比如csrf_token等,但是这里并没有看到携带什么token数据,难道是抽屉没有进行防护吗?其实不是的,目前大部分网站都采用的方式是,第一个get请求会发送未认证的cookie,当用户登陆时携带该cookies,服务端对cookies进行认证,如果登陆时没有携带cookies,服务端将会拒绝服务,所以我们要记录第一个get请求的cookies。
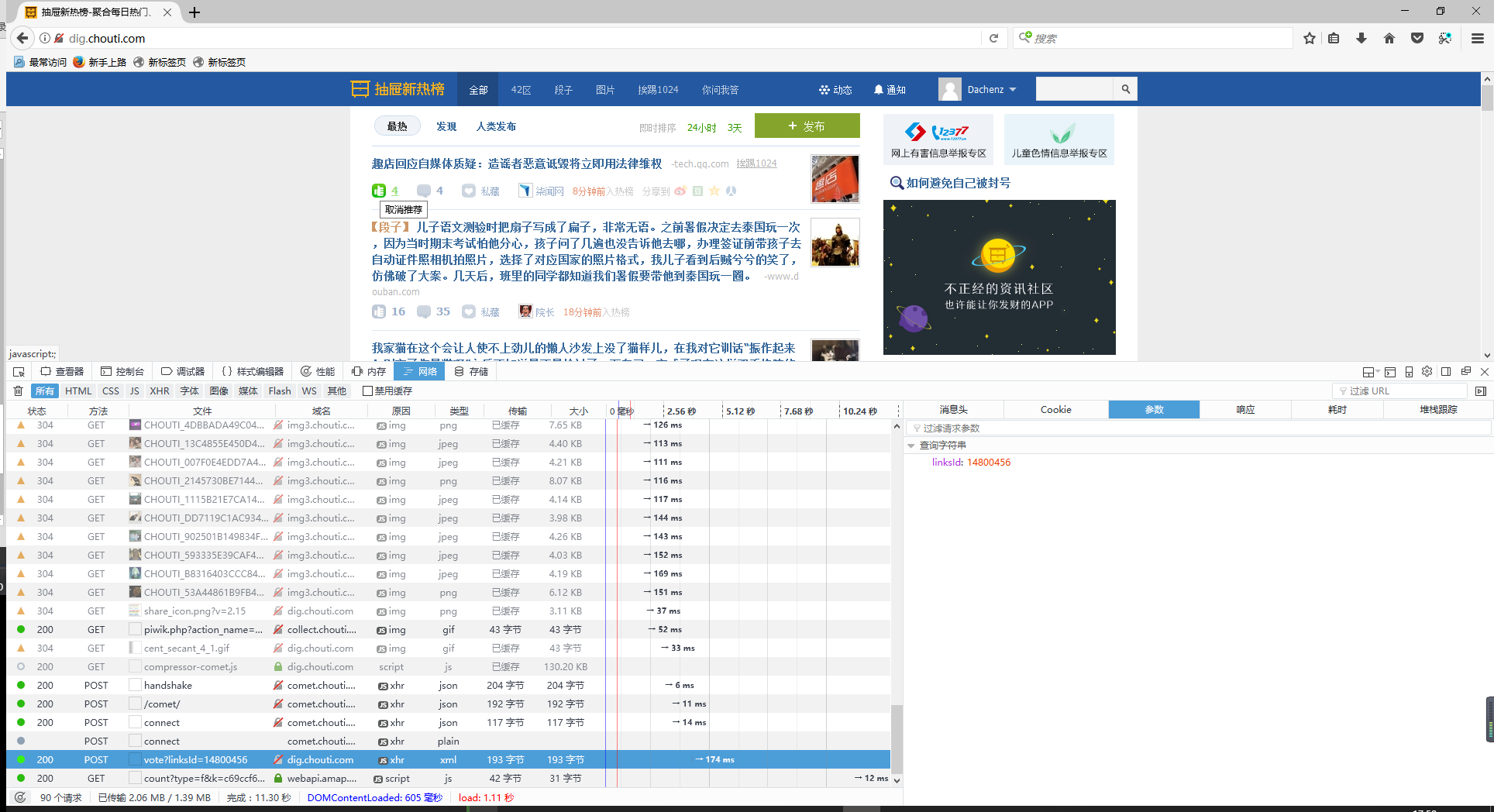
点赞后提交的信息
通过查看网络交互信息后发现,点赞后,只是向服务端发送了文章的ID。
流程
根据以上思路得出以下步骤:
- 发送get请求获取页面信息,储存cookies信息
- 向登陆页发送post请求,携带cookies信息
- 由于返回了两次cookies,保险起见,创建一个cookies字典,把多次返回的cookies,一一存储后整体提交。
- 登陆成功后,找到看到的所有文章标签,获取它的linksid
- 发送post请求携带linksid,进行点赞操作
完成的代码
import requests
from bs4 import BeautifulSoup # get请求cookies
response = requests.get('http://dig.chouti.com/')
get_cookies = response.cookies # post请求cookies
response = requests.post('http://dig.chouti.com/login',
data={
'phone':8613526773228,
'password': 'aini3845',
'oneMonth': '1',
},
cookies=get_cookies
)
login_cookies = response.cookies # 组件cookies
all_cookies = {}
all_cookies.update(get_cookies)
all_cookies.update(login_cookies) # 查询文章列表
response = requests.get('http://dig.chouti.com/',cookies=all_cookies)
soup = BeautifulSoup(response.text,'html.parser')
tag = soup.find(id="content-list") # 点赞的前缀url
urls = 'http://dig.chouti.com/link/vote' # 点赞操作
for item in tag.find_all(name='div',attrs={'class':'part2'}):
if item.get('share-linkid'):
link_id = item.get('share-linkid')
response = requests.post(urls+'?linksId=%s' % link_id,cookies=all_cookies)
print(response.text)
Python爬虫学习 - day2 - 站点登陆的更多相关文章
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
- Python爬虫学习笔记——豆瓣登陆(三)
之前是不会想到登陆一个豆瓣会需要写三次博客,修改三次代码的. 本来昨天上午之前的代码用的挺好的,下午时候,我重新注册了一个号,怕豆瓣大号被封,想用小号爬,然后就开始出问题了,发现无法模拟登陆豆瓣了,开 ...
- Python爬虫学习笔记——豆瓣登陆(二)
昨天能够登陆成功,但是不能使用cookies,今天试了一下requests库的Session(),发现可以保持会话了,代码只是稍作改动. #-*- coding:utf-8 -*- import re ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
随机推荐
- POSTMAN——环境变量
打开Manage Environment 设置几个自己的环境变量 可以在此看到设置的环境变量 在URL栏填写变量名,这个变量对应着百度的网址 send后可以查看回显 接下来设置全局变量,点开globa ...
- VSCode 前端必备插件
VSCode 前端必备插件 Debugger for Chrome 让 vscode 映射 chrome 的 debug功能,静态页面都可以用 vscode 来打断点调试 { "versio ...
- 分享 go语言爬虫---开源项目Pholcus
写在开头的话:记录一下最近学习Pholcus(https://github.com/henrylee2cn/pholcus)的过程,首先去学习的go基本语法,在没接触的时候发现很多不理解的地方,但是当 ...
- GraphSAGE 代码解析(一) - unsupervised_train.py
原创文章-转载请注明出处哦.其他部分内容参见以下链接- GraphSAGE 代码解析(二) - layers.py GraphSAGE 代码解析(三) - aggregators.py GraphSA ...
- hibernate和mybatis的之CRUD封装差别
hibernate和mybatis的之CRUD封装差别 以下讲的是基于MVC三层架构. 由于设计架构的差别,hibernate在实际编程中可以把基础的CRUD封装,比如BaseDao类.其它类只要去继 ...
- JavaScript - arguments object
The arguments object is an Array-like object corresponding to the arguments passed to a function. fu ...
- Internet History,Technology and Security
Internet History,Technology and Security(简单记录) First Week High Stakes Research in Computing,and Comm ...
- input设置为readonly后js设置intput的值后台仍然可以接收到
今天发现一个奇怪现象,一个input属性readonly的值被设置为readonly,然后有前台js给input设置了新值. 虽然前台看不到效果,但是提交到后台后,仍然可以接收到新值,感觉很奇怪. 我 ...
- Java 利用枚举实现单例模式
引言 单例模式比较常见的实现方法有懒汉模式,DCL模式公有静态成员等,从Java 1.5版本起,单元素枚举实现单例模式成为最佳的方法. Java枚举 基本用法 枚举的用法比较多,本文主要旨在介绍利用枚 ...
- hdu 1207 汉诺塔II (DP+递推)
汉诺塔II Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submi ...