爬虫学习笔记(2)--创建scrapy项目&&css选择器
一、手动创建scrapy项目
----------------
安装scrapy:
pip install -i https://pypi.douban.com/simple/ scrapy
1、创建项目
(article_spider) E:\PyCharmWorkspace>scrapy startproject ArticleSpider(项目名称)
此时只是利用现有模板创建了scrapy项目,但是没有spider
2、pycharm导入项目
1、open
2、配置解释器
file->setting->project interpreater-选择你创建的虚拟环境下script-python.exe
3、创建spider
1)进入项目目录下
(article_spider) E:\PyCharmWorkspace>cd ArticleSpider
2)创建spider
(article_spider)E:\PyCharmWorkspace\ArticleSpider>scrapy genspider jobbole(spider的名字) blog.jobbole.com(域名)
idea中spider目录下就会出现对应的py文件
4、为了可以调试scrapy,创建main文件
以后想debug的时候,直接debug该main文件即可。原理是在scrapy中调用spider(命令是scrapy crawl jobbole)
from scrapy.cmdline import execute
import sys
import os
#os.path.abspath(__file__)获取当前py文件的路径
#os.path.dirname(),获得参数文件所在文件夹的路径,即父目录
#__file__指当前py文件
print (os.path.abspath(__file__))
#在工程目录os.path.dirname(os.path.abspath(__file__))下执行命令行才有效
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
#scrapy中启动spider项目:在命令行用scrapy crawl jobbole命令
execute(["scrapy","crawl","jobbole"])
5】、cmd执行spider命令
命令:scrapy crawl jobbole
错误:ImportError: No module named 'win32api'
解决:pip install -i https://pypi.douban.com/simple pypiwin32
6、修改seeting.py(必须改)
ROBOTSTXT_OBEY = False 将true改为false
若为true会自动过滤掉不符合ROBOTS规则的url
7】、
在jobbole.py中:
执行完spider(scrapy crawl jobbole)后会有如下操作:
下载start_urls = ['http://blog.jobbole.com/']该url的页面,返回一个response
def parse(self, response):
二、基础知识
----------
0、
scrapy获得的是右击页面->查看页面源代码
右击页面->检查,的代码是运行完js之后的,并不是scrapy要爬取的
1、css选择器
----------
* 选择所有节点
#container 选择id为container的节点
.container 选择所有class包含container的节点
li a 选取所有li下的所有a节点
ul + p 选择ul后面的第一个p元素(互为兄弟节点)
div#container > ul 选取id为container的div的第一个ul子元素
2、技巧
--------
1)如何快速得到css地址
chrome 右击你要定位的元素,选择copy->copy selector 即可
2)
每次启动scrapy都比较慢,每调试一次都需要启动scrapy. shell脚本调试
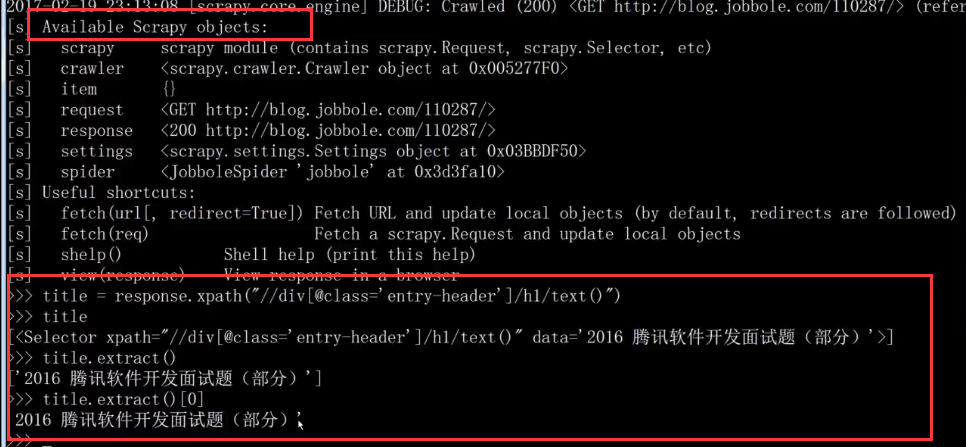
在虚拟环境下,cmd命令,执行scrapy shell http://blog.jobbole.com/112569/(对这个url进行调试),response可以调用:
3)
.strip():去除左右两边的空字符

爬虫学习笔记(2)--创建scrapy项目&&css选择器的更多相关文章
- springmvc学习笔记---idea创建springmvc项目
前言: 真的是很久没搞java的web服务开发了, 最近一次搞还是读研的时候, 想来感慨万千. 英雄没落, Eclipse的盟主地位隐隐然有被IntelliJ IDEA超越的趋势. Spring从2. ...
- yii学习笔记--快速创建一个项目
下载yii框架 下载地址:http://www.yiiframework.com/ 中文网站:http://www.yiichina.com/ 解压文件
- web前端学习(三)css学习笔记部分(4)-- CSS选择器详解
4. 元素选择器详解 4.1 元素选择器 4.2 选择器分组 用英文逗号","相连,使用相同的样式表 使用通配符对所有元素进行通用设定. 4.3 类选择器详解 4.3.1. ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- pycharm创建scrapy项目教程及遇到的坑
最近学习scrapy爬虫框架,在使用pycharm安装scrapy类库及创建scrapy项目时花费了好长的时间,遇到各种坑,根据网上的各种教程,花费了一晚上的时间,终于成功,其中也踩了一些坑,现在整理 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Django:学习笔记(2)——创建第一个应用
Django:学习笔记(2)——创建第一个应用 创建应用 在 Django 中,每一个应用都是一个 Python 包,并且遵循着相同的约定.Django 自带一个工具,可以帮你生成应用的基础目录结构, ...
- Java学习笔记-多线程-创建线程的方式
创建线程 创建线程的方式: 继承java.lang.Thread 实现java.lang.Runnable接口 所有的线程对象都是Thead及其子类的实例 每个线程完成一定的任务,其实就是一段顺序执行 ...
随机推荐
- sqlite3 PC安装及使用
sqlite3使用 1. 安装sqlite3 sudo apt-get install sqlite3 sudo apt-get install libsqlite3-dev 2. sqlite常用命 ...
- 更新换代----systemctl命令取代chkconfig和service
systemctl命令是系统服务管理器指令,它实际上将 service 和 chkconfig 这两个命令组合到一起. 任务 旧指令 新指令 使某服务自动启动 chkconfig --level 3 ...
- 使用nginx cache缓存网站数据实践
Nginx本身就有缓存功能,能够缓存静态对象,比如图片.CSS.JS等内容直接缓存到本地,下次访问相同对象时,直接从缓存即可,无需访问后端静态服务器以及存储存储服务器,可以替代squid功能. 1 ...
- socket编码问题
server.py import socket ip_port = ('127.0.0.1',9999) sk = socket.socket() sk.bind(ip_port) sk.listen ...
- linux终端常用命令
常用的信息显示命令 命令#pwd 用于在屏幕上输出当前的工作目录. 命令#stat 用于显示指定文件的相关信息. 命令#uname -a 用于显示操作系统信息. 命令#hostname 用于显示当前本 ...
- scaffolding —— 脚手架(转)
Scaffolding — 基架 基于数据库架构生成网页模板的过程.在 ASP .NET 中,动态数据使用基架来简化基于 Web 的 UI 的生成过程.用户可以通过这种 UI 来查看和更新数据库. ...
- 【BZOJ2482】[Spoj1557] Can you answer these queries II 线段树
[BZOJ2482][Spoj1557] Can you answer these queries II Description 给定n个元素的序列. 给出m个询问:求l[i]~r[i]的最大子段和( ...
- 关于微信小程序下拉出现三个小点
包子这天看美团外卖的小程序,再瞅瞅自己的背景色,发现,美团下拉的时候有三个小点,但是我自己的校车徐下拉的时候没有三个小点,很是郁闷,于是各种的找各种的找,发现,这三个小点是微信小程序自带的,你只需要设 ...
- Storm 提交任务过程详解 (不对地方麻烦指正)
1.使用的是Storm中自带的一个测试jar包 提交下这任务到storm中去 storm jar /usr/local/app/storm/examples/storm-starter/storm-s ...
- iOS之事件的传递和响应机制
前言: 按照时间顺序,事件的生命周期是这样的: 事件的产生和传递(事件如何从父控件传递到子控件并寻找到最合适的view.寻找最合适的view的底层实现.拦截事件的处理)->找到最合适的view后 ...