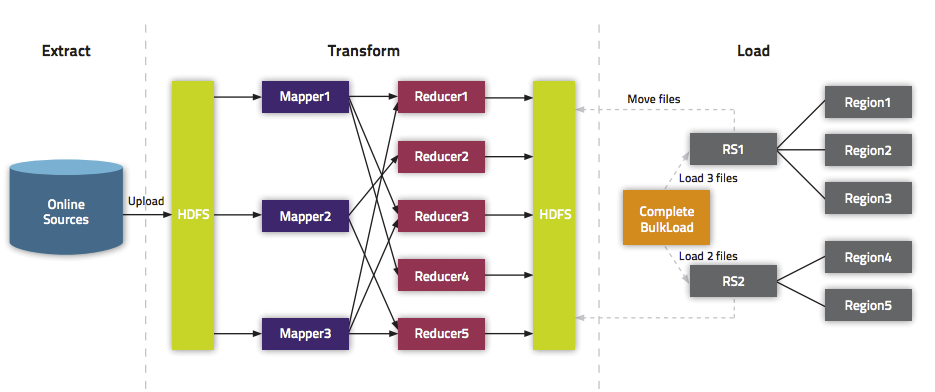
通过BulkLoad的方式快速导入海量数据
摘要


public class GenerateHFile extends Mapper<LongWritable,
Text, ImmutableBytesWritable, Put>{
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] items = line.split("\t"); String ROWKEY = items[1] + items[2] + items[3];
ImmutableBytesWritable rowkey = new ImmutableBytesWritable(ROWKEY.getBytes());
Put put = new Put(ROWKEY.getBytes()); //ROWKEY
put.addColumn("INFO".getBytes(), "URL".getBytes(), items[0].getBytes());
put.addColumn("INFO".getBytes(), "SP".getBytes(), items[1].getBytes()); //出发点
put.addColumn("INFO".getBytes(), "EP".getBytes(), items[2].getBytes()); //目的地
put.addColumn("INFO".getBytes(), "ST".getBytes(), items[3].getBytes()); //出发时间
put.addColumn("INFO".getBytes(), "PRICE".getBytes(), Bytes.toBytes(Integer.valueOf(items[4]))); //价格
put.addColumn("INFO".getBytes(), "TRAFFIC".getBytes(), items[5].getBytes());//交通方式
put.addColumn("INFO".getBytes(), "HOTEL".getBytes(), items[6].getBytes()); //酒店 context.write(rowkey, put);
}
}
public class GenerateHFileMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
final String INPUT_PATH= "hdfs://master:9000/INFO/Input";
final String OUTPUT_PATH= "hdfs://master:9000/HFILE/Output";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf("TRAVEL"));
Job job=Job.getInstance(conf);
job.getConfiguration().set("mapred.jar", "/home/hadoop/TravelProject/out/artifacts/Travel/Travel.jar"); //预先将程序打包再将jar分发到集群上
job.setJarByClass(GenerateHFileMain.class);
job.setMapperClass(GenerateHFile.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
HFileOutputFormat2.configureIncrementalLoad(job,table,connection.getRegionLocator(TableName.valueOf("TRAVEL")))
FileInputFormat.addInputPath(job,new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job,new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true)?0:1);
}
public class LoadIncrementalHFileToHBase {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
Table table = connection.getTable(TableName.valueOf("TRAVEL"));
LoadIncrementalHFiles load = new LoadIncrementalHFiles(conf);
load.doBulkLoad(new Path("hdfs://master:9000/HFILE/OutPut"), admin,table,connection.getRegionLocator(TableName.valueOf("TRAVEL")));
}
}
通过BulkLoad的方式快速导入海量数据的更多相关文章
- 通过BlukLoad的方式快速导入海量数据
http://www.cnblogs.com/MOBIN/p/5559575.html 摘要 加载数据到HBase的方式有多种,通过HBase API导入或命令行导入或使用第三方(如sqoop)来导入 ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- HBase 写优化之 BulkLoad 实现数据快速入库
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等.但是这些方式不是慢就是在导入的过程的占用Region资 ...
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式)
mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式) 首先将要导入的数据文件top5000W.txt放入到数据库数据目录/var/local/mysql/data/${d ...
- MySQL 快速导入大量数据 资料收集
一.LOAD DATA INFILE http://dev.mysql.com/doc/refman/5.5/en/load-data.html 二. 当数据量较大时,如上百万甚至上千万记录时,向My ...
- 在Ubuntu上使用离线方式快速安装K8S v1.11.1
在Ubuntu上使用离线方式快速安装K8S v1.11.1 0.安装包文件下载 https://pan.baidu.com/s/1nmC94Uh-lIl0slLFeA1-qw v1.11.1 文件大小 ...
- 8、组件注册-@Import-给容器中快速导入一个组件
8.组件注册-@Import-给容器中快速导入一个组件 8.1 给容器中注册组建的方式 包扫描+组建标注注解(@Controller.@Service.@Repository.@Component)[ ...
- Mysql百万数据量级数据快速导入Redis
前言 随着系统的运行,数据量变得越来越大,单纯的将数据存储在mysql中,已然不能满足查询要求了,此时我们引入Redis作为查询的缓存层,将业务中的热数据保存到Redis,扩展传统关系型数据库的服务能 ...
随机推荐
- FIR滤波器设计
FIR滤波器的优越性: 相位对应为严格的线性,不存在延迟失真,仅仅有固定的时间延迟: 因为不存在稳定性问题,设计相对简单: 仅仅包括实数算法,不涉及复数算法,不须要递推运算,长度为M,阶数为M-1,计 ...
- Android 使用新浪微博SSO授权
新浪微博SSO授权,很早就做好了,只是一直没有时间整理博客,今天加班,晚上闲暇之时便想到整理一下.由于整个七月份很忙,加班很多.前段时间把腾讯微博的SSO认证整理好了.想在七月份翻篇之前再写点东西.好 ...
- Python字符串格式符号含义
====== #字符串格式化符号含义 #%C 格式化字符串及其ASCLL码 >>> '%c' %97 'a' >>> '%c' % 97 'a' >>& ...
- SQL转换函数to_char/to_date/to_number
日期型->字符型转换函数to_char(d [,fmt]) 函数to_char(d [,fmt])用于将日期型数值转换为字符串(varchar2类型),其中参数d用于指定日期值,fmt用于指定要 ...
- playframework简单介绍
官方网站: https://www.playframework.com/documentation/2.5.x/Home 简介 编辑 Play!是一个full-stack(全栈的)Java Web应用 ...
- Red Hat Enterprise Linux x86-64 上安装 oracle 11gR2
一.以root用户登录 二.安装依赖包 #rpm -qa | grep 包名 ----查看包 binutils-2.20.51.0.2-5.11.el6 (x86_64) ...
- WIN8 WIN10系统如何完全获取用户管理员权限
按住WIN+R 2 计算机配置----Windows设置----安全设置----本地策略----安全选项----用户账户控制:以管理员批准模式运行所有管理员,把启用改为禁止然后重启电脑
- JS全部API笔记
我相信对于程序猿都有做笔记的习惯. 我初学到现在也做了不少笔记,以前,总是怕写的文章或者好的内容分享出来就怕被直接copy以后更个名就不再是你的. 但通过博客园,学习到不少东西,人家都不怕什么了,我自 ...
- javascript各种专业名词
刚开始学javascript经常看到各种专业名词,在此整理一下个人的学习笔记: 直接量 直接量——就是程序中直接使用的数据值,如:88 //数字(String)"hello world ...
- VNC配置连接远程服务器桌面-linux\windows
一.VNC配置连接远程服务器桌面 1.服务器安装VNC-server # yum -y install vnc-server 2.配置VNC连接登陆密码 # vncpasswd 回车 3.配置VNC- ...