拒绝低效!Python教你爬虫公众号文章和链接
本文首发于公众号「Python知识圈」,如需转载,请在公众号联系作者授权。
前言
上一篇文章整理了的公众号所有文章的导航链接,其实如果手动整理起来的话,是一件很费力的事情,因为公众号里添加文章的时候只能一篇篇的选择,是个单选框。
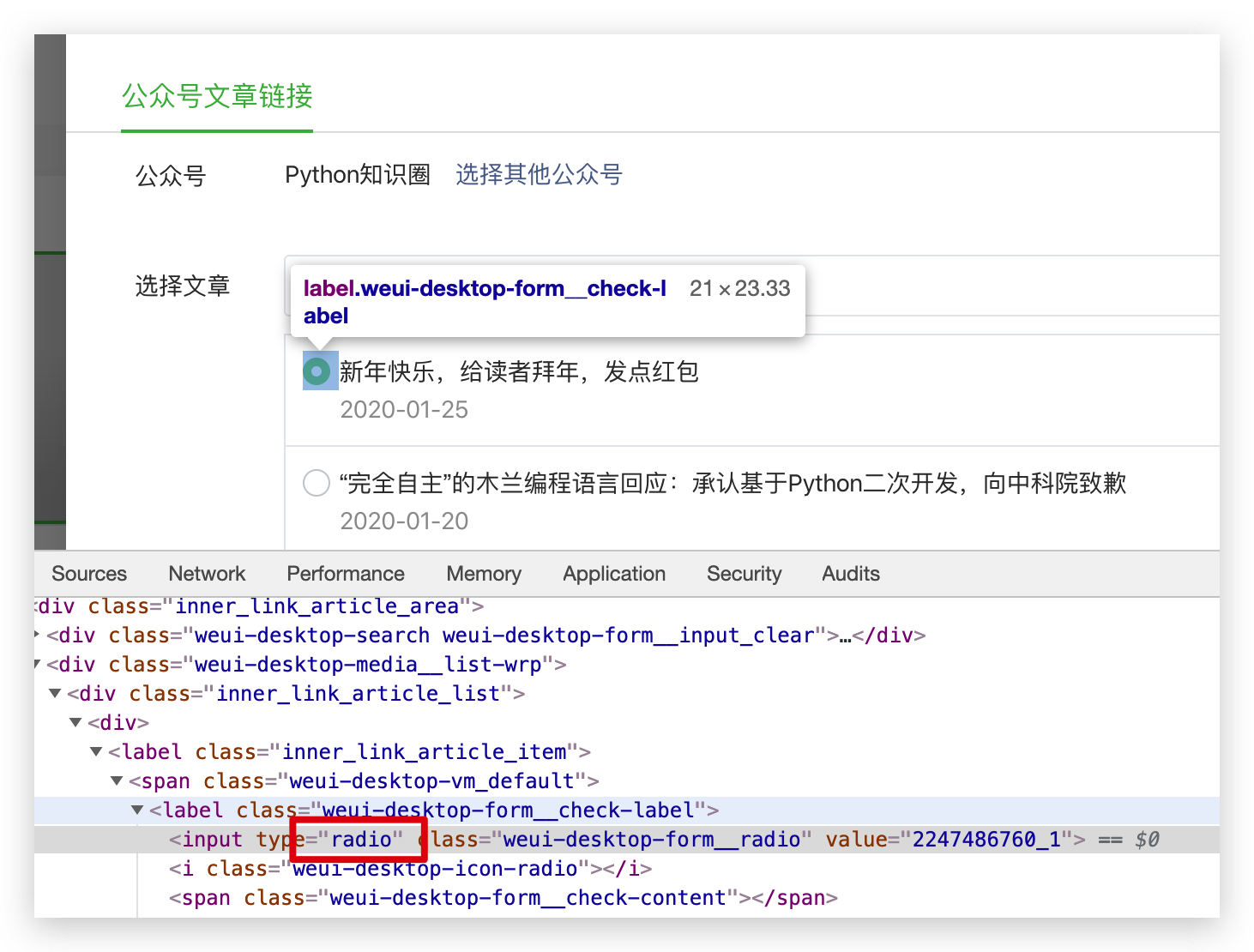
面对几百篇的文章,这样一个个选择的话,是一件苦差事。
pk哥作为一个 Pythoner,当然不能这么低效,我们用爬虫把文章的标题和链接等信息提取出来。
抓包
我们需要通过抓包提取公众号文章的请求的 URL,参考之前写过的一篇抓包的文章 Python爬虫APP前的准备,pk哥这次直接抓取 PC 端微信的公众号文章列表信息,更简单。
我以抓包工具 Charles 为例,勾选容许抓取电脑的请求,一般是默认就勾选的。
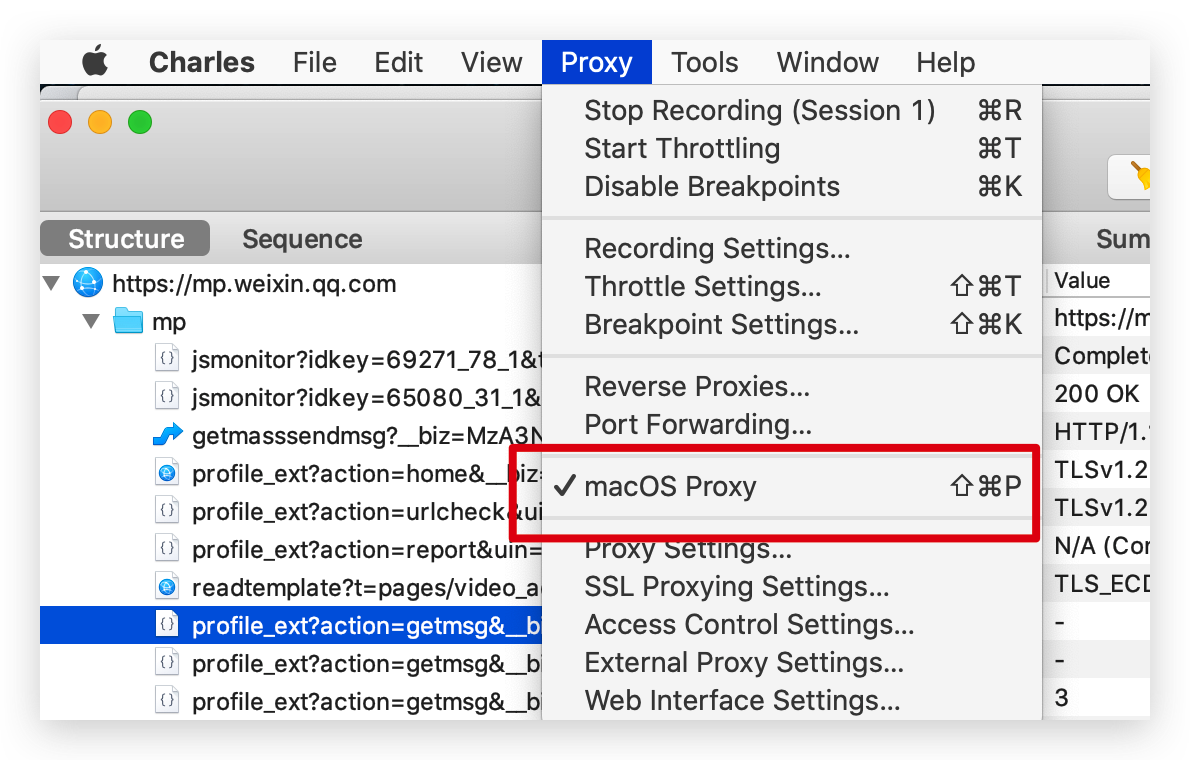
为了过滤掉其他无关请求,我们在左下方设置下我们要抓取的域名。
打开 PC 端微信,打开 「Python知识圈」公众号文章列表后,Charles 就会抓取到大量的请求,找到我们需要的请求,返回的 JSON 信息里包含了文章的标题、摘要、链接等信息,都在 comm_msg_info 下面。
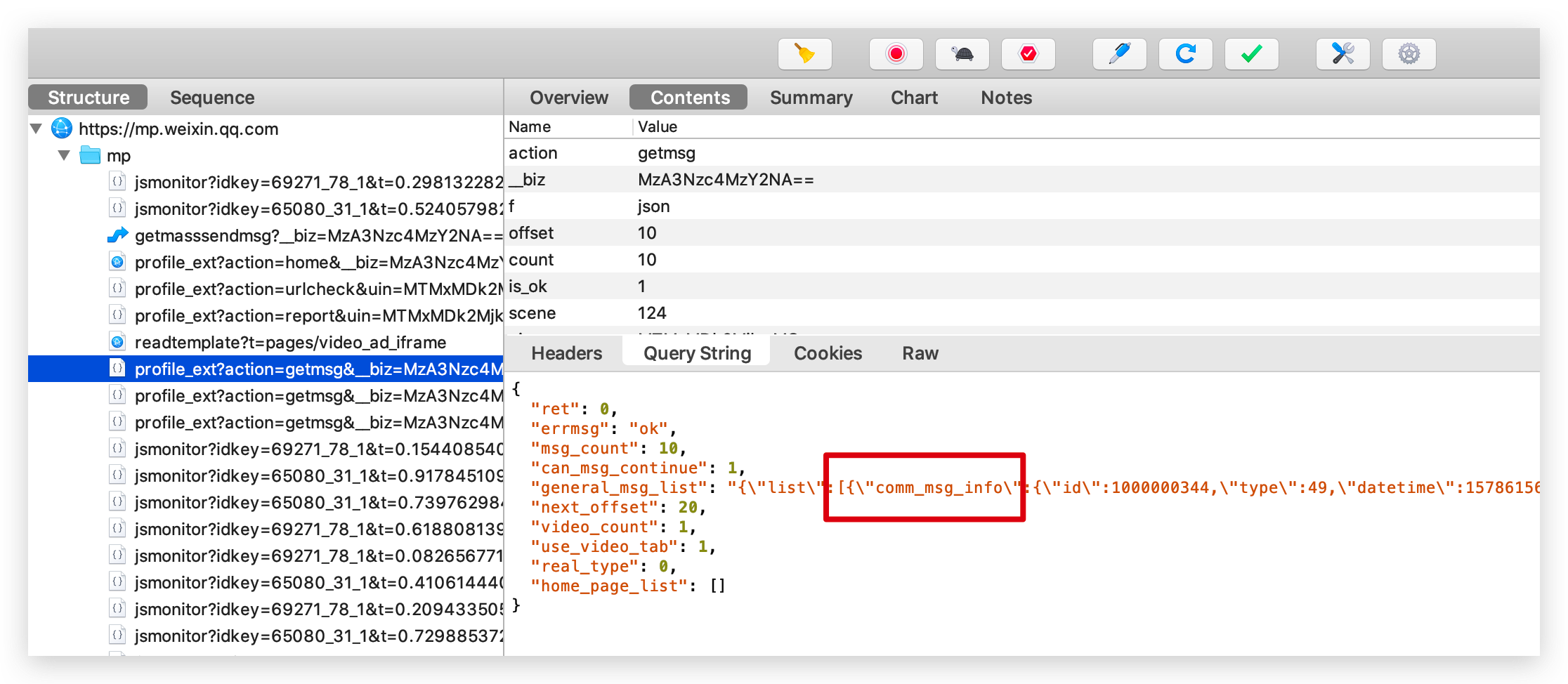

这些都是请求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
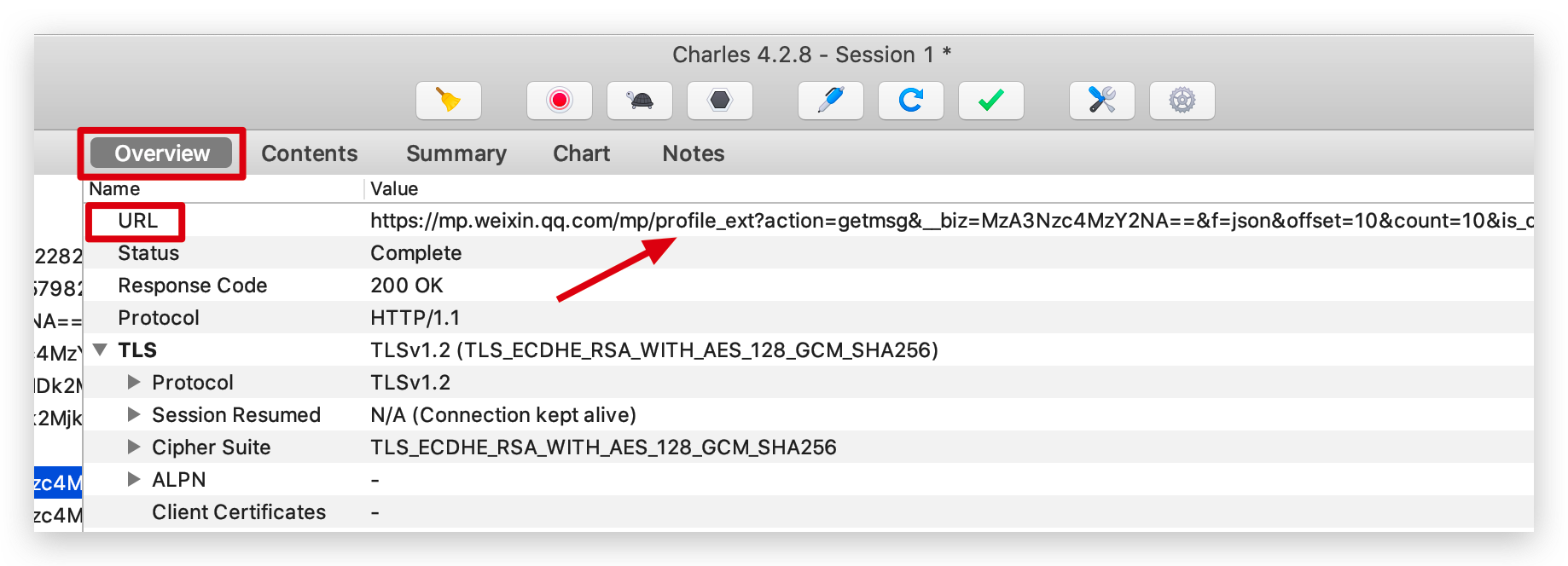
通过抓包获取了这么多信息后,我们可以写爬虫爬取所有文章的信息并保存了。
初始化函数
公众号历史文章列表向上滑动,加载更多文章后发现链接中变化的只有 offset 这个参数,我们创建一个初始化函数,加入代理 IP,请求头和信息,请求头包含了 User-Agent、Cookie、Referer。
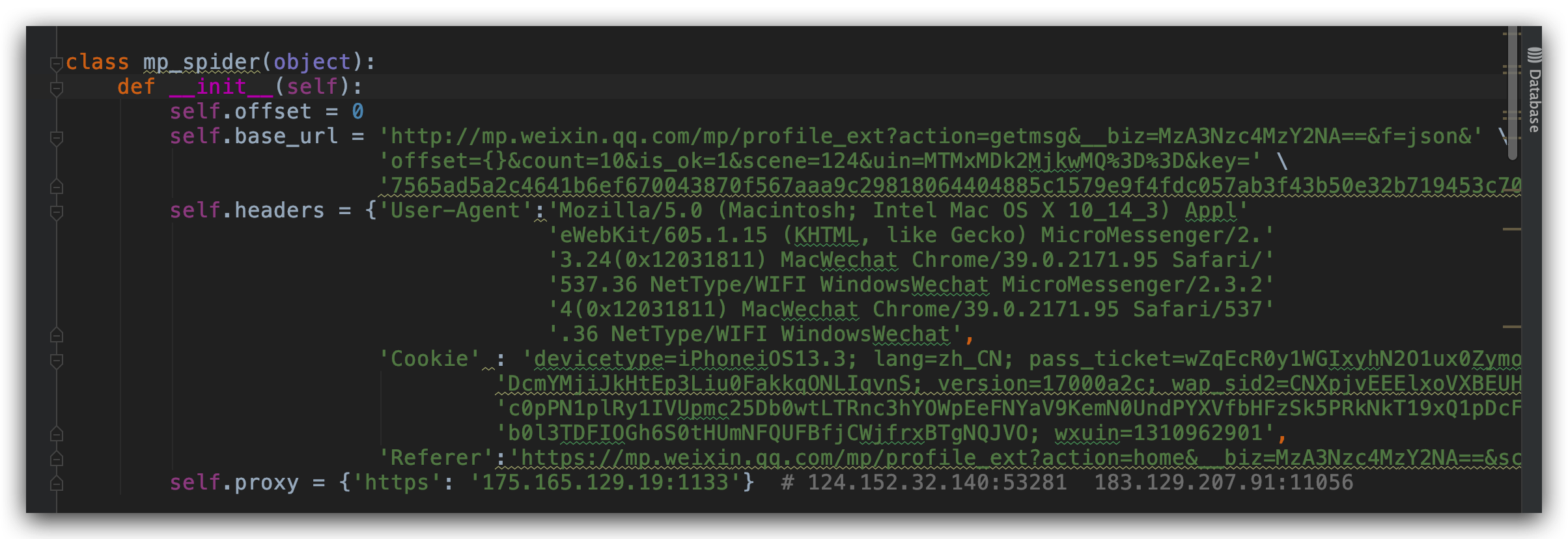
这些信息都在抓包工具可以看到。
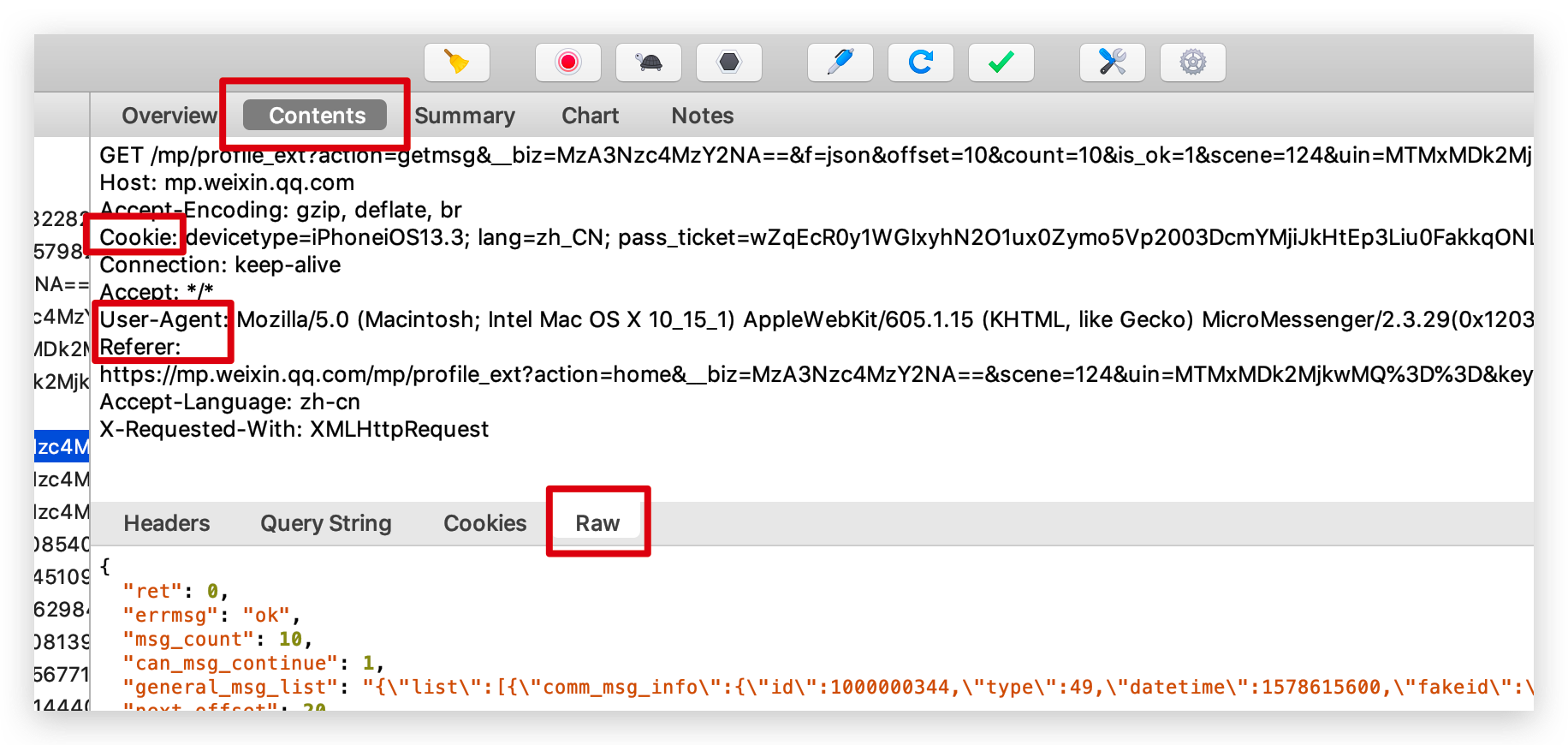
请求数据
通过抓包分析出来了请求链接,我们就可以用 requests 库来请求了,用返回码是否为 200 做一个判断,200 的话说明返回信息正常,我们再构建一个函数 parse_data() 来解析提取我们需要的返回信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过分析返回的 Json 数据,我们可以看到,我们需要的数据都在 app_msg_ext_info 下面。
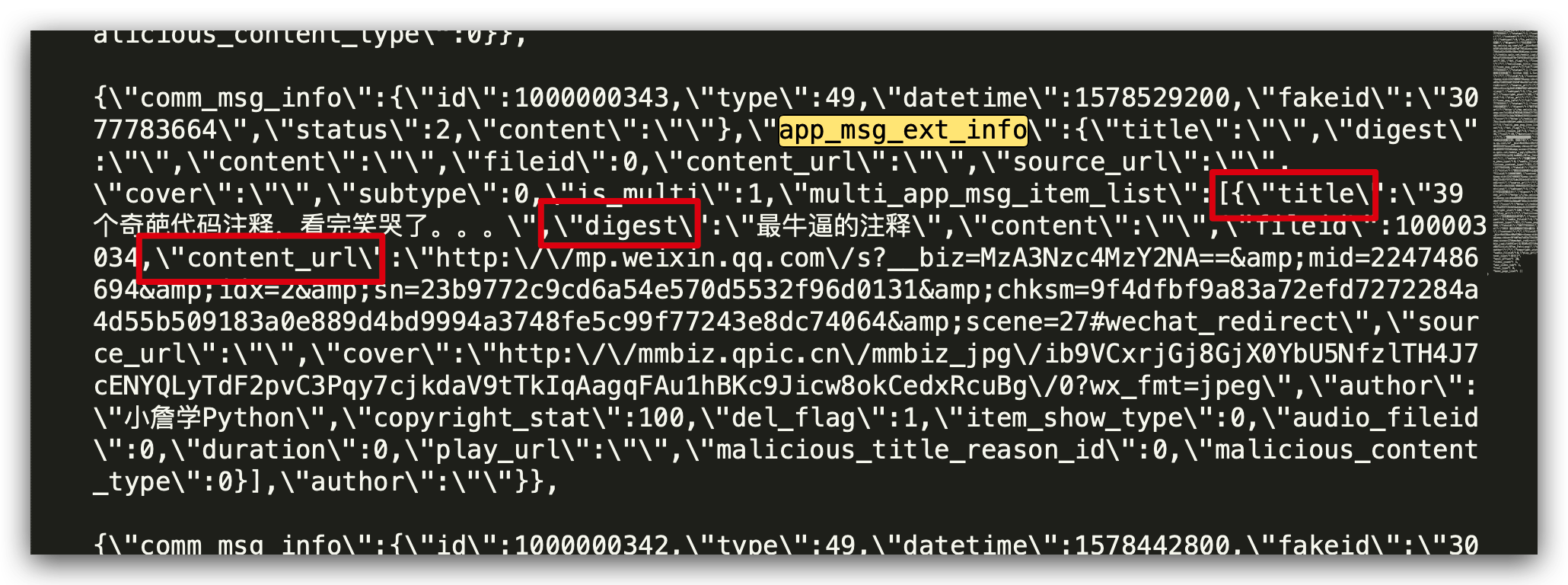
我们用 json.loads 解析返回的 Json 信息,把我们需要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['标题'] = title
info['小标题'] = title_child
info['文章链接'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在写入文件')
with open('Python公众号文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['标题', '小标题', '文章链接'] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("写入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取数据完毕!')
这样,爬取的结果就会以 csv 格式保存起来。
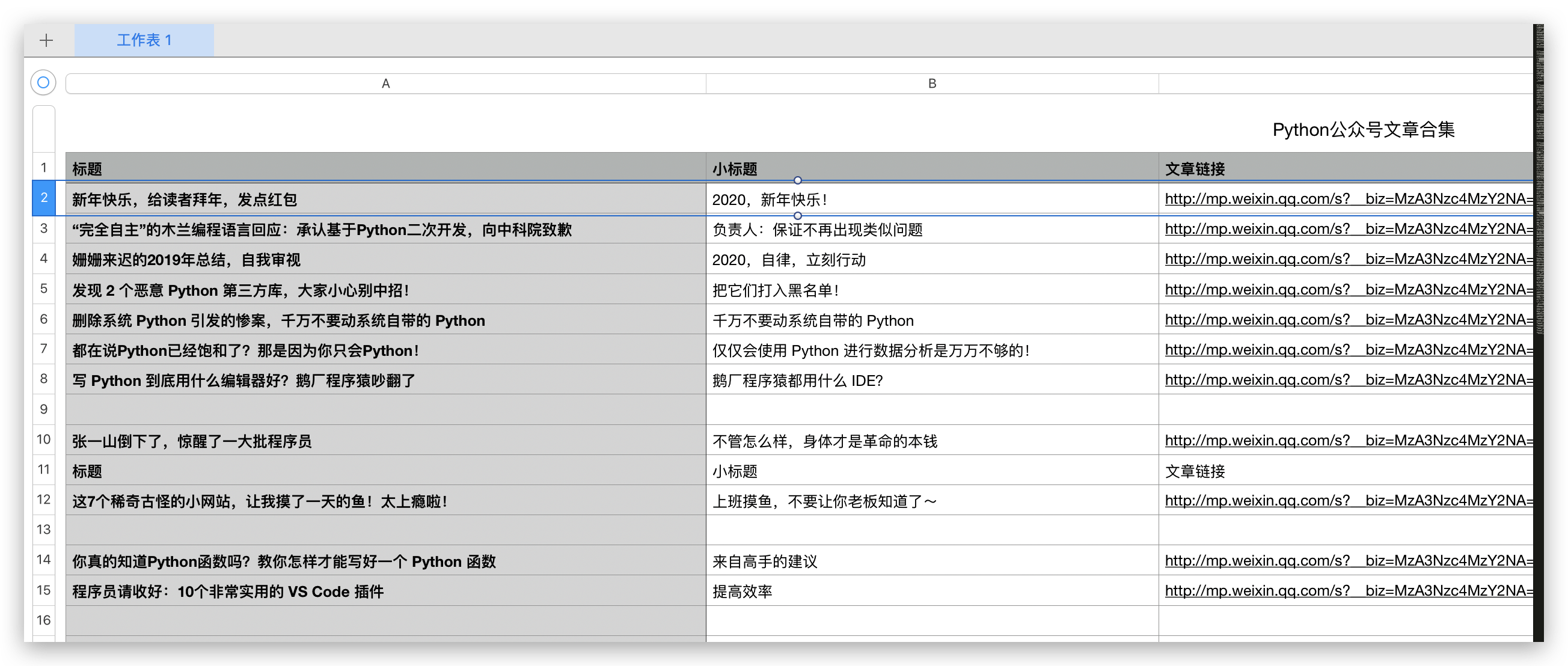
运行代码时,可能会遇到 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
经常写文章的人应该都知道,一般写文字都会用 Markdown 的格式来写文章,这样的话,不管放在哪个平台,文章的格式都不会变化。
在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)
爬取完成后,效果如下。
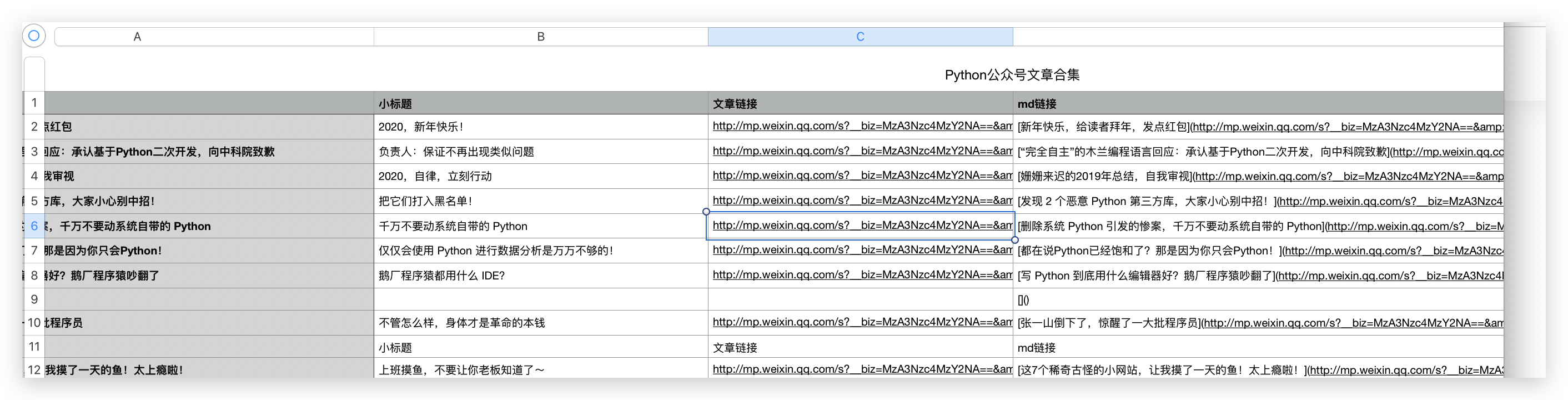
我们把 md链接这一列全部粘贴到 Markdown 格式的笔记里就行了,大部分的笔记软件都知道新建 Markdown 格式的文件的。
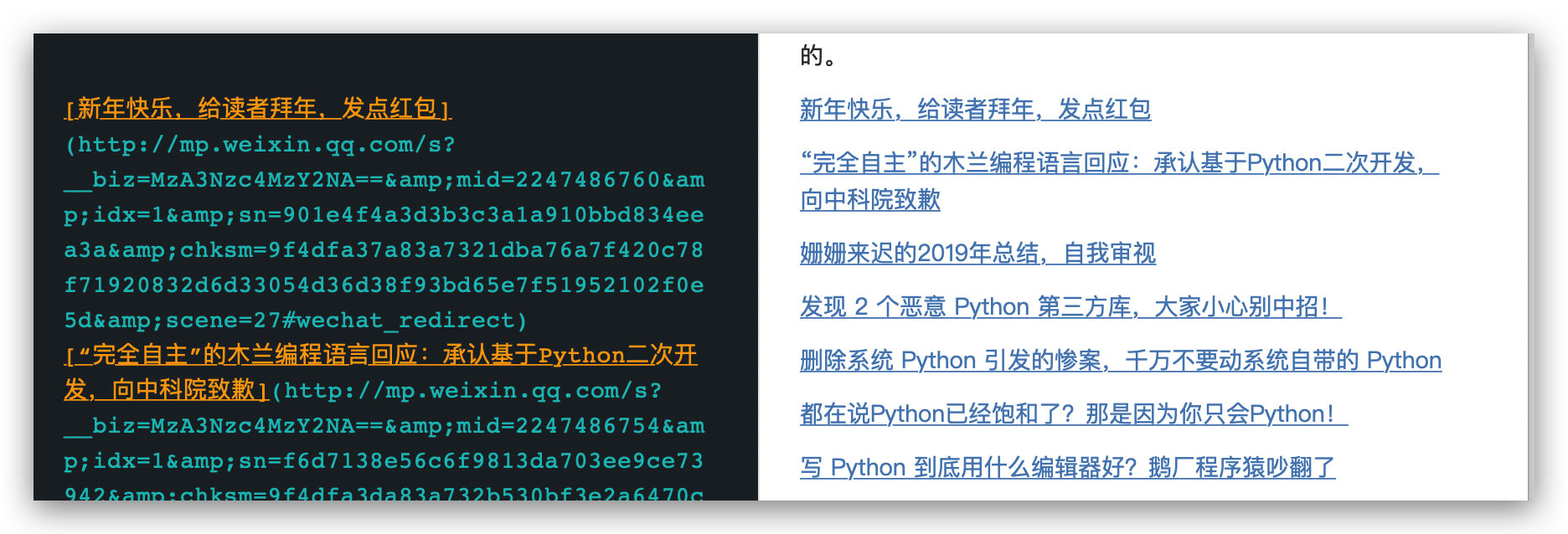
这样,这些导航文章链接整理起来就是分类的事情了。
你用 Python 解决过生活中的小问题吗?欢迎留言讨论。
拒绝低效!Python教你爬虫公众号文章和链接的更多相关文章
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 50行Python代码,教你获取公众号全部文章
> 本文首发自公众号:python3xxx 爬取公众号的方式常见的有两种 - 通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章 - 通过微信公众号的素材管理,获取公众号文章.缺点是需要申请自 ...
- python爬取微信公众号
爬取策略 1.需要安装python selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法.来达到登录的效果 pip3 install selenium c ...
- Python 微信公众号文章爬取
一.思路 我们通过网页版的微信公众平台的图文消息中的超链接获取到我们需要的接口 从接口中我们可以得到对应的微信公众号和对应的所有微信公众号文章. 二.接口分析 获取微信公众号的接口: https:// ...
- Markdown 直接转换公众号文章,不再为排版花时间
上一篇「又一家数据公司被查,爬虫到底做错了什么?」反响强烈,虽然我这是新号,但还是获得了不少公众号的转发,借机也结识了很多业内大佬,在此感谢大家的抬爱! 同时也有不少号主问我的文章排版是用的哪个网站, ...
- 破解微信防盗链&微信公众号文章爬取方案
破解微信图文防盗链:https://www.cnblogs.com/xsxshmily/p/8000043.html 图片解除防盗链:https://blog.csdn.net/show_ljw/ar ...
- Chrome浏览器保存微信公众号文章中的图片
用chrome浏览器打开微信公众号文章中时,另存为图片时保存的是640.webp,不是图片本身,用IE则没有此问题.大部分chrome插件也无法保存图片. 经过多番尝试,找到一款插件可以批量保存微信公 ...
- pc端引入微信公众号文章
最近做了一个小需求,结果坑特别多..... 需求是这样的,要给公司内部做一个微信公众号广告投票系统,整个项目就不多赘述了,有个小功能,要求是这样的: 点击某条记录后的“投票”按钮,在当前页面弹出弹窗显 ...
- 你所不知道的 Kindle - 阅读微信公众号文章
Kindle 是一款非常优秀的阅读设备,它为我们提供了非常舒服的阅读体验,并且配合强大的亚马逊图书资源,应该是目前最好的阅读设备之一.Kindle 在已有的成就下还一直在努力提升用户体验.为中国用户开 ...
随机推荐
- BuilderPattern(建造者模式)-----Java/.Net
建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式
- 二、webdriver API
目录 1. webdriver中常用属性 2. 浏览器页面操作 3. 鼠标操作 4. 键盘操作 5. 下拉框操作 1. webdriver中常用属性 import time from selenium ...
- Shiro权限管理框架(五):自定义Filter实现及其问题排查记录
明确需求 在使用Shiro的时候,鉴权失败一般都是返回一个错误页或者登录页给前端,特别是后台系统,这种模式用的特别多.但是现在的项目越来越多的趋向于使用前后端分离的方式开发,这时候就需要响应Json数 ...
- 1209. Construct the Rectangle
1209. Construct the Rectangle class Solution { public: /** * @param area: web page’s area * @retur ...
- ACM北大暑期课培训第八天
今天学了有流量下界的网络最大流,最小费用最大流,计算几何. 有流量下界的网络最大流 如果流网络中每条边e对应两个数字B(e)和C(e), 分别表示该边上的流量至少要是B(e),最多 C(e),那么,在 ...
- 更加清晰的TFRecord格式数据生成及读取
TFRecords 格式数据文件处理流程 TFRecords 文件包含了 tf.train.Example 协议缓冲区(protocol buffer),协议缓冲区包含了特征 Features.Ten ...
- Java8 通关攻略
点赞+收藏 就学会系列,文章收录在 GitHub JavaEgg ,N线互联网开发必备技能兵器谱 Java8早在2014年3月就发布了,还不得全面了解下 本文是用我拙劣的英文和不要脸的这抄抄那抄抄,熬 ...
- java架构之路(多线程)AQS之ReetrantLock显示锁的使用和底层源码解读
说完了我们的synchronized,这次我们来说说我们的显示锁ReetrantLock. 上期回顾: 上次博客我们主要说了锁的分类,synchronized的使用,和synchronized隐式锁的 ...
- Spirng Boot2 系列教程(二十二)| 启动原理
一个读者,也是我的好朋友投稿的一篇关于 SpringBoot 启动原理的文章,才大二就如此优秀,未来可期. 我一直想了解一下 SpirngBoot 的是如何启动的,我想就来写一篇关于 SpirngBo ...
- Tarjan强连通分量模板
最好还是看一看下面这个网址吧 我的这篇博客里的代码更加缜密(毫无错误的神级代码)https://www.cnblogs.com/Tidoblogs/p/11315153.html https://ww ...