唱吧基于 MaxCompute 的大数据之路
使用 MaxCompute之前,唱吧使用自建体系来存储处理各端收集来的日志数据,包括请求访问记录、埋点数据、服务器业务数据等。初期这套基于开源组件的体系有力支撑了数据统计、业务报表、风控等业务需求。但随着每天处理数据量的增长,积累的历史数据越来越多,来自其他部门同事的需求越来越复杂,自建体系逐渐暴露出了能力上的短板。同时期,唱吧开始尝试阿里云提供的ECS、OSS等云服务,大数据部门也开始使用 MaxCompute来弥补自建体系的不足。
在内部ELK实现的基础上,从自建机房向MaxCompute进行数据同步工作是比较简单的,实践中我们主要采取两种方式:一是利用阿里云提供的datahub组件,直接对接logstash;二是把待同步数据落地到文件,然后使用tunnel命令行工具上传至MaxCompute的对应表中。
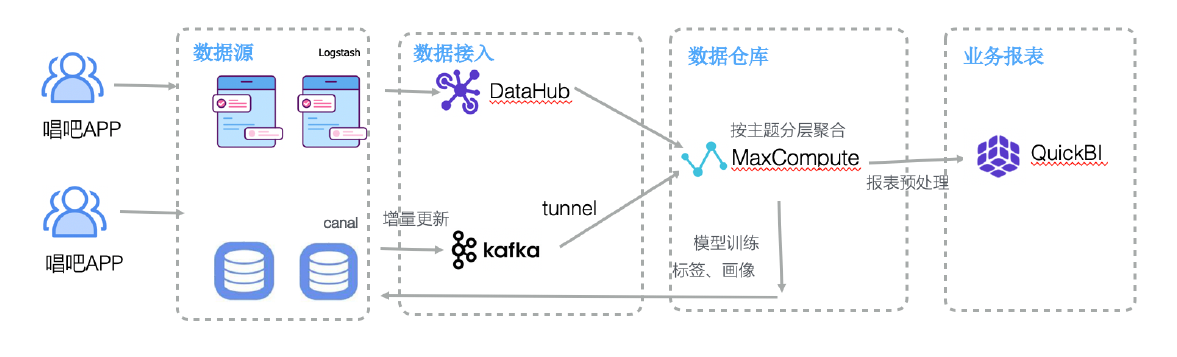
数据进入MaxCompute后,我们按照数据的主题和使用场景构造了三层结构:原始数据层ODS、中间数据层MDS、报表数据层DM。ODS层中保存直接同步的数据,在此基础上加工整理到的原始表,例如增量同步的原mysql表,经过风控清洗的访问日志表等。MDS层存放原始层数据聚合、抽象加工过的结果,这一层的数据表更可读、读取计算时更经济,一般情况下要求其他部门的同事使用这一层的数据。DM层是处理理的最终结果,支持QuickBI直接读取进行报表展示,同时也支持同步回自建机房,供其他业务使用。
目前除了某些对实时要求比较高的场景还使用自建体系外,MaxCompute承担了唱吧全部的离线计算工作。每天有近千个任务定时运行,处理TB级别的数据,生成上百个数据报表在QuickBI进行展示。可视化的管理理界面和基于SQL的计算方式大大降低了使用门槛,提升了效率。除此之外,推荐和风控业务也都利用了MaxCompute的计算能力,实现了对需求的快速跟进和迭代。MaxCompute云服务和自建体系的结合,让我们能充分满足业务需求,在效率成本和灵活性上取得了很好的平衡。
下一步,对于MaxCompute我们有几个方向上的计划:
一是利用机器学习能力,进一步挖掘数据的价值。
二是对那些历史比较久的冷数据,利用MaxCompute的外表功能,定期转移至OSS等服务中,保证可读的基础上降低成本。
三是评估阿里云的实时计算服务,作为自建体系的补充。
本文作者:马星显 (唱吧大数据负责人)
本文为云栖社区原创内容,未经允许不得转载。
唱吧基于 MaxCompute 的大数据之路的更多相关文章
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 高速基于echarts的大数据可视化
[Author]: kwu 高速基于echarts的大数据可视化,echarts纯粹的js实现的图表工具.高速开发的过程例如以下: 1.引入echarts的依赖js库 <script type= ...
- 软工之词频统计器及基于sketch在大数据下的词频统计设计
目录 摘要 算法关键 红黑树 稳定排序 代码框架 .h文件: .cpp文件 频率统计器的实现 接口设计与实现 接口设计 核心功能词频统计器流程 效果 单元测试 性能分析 性能分析图 问题发现 解决方案 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- 胖子哥的大数据之路(10)- 基于Hive构建数据仓库实例
一.引言 基于Hive+Hadoop模式构建数据仓库,是大数据时代的一个不错的选择,本文以郑商所每日交易行情数据为案例,探讨数据Hive数据导入的操作实例. 二.源数据-每日行情数据 三.建表脚本 C ...
随机推荐
- Programming | 变量名的力量
命名准则 变量名要完全,准确的描述变量所代表的事物,一般而言,对变量的描述就是最佳的变量名.避免x,temp,i等泛泛而谈的变量名. 比如对于矩阵的循环,matrix[row][col]就比m[i][ ...
- linux普通用户无法登录mysql
一.前言 本帖方法只适用于普通用户无法登录,但root用户可以登录的情况. 今天将war包放入linux后,运行报错,经过检查发现是数据库连接不上.奇怪的是,用户名和密码都是正确的,所以有了以下发现. ...
- FingerPrint Fuzzy Vault Matlab实践
本文实践了指纹识别生物特征识别研究论文A Fuzzy Vault Scheme的算法部分.原文请查看以下链接: Juels, A. & Sudan, M. Des Codes Crypt (2 ...
- ArrayBlockingQueue 和LinkedBlockQueue
ArrayBlockingQueue ArrayBlockingQueue是Java多线程常用的线程安全的一个集合,基于数组实现,继承自AbstractQueue,实现了BlockingQueue和S ...
- 廖雪峰Java11多线程编程-3高级concurrent包-5Atomic
Atomic java.util.concurrent.atomic提供了一组原子类型操作: 如AtomicInteger提供了 int addAndGet(int delta) int increm ...
- javascript 数组的方法(一)
栈方法(后进先出) ArrayObj.push():就是向数组末尾添加新的元素,返回的是数组新的长度. ArrayObj.pop():就是向数组中删除数组最后一个元素并且返回该元素.如果数组为空就返回 ...
- Java-MyBatis-MyBatis3-XML映射文件:insert, update 和 delete
ylbtech-Java-MyBatis-MyBatis3-XML映射文件:insert, update 和 delete 1.返回顶部 1. insert, update 和 delete 数据变更 ...
- Python使用微信接入图灵机器人
1.wxpy库介绍 wxpy 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展. 文档地址:https://wxpy.readthedocs.io 从 PYPI 官 ...
- ArrayBlockingQueue的使用案例:
ArrayBlockingQueue的介绍: ArrayBlockingQueue,顾名思义:基于数组的阻塞队列.数组是要指定长度的,所以使用ArrayBlockingQueue时必须指定长度,也就是 ...
- Sql Server 2005主机和镜像切换SQL语句
--1.主备互换 --主机执行: USE master; ALTER DATABASE <DatabaseName> SET PARTNER FAILOVER; --2.主服务器Down掉 ...