Webdriver配合Tesseract-OCR 自动识别简单的验证码
验证码: 如下,在进行自动化测试,遇到验证码的问题,一般有两种方式
1.找开发去掉验证码或者使用万能验证码
2.使用OCR自动识别
使用OCR自动化识别,一般识别率不是太高,处理一般简单验证码还是没问题
这里使用的是Tesseract-OCR,下载地址:https://github.com/A9T9/Free-Ocr-Windows-Desktop/releases
怎么使用呢?
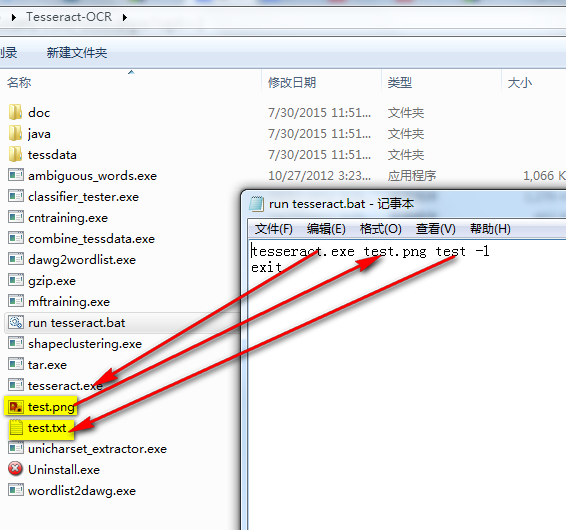
进入安装后的目录:
tesseract.exe test.png test -1
准备一份网页,上面使用该验证码
<html>
<head>
<title>Table test by Young</title>
</head>
<body>
</br>
<h1> Test </h1>
<img src="http://csujwc.its.csu.edu.cn/sys/ValidateCode.aspx?t=1">
</br>
</body>
</html>
要识别验证码,首先得取得验证码,这两款采取对 页面元素部分截图的方式,首先获取整个页面的截图
然后找到页面元素坐标进行截取
/**
* This method for screen shot element
*
* @param driver
* @param element
* @param path
* @throws InterruptedException
*/
public static void screenShotForElement(WebDriver driver,
WebElement element, String path) throws InterruptedException {
File scrFile = ((TakesScreenshot) driver)
.getScreenshotAs(OutputType.FILE);
try {
Point p = element.getLocation();
int width = element.getSize().getWidth();
int height = element.getSize().getHeight();
Rectangle rect = new Rectangle(width, height);
BufferedImage img = ImageIO.read(scrFile);
BufferedImage dest = img.getSubimage(p.getX(), p.getY(),
rect.width, rect.height);
ImageIO.write(dest, "png", scrFile);
Thread.sleep(1000);
FileUtils.copyFile(scrFile, new File(path));
} catch (IOException e) {
e.printStackTrace();
}
}
截取完元素,就可以调用Tesseract-OCR生成text
// use Tesseract to get strings
Runtime rt = Runtime.getRuntime();
rt.exec("cmd.exe /C tesseract.exe D:\\Tesseract-OCR\\test.png D:\\Tesseract-OCR\\test -1 ");
接下来通过java读取txt
/**
* This method for read TXT file
*
* @param filePath
*/
public static void readTextFile(String filePath) {
try {
String encoding = "GBK";
File file = new File(filePath);
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
System.out.println(lineTxt);
}
read.close();
} else {
System.out.println("找不到指定的文件");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
}
}
整体代码如下:
package com.dbyl.tests; import java.awt.Rectangle;
import java.awt.image.BufferedImage;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.Reader;
import java.util.concurrent.TimeUnit; import javax.imageio.ImageIO; import org.apache.commons.io.FileUtils;
import org.openqa.selenium.By;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.Point;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement; import com.dbyl.libarary.utils.DriverFactory; public class TesseractTest { public static void main(String[] args) throws IOException,
InterruptedException { WebDriver driver = DriverFactory.getChromeDriver();
driver.get("file:///C:/Users/validation.html");
driver.manage().timeouts().pageLoadTimeout(30, TimeUnit.SECONDS);
WebElement element = driver.findElement(By.xpath("//img")); // take screen shot for element
screenShotForElement(driver, element, "D:\\Tesseract-OCR\\test.png"); driver.quit(); // use Tesseract to get strings
Runtime rt = Runtime.getRuntime();
rt.exec("cmd.exe /C tesseract.exe D:\\Tesseract-OCR\\test.png D:\\Tesseract-OCR\\test -1 "); Thread.sleep(1000);
// Read text
readTextFile("D:\\Tesseract-OCR\\test.txt");
} /**
* This method for read TXT file
*
* @param filePath
*/
public static void readTextFile(String filePath) {
try {
String encoding = "GBK";
File file = new File(filePath);
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
System.out.println(lineTxt);
}
read.close();
} else {
System.out.println("找不到指定的文件");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
}
} /**
* This method for screen shot element
*
* @param driver
* @param element
* @param path
* @throws InterruptedException
*/
public static void screenShotForElement(WebDriver driver,
WebElement element, String path) throws InterruptedException {
File scrFile = ((TakesScreenshot) driver)
.getScreenshotAs(OutputType.FILE);
try {
Point p = element.getLocation();
int width = element.getSize().getWidth();
int height = element.getSize().getHeight();
Rectangle rect = new Rectangle(width, height);
BufferedImage img = ImageIO.read(scrFile);
BufferedImage dest = img.getSubimage(p.getX(), p.getY(),
rect.width, rect.height);
ImageIO.write(dest, "png", scrFile);
Thread.sleep(1000);
FileUtils.copyFile(scrFile, new File(path));
} catch (IOException e) {
e.printStackTrace();
}
} }
Webdriver配合Tesseract-OCR 自动识别简单的验证码的更多相关文章
- Python+Selenium+PIL+Tesseract真正自动识别验证码进行一键登录
Python 2.7 IDE Pycharm 5.0.3 Selenium:Selenium的介绍及使用,强烈推荐@ Eastmount的博客 PIL : Pillow-3.3.0-cp27-cp27 ...
- Tesseract OCR简单实用介绍
做字符识别,不能不了解google的Tesseract-OCR,但是如何在自己的工程中使用其API倒是语焉不详,官网上倒是很详尽地也很啰嗦地介绍如何重新编译生成适合自己平台的lib和dll,经过近些天 ...
- selenium使用笔记(二)——Tesseract OCR
在自动化测试过程中我们经常会遇到需要输入验证码的情况,而现在一般以图片验证码居多.通常我们处理这种情况应该用最简单的方式,让开发给个万能验证码或者直接将验证码这个环节跳过.之前在技术交流群里也跟朋友讨 ...
- python 简单图像识别--验证码
python 简单图像识别--验证码 记录下,准备工作安装过程很是麻烦. 首先库:pytesseract,image,tesseract,PIL windows安装PIL,直接exe进行安装更方便( ...
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- python简单处理验证码,三分钟,不能再多了
序言 大家好鸭, 又是我小熊猫啦 我们在做采集数据的时候,过快或者访问频繁,或者一访问就给弹出验证码,然后就蚌珠了~今天就给大家来一个简单处理验证码的方法 环境模块 Python和pycharm如果还 ...
随机推荐
- 【CSS】css自定义字体
源:http://www.cnblogs.com/lhb25/archive/2011/02/11/1951035.html 1.@font-face 定义一个字体 2.例子
- 软件工程(FZU2015)赛季得分榜,第八回合
目录 第一回合 第二回合 第三回合 第四回合 第五回合 第6回合 第7回合 第8回合 第9回合 第10回合 第11回合 积分规则 积分制: 作业为10分制,练习为3分制:alpha30分: 团队项目分 ...
- 传说中的inside番——“黄金圣衣”篇
10月21日,在今天的课堂上拿到了我们软工实践课程的战斗圣衣,传说穿上它就能够在编码意志上+100,有着爆种.不死不休战斗等传奇属性——build to win.当然,这是我的追求与梦想.现在的我,还 ...
- MongoDB学习笔记一
操作系统:Windows7 1.下载MongoDB 2.6.5服务端,并安装 网址:http://pan.baidu.com/s/1dDfoJAh 说明:网上很多都不需要安装的,这个需要安装. 2.添 ...
- MySQL架构优化实战系列1:数据类型与索引调优全解析
一.数据类型优化 数据类型 整数 数字类型:整数和实数 tinyint(8).smallint(16).mediuint(24).int(32).bigint(64) 数字表示对应最大存储位数,如 ...
- centos虚拟机网络桥接配置
1.虚拟机设置->网络适配器->选择桥接模式->重启虚拟机 2.使用命令进行配置IP地址 (引用别人的配置命令) 修改/etc/sysconfig/network-scripts 目 ...
- Don’t Use Accessor Methods in Initializer Methods and dealloc 【初始化和dealloc方法中不要调用属性的存取方法,而要直接调用 _实例变量】
1.问题: 在dealloc方法中使用[self.xxx release]和[xxx release]的区别? 用Xcode的Analyze分析我的Project,会列出一堆如下的提示:Inco ...
- PHPExcel读取excel文件
<?php set_time_limit(0); $dir = dirname(__FILE__);//当前脚本所在路径 require $dir."/PHPExcel_1.8.0/C ...
- zTree简单实现
用zTree简单实现从后台传数据生成树 1.在jsp上引入js,jsp的head完整的部分 <%@ page language="java" contentType=&quo ...
- hosts manager——hosts配置管理工具
引言 做web开发相关的经常会用到hosts修改的功能,各个平台好像都有hosts 配置GUI(据我所知windows有.MAC OX也有),但是命令行配置hosts的好像还没有,命令行配置的话有几个 ...