爬虫初体验:Python+Requests+BeautifulSoup抓取广播剧

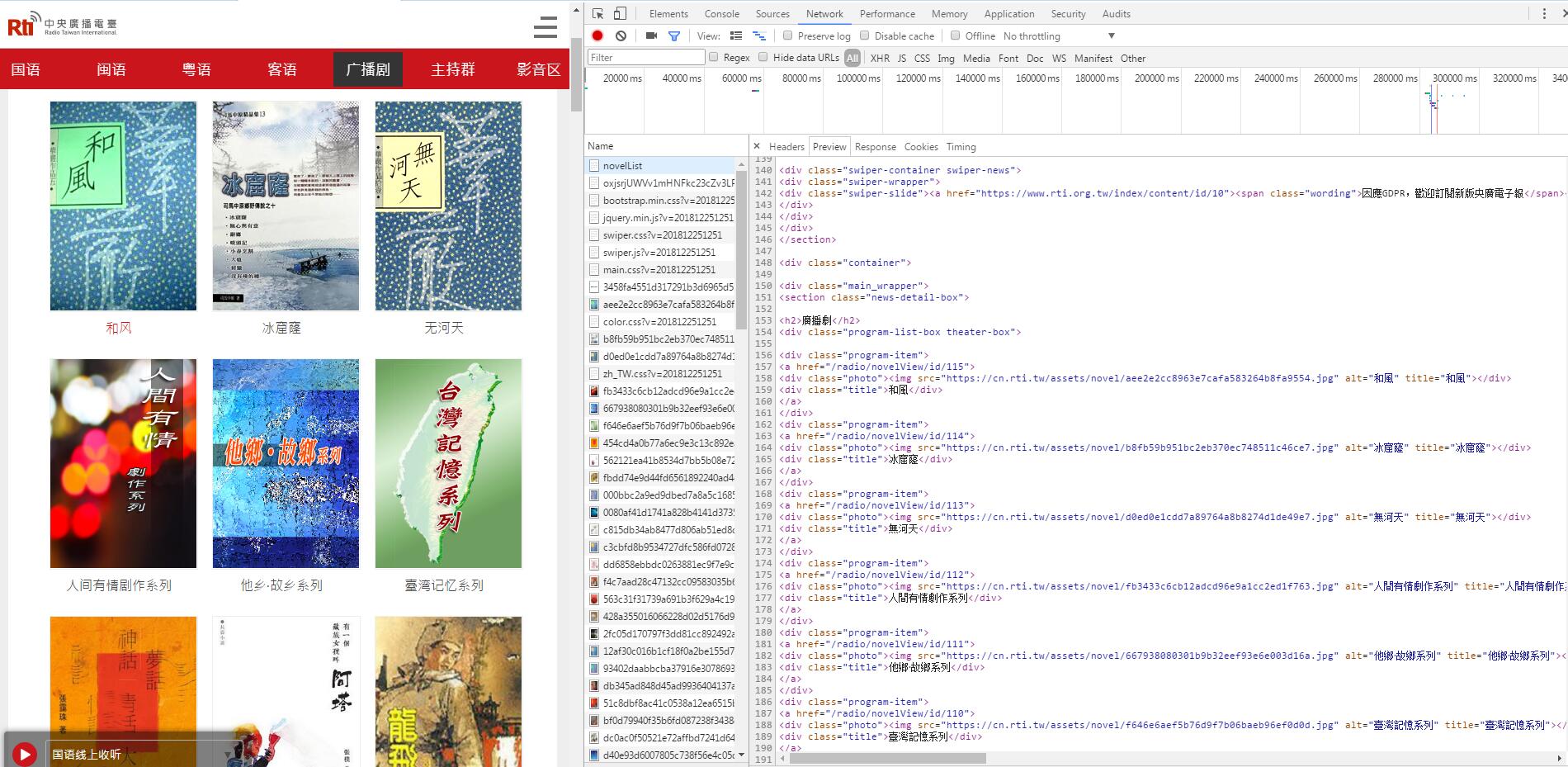
可以看到一个DIV下放一个广播剧的信息,包括名称和地址,第一步我们先收集所有广播剧的收听地址:
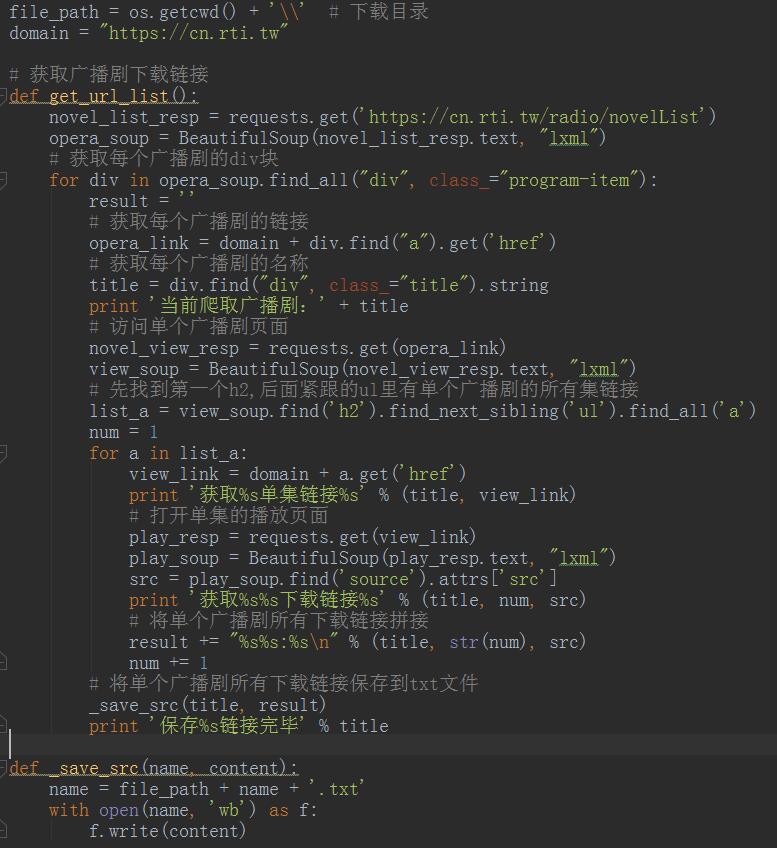
# 用requests的get方法访问
novel_list_resp = requests.get("这里放URL的地址")
# 利用上一步访问返回的结果生成一个BeautifulSoup对象
opera_soup = BeautifulSoup(novel_list_resp.text, "lxml")
# 获取所有class="program-item"的div
opera_soup.find_all("div", class_="program-item")
接着我们遍历这些div,获取每个广播剧的链接和名称:
# 找到div中的a标签,获取每个广播剧的链接
opera_link = domain + div.find("a").get('href')
# 获取每个广播剧的名称
title = div.find("div", class_="title").string
我们点击一个广播剧进去,在HTML中可以看到在ul中,每个li里都有一集的播放链接,并且是按顺序的。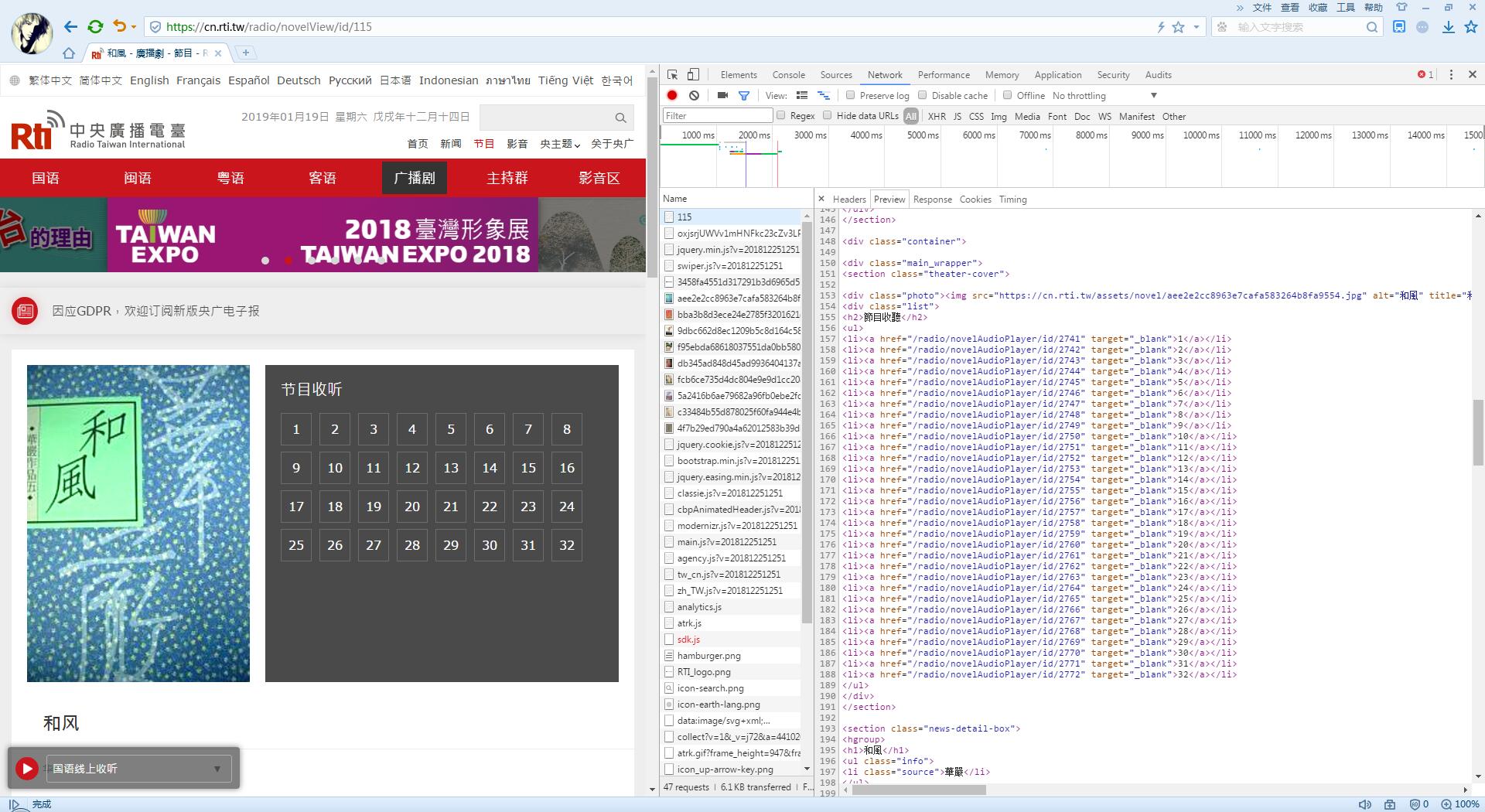
代码中我们继续用之前的方法访问单个广播剧地址,来获取剧集的list:
# 访问单个广播剧页面
novel_view_resp = requests.get(opera_link)
# 利用上一步访问返回的结果生成一个BeautifulSoup对象
view_soup = BeautifulSoup(novel_view_resp.text, "lxml")
# 首先定位h2标签,然后获取h2的下一个ul标签(直接找ul的话会找到其他的ul),然后获取所有a标签
list_a = view_soup.find('h2').find_next_sibling('ul').find_all('a')
# 接着遍历a标签,把每集的地址取出来
view_link = domain + a.get('href')
我们继续看一个单集的播放的HTML,source标签里就是最终的资源地址了,一个MP4文件: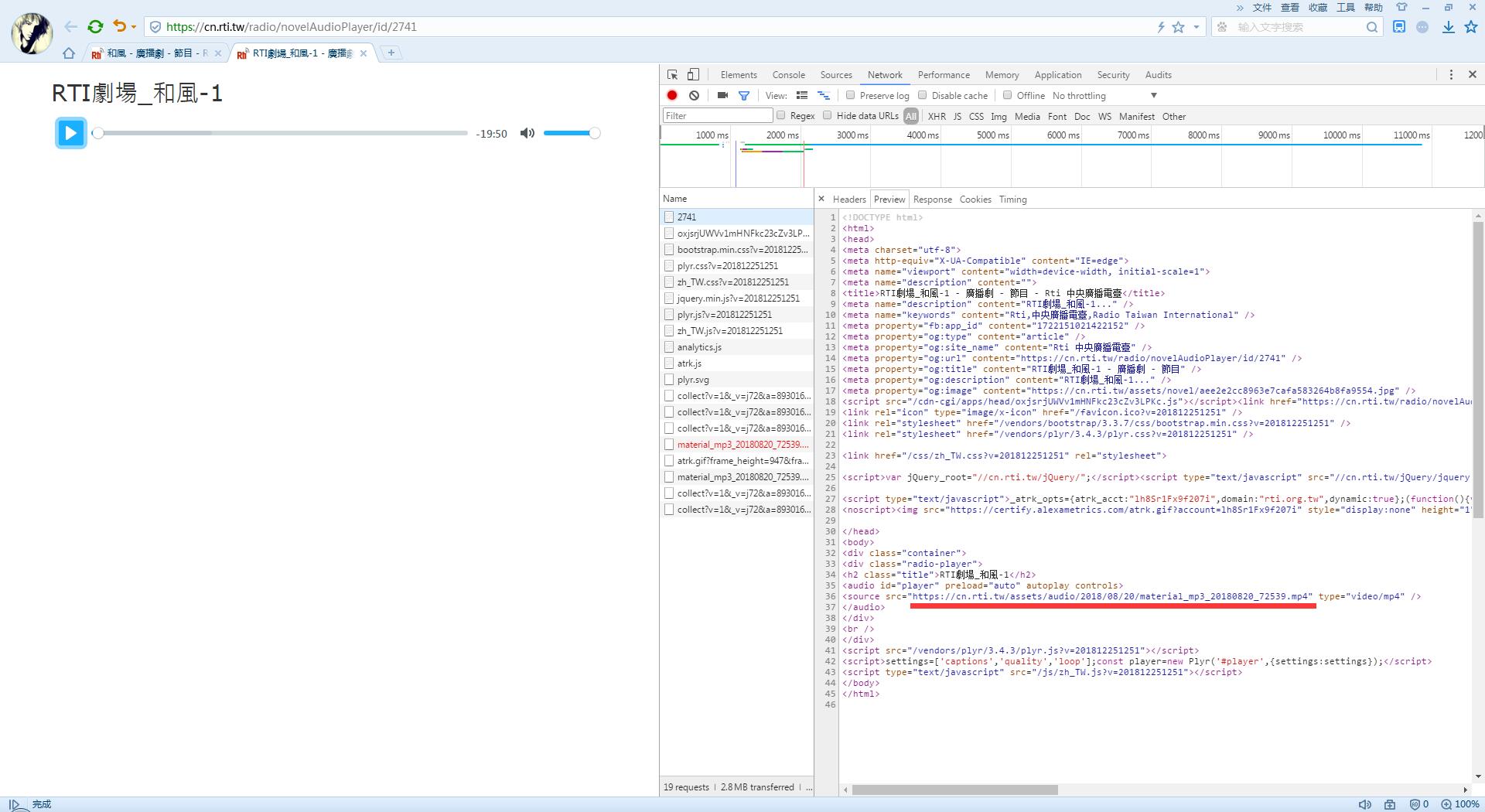
# 打开单集的播放页面
play_resp = requests.get(view_link)
play_soup = BeautifulSoup(play_resp.text, "lxml")
# 获取资源下载地址
src = play_soup.find('source').attrs['src']
现在我还不想下载,我希望先试听确认喜欢后再下载,所以我把下载地址存到一个txt里,一个广播剧存一个txt:
name = file_path + name + '.txt'
with open(name, 'wb') as f:
f.write(content)
由于编码问题,在文件最上加上以下代码:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
运行效果: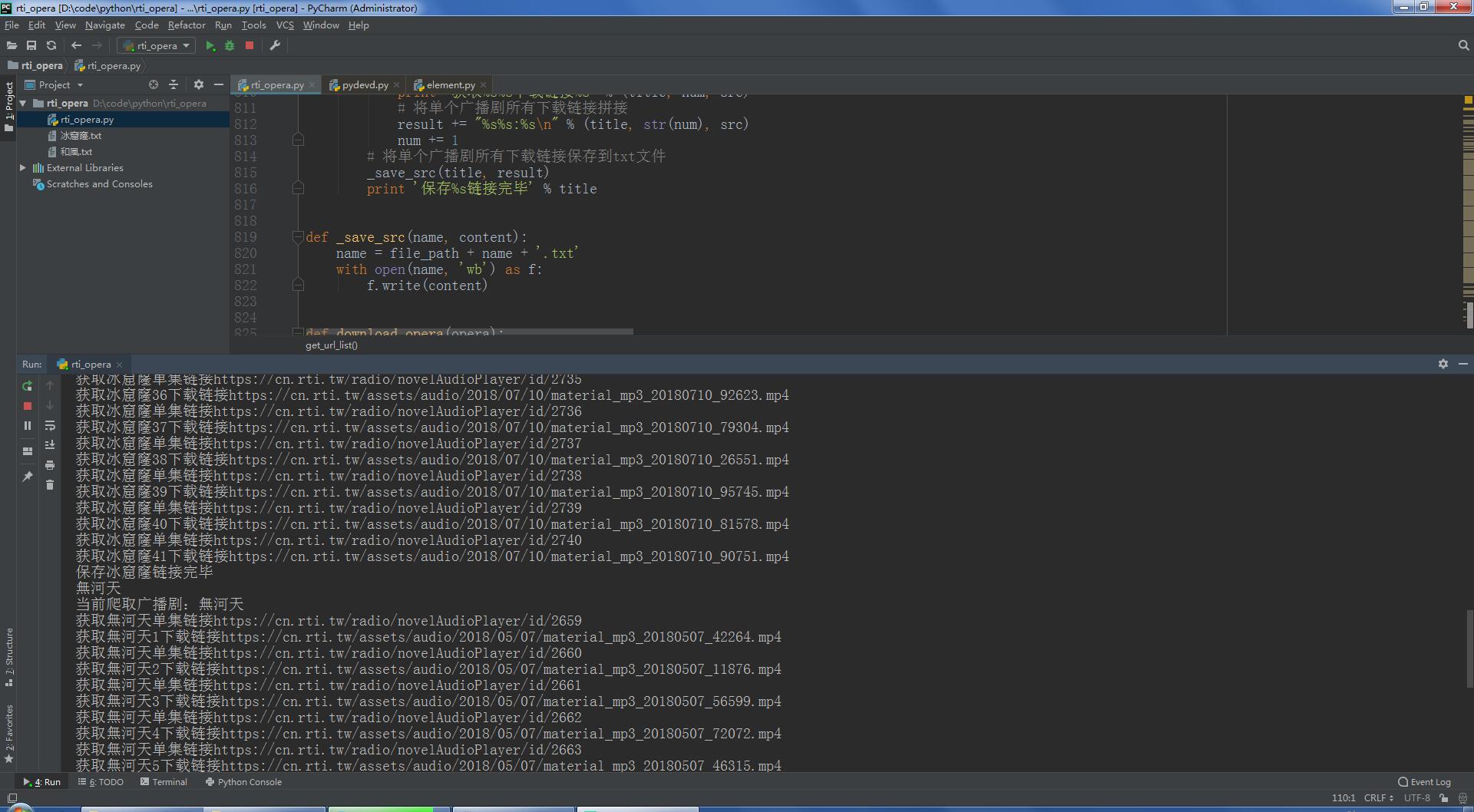
下载的MP4的代码:
# 使用requests的get方法访问下载链接
r = requests.get(url)
# 将访问返回二进制数据内容保存为MP4文件
with open(name, 'wb') as f:
f.write(r.content)
最终的运行结果:
源码地址:https://github.com/songzhenhua/rti_opera/blob/master/rti_opera.py
BeautifulSoup参考地址:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#attributes
http://www.cnblogs.com/zhaof/p/6930955.html
爬虫初体验:Python+Requests+BeautifulSoup抓取广播剧的更多相关文章
- python 爬虫(一) requests+BeautifulSoup 爬取简单网页代码示例
以前搞偷偷摸摸的事,不对,是搞爬虫都是用urllib,不过真的是很麻烦,下面就使用requests + BeautifulSoup 爬爬简单的网页. 详细介绍都在代码中注释了,大家可以参阅. # -* ...
- Python requests 多线程抓取 出现HTTPConnectionPool Max retires exceeded异常
https://segmentfault.com/q/1010000000517234 -- ::, - oracle - ERROR - data format error:HTTPConnecti ...
- Python爬虫之requests+正则表达式抓取猫眼电影top100以及瓜子二手网二手车信息(四)
requests+正则表达式抓取猫眼电影top100 一.首先我们先分析下网页结构 可以看到第一页的URL和第二页的URL的区别在于offset的值,第一页为0,第二页为10,以此类推. 二.< ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- 用python实现的抓取腾讯视频所有电影的爬虫
1. [代码]用python实现的抓取腾讯视频所有电影的爬虫 # -*- coding: utf-8 -*-# by awakenjoys. my site: www.dianying.atim ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- Python爬虫工程师必学——App数据抓取实战 ✌✌
Python爬虫工程师必学——App数据抓取实战 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 爬虫分为几大方向,WEB网页数据抓取.APP数据抓取.软件系统 ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
随机推荐
- eclipse 设置字体大小
步骤: 1.打开eclipse,在工具栏里找到 Window -> Perferences,打开如下图: 2.展开General -> Appearance -> Colors an ...
- async--ajax异步传输
如图:轨迹点组编号依赖所属路口的设置. 所以ajax是异步执行,获取到所属路口还没执行完,就已经执行到根据所述路口获取轨迹点组编号,所以获取不到轨迹点组编号. async:false改成同步执行.就没 ...
- [转]超全面的.NET GDI+图形图像编程教程
本篇主题内容是.NET GDI+图形图像编程系列的教程,不要被这个滚动条吓到,为了查找方便,我没有分开写,上面加了目录了,而且很多都是源码和图片~ GDI+绘图基础 编写图形程序时需要使用GDI(Gr ...
- javascript中filter方法
array1.filter(callbackfn[, thisArg]) 參數 參數 定義 array1 必要項. 陣列物件. callbackfn 必要項. 最多接受三個引數的函式. filte ...
- django模板中如何导入js、css等外部文件
本教程只适合Django1.4版本.(1.8版本之后不需要这么麻烦,详见 http://www.cnblogs.com/ryan255/p/5465608.html) html模板里面使用了css,但 ...
- 闲谈Hybrid
前言 当经常需要更换样式,产品迭代,那么我们应该考虑hybrid混合开发,上层使用Html&Css&JS做业务开发,底层透明化.上层多多样化,这种场景非常有利于前端介入,非常适合业务快 ...
- C++切勿混用带符号类型和无符号类型
如果表达式里既有带符号类型又有无符号类型,当带符号类型取值为负时会出现异常结果. 因为带符号数会自动转化为无符号数. 例如 a*b,a=-1, b=1,a是int,b是unsigned int,如果在 ...
- window.moveTo(),window.moveBy()不生效
window.moveTo()和window.moveBy的菜鸟教程介绍: moveTo() 方法可把窗口的左上角移动到一个指定的坐标. window.moveTo(x,y) moveBy() 方法可 ...
- 初识Java——第一章 初识Java
1. 计算机程序: 为了让计算机执行某些操作或解决某个问题而编写的一系列有序指令的集合. 2. JAVA相关的技术: 1).安装和运行在本机上的桌面程序 2).通过浏览器访问的面向 ...
- ethereum(以太坊)(十四)--Delete
pragma solidity ^0.4.10; contract Delete{ /* delete可用于任何变量(除mapping),将其设置成默认值 bytes/string:删除所有元素,其长 ...