劲(很)霸(不)酷(好)炫(用)的NLP可视化包:Dodorio 使用指北
朋友们,朋友们,事情是这样的。最近心血来潮,突然想起很久以前看过的一个NLP可视化包。它的效果是下面这个样子:
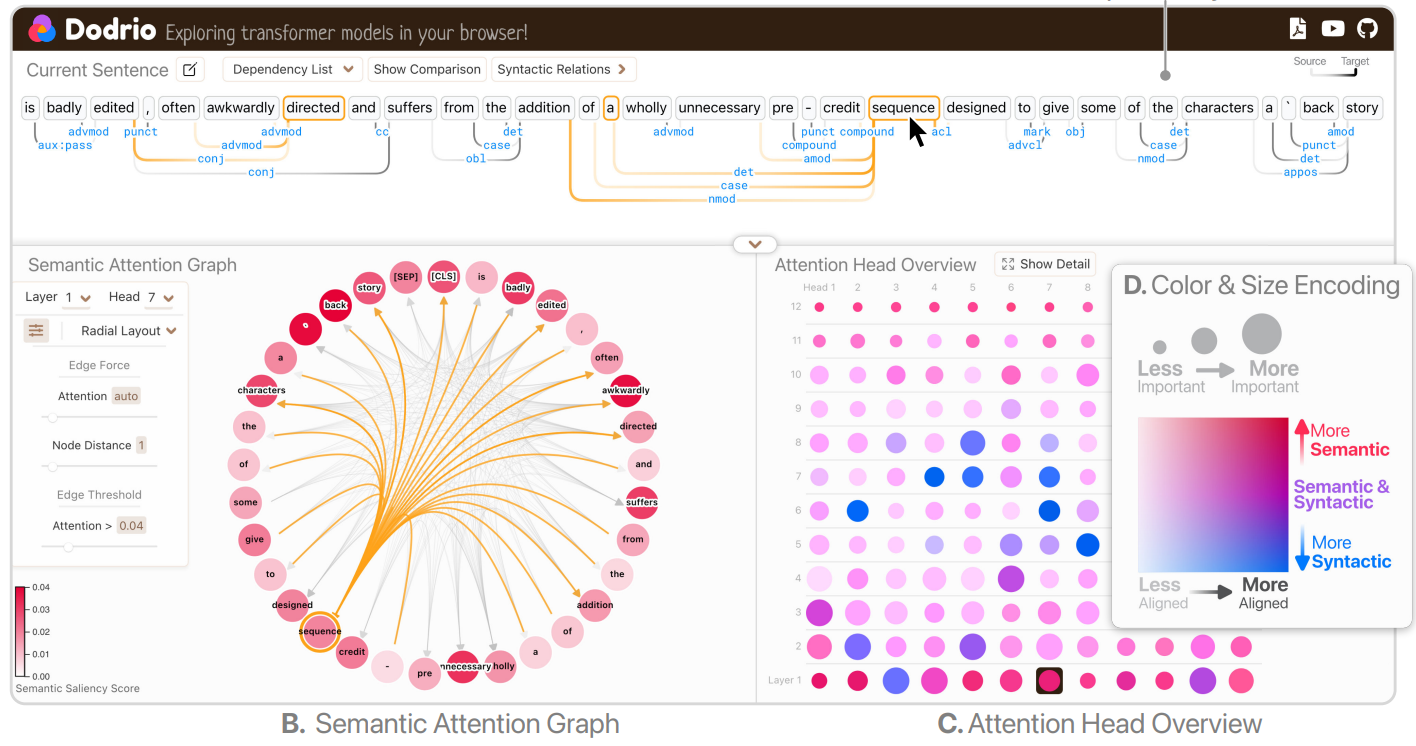
在此之前,已经有一些文章从论文的角度对这个包进行了介绍,详情请见
推荐一个可交互的 Attention 可视化工具!我的Transformer可解释性有救啦?
当时我第一眼就被这个包的效果折服了,想着这么有意思的东西,我高低得去试一试,于是我怀着好奇的心点进了这个项目的github主页,作者给出的使用介绍很简单:
首先,复制项目
git clone git@github.com:poloclub/dodrio.git然后,进入项目目录,安装依赖
npm install最后,直接运行即可
npm run dev
该项目会默认在localhost:5000创建一个本地服务,一旦运行完成且数据无误,就可以在本地看到上面炫酷的界面。
但事情远远没有那么简单,作者提供的模型只能解释其预先选择好的模型与数据集,要想真正用到自己的项目上,还需要对项目进行一定程度的客制化。于是大约在一年前,我尝试按照作者写在Readme中的方法,尝试将自己的模型与自己的数据集使用这个包进行可视化。殊不知,这对于我来说是噩梦的开始。在实验过程中,我遇到的困难包括且不仅限于以下几点:
该项目需要安装许多的依赖包,许多包存在着过期、更新等问题。同时,在本地部署时还会由于网络问题导致许多依赖无法正常安装。最重要的是,由于该包使用的Transformers版本是3.3.1,Python版本高于3.7将无法正常地安装与使用。
在远程服务器(例如Google Colab)等部署时,就不用担心出现网络问题导致的安装依赖失败,但由于服务是部署在本地,所以还需要使用nagrok、localtunnel等工具进行映射。
在data-generation.py中,除了修改模型与数据集外,一些函数的用法与位置也发生了改变,因此需要自己慢慢摸索与调试。
... ... ... ...
总之,之前尝试了很久之后还是没有结果,遂放弃。但是最近机缘巧合之中又接触到了这个包,恰逢《灌篮高手》上映,满腔热血无处释放,遂决定与这个磨人的包一教高下。
直言结论,仍然可以使用,并且可以针对本地模型与本地数据集进行客制化,以下列举调试过程中的一些重点:
首先确保环境中的
Transformers==3.3.1,其次,请pip install umap-learn而不是pip install umap,并在dodrio-data-gen.py的开头使用import umap.umap_ as umap代替import umap代码中存在大量的从checkpoint中导入模型,请根据实际需求注释掉或修改路径。
在运行
dodrio-data-gen.py前,要先在其同级目录下创建outputs文件夹,同时,在outputs文件夹下创建你的模型名-attention-data文件夹(用来储存attention权重)在运行
dodrio-data-gen.py时,可能会遇到各种各样的报错,对此,耐心寻找原因,都不难改。成功运行完
dodrio-data-gen.py后,会在目录下生成如下所示的这些文件:

最重要的是!!!!!!!项目从json文件中抽取数据时,在多个svelte文件中默认选择第1562个元素,但大多数情况下你的数据集中不一定有第1562项,因此你需要去多个文件中手动修改(当然也可以通过写config文件修改,但我是java小白,所以烦请大佬指导)
处理完以上这些步骤,就可以生成基于你自己模型与数据集的炫酷可视化图像了,效果如下:

## 好了,说了那么多,如果还是看不懂怎么办,这里附上我自己的傻瓜式教程:
Step 1. 下载项目(或者直接使用远程服务器也可以)
git clone git@github.com:poloclub/dodrio.git
Step 2. 安装依赖
npm install
Step 3. 检查你的环境
首先,要保证Python版本最好不大于3.7,以便安装Transformers==3.3.1,然后,安装一些必要的Python包,缺啥补啥,这个没什么好说的,注意要安装umap-learn而不是umap
Step 4. 进入dodrio文件夹修改data-generation/dodorio-data-gen.py文件:
首先,line65、line66、line71,line73分别修改你的标签数量、标签名、数据集名、要加载的Tokenizer;其次,line876左右,修改你的数据集地址,最好按照原数据集格式对你的数据集进行处理,我是这样做的:
点击查看代码
dataset_test = load_dataset('seamew/ChnSentiCorp', split='train[:20%]')
dataset_test = dataset_test.rename_columns({"text": "sentence"})
idx = range(len(dataset_test))
dataset_test = dataset_test.add_column("idx", idx)
其次,在dodorio-data-gen.py中,有许多:
点击查看代码
checkpoint = torch.load('./outputs/saved-bert-' + dataset_name + '.pt')
my_model.load_state_dict(checkpoint['model'])
如果你本地有checkpoint,那么就改成你自己的地址,如果没有,就直接注释掉,代码中有较多处,建议直接搜索并修改。
Step 5. 在运行dodrio-data-gen.py前,要先在其同级目录下创建outputs文件夹,同时,在outputs文件夹下创建你的模型名-attention-data文件夹(用来储存attention权重)。到这里为止,你应该已经成功运行完了dodrio-data-gen.py文件,那么你会发现其同级目录下多出了这些文件:
然后,将生成的所有文件以及所有文件夹移到dodrio/public/data下。
Step 6. 然后,最重要的一步,打开dodrio/Main.svelte,修改文件中的文件路径(与你上一步中生成的文件名称对应):

Step 7. 恭喜你到了这一步,接下来,要修改这个粗心作者犯下的错误。在项目中,作者将示例文件的ID固定成了1562,但往往我们使用的样本并没有1562这个样本,于是请你点击进入longest-300-id.json文件中,查看你的数据集包含哪些样本,及其ID为多少,选择一个你想测试的句子,记住它的ID。这里我假设想要测试的句子ID为1。、
去github中搜索所有存在Instence以及1562的字段,然后将所有的1562替换成1即可。
劲(很)霸(不)酷(好)炫(用)的NLP可视化包:Dodorio 使用指北的更多相关文章
- 3d轮播图(另一种方式,可以实现的功能更为强大也更为灵活,简单一句话,比酷狗优酷的炫)
前不久我做了一个3d仿酷狗的轮播图,用的技术原理就是简单的jquery遍历+css样式读写. 这次呢,我们换一种思路(呵呵其实换汤不换药),看到上次那个轮播吗?你有没有发现用jquery的animat ...
- 分享在github超酷超炫特效动画,不看你会懊悔的。
有图有真相直接上效果图,有须要的朋友们能够到连接上去下载. 下载地址:https://github.com/ChrisRenke/DrawerArrowDrawable 下载地址:https://gi ...
- Deep Learning in NLP (一)词向量和语言模型
原文转载:http://licstar.net/archives/328 Deep Learning 算法已经在图像和音频领域取得了惊人的成果,但是在 NLP 领域中尚未见到如此激动人心的结果.关于这 ...
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- Word2Vec之Deep Learning in NLP (一)词向量和语言模型
转自licstar,真心觉得不错,可惜自己有些东西没有看懂 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领域中应用的理解和总结,在此分享.其中必然有局限性,欢迎各种交 ...
- 【NLP】自然语言处理:词向量和语言模型
声明: 这是转载自LICSTAR博士的牛文,原文载于此:http://licstar.net/archives/328 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领 ...
- Python绘制六种可视化图表详解,三维图最炫酷!你觉得呢?
Python绘制六种可视化图表详解,三维图最炫酷!你觉得呢? 可视化图表,有相当多种,但常见的也就下面几种,其他比较复杂一点,大都也是基于如下几种进行组合,变换出来的.对于初学者来说,很容易被这官网上 ...
- Flutter酷炫的路由动画效果
现在Flutter的路由效果已经非常不错了,能满足大部分App的需求,但是谁不希望自己的App更酷更炫那,下面介绍几个酷炫的路由动画. 其实路由动画的原理很简单,就是重写并继承PageRouterBu ...
- 如何让Ubuntu 12.04 LTS更炫更具吸引力
Ubuntu 12.04 LTS震撼发布 适逢七周岁生日之际,Ubuntu正式推出了第四个LTS长期支持版本,开发代号Precise Pangolin的Ubuntu 12.04在2012年4月26 ...
- Canvas跟随鼠标炫彩小球
跟随鼠标炫彩小球 canvas没有让我失望,真的很有意思 实现效果 超级炫酷 实现原理 创建小球 给小球添加随机颜色,随机半径 鼠标移动通过实例化,新增小球 通过调用给原型新增的方法,来实现小球的动画 ...
随机推荐
- logrotate 切割Tomcat的catalina.out文件
使用logrotate进行切割. 在/etc/logrotate.d下,新建tomcatrotate,编辑tomatrotate,写入如下内容: /usr/local/tomcat/logs ...
- pod进阶
一.Lifecycle 官网:https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/ 通过前面的分享,关于pod是什么相信看 ...
- mysql安装调试
mysql安装 1.下载mysql的压缩包 tar -xvzf mysql-5.6.38-linux-glibc2.12-i686.tar.gz2.安装之后密码是随机的,所以我们需要重新修改密码: [ ...
- sql server 索引检测
-- 声明表变量 DECLARE @userTable TABLE (table_name NVARCHAR(20)); -- 将源表中的数据插入到表变量中 INSERT INTO @userTabl ...
- P2671 [NOIP2015 普及组] 求和
[NOIP2015 普及组] 求和 题目背景 NOIP2015 普及组 T3 题目描述 一条狭长的纸带被均匀划分出了\(n\)个格子,格子编号从\(1\)到\(n\).每个格子上都染了一种颜色\(co ...
- UGUI六大基础组件——Graphic Raycaster
一.组件作用 图形摄像投射器是用于检测UI输入事件的射线发射器.通过射线检测玩家和用户的交互,判断是否点击到了UI元素. 注意:不是通过碰撞器来检测的,而是通过图形来检测的. 二.参数解释 ***** ...
- CUDA基础2
二. 1.指令调度,对于多条指令怎样调度让他们运行更快. 对于有冲突的两条指令,采用寄存器重命名技术. 2.指令重排 乱序执行,为了获取最大的吞吐率. 增大功耗 增加芯片面积. 3.缓存,容量越大 ...
- 把 ChatGPT 加入 Flutter 开发,会有怎样的体验?
前言 ChatGPT 最近一直都处于技术圈的讨论焦点.它除了可作为普通用户的日常 AI 助手,还可以帮助开发者加速开发进度.声网社区的一位开发者"小猿"就基于 ChatGPT 做了 ...
- 声网深度学习时序编码器的资源预测实践丨Dev for Dev 专栏
本文为「Dev for Dev 专栏」系列内容,作者为声网大后端智能运营算法团队 算法工程师@黄南薰. 随着深度学习技术的发展,编码器的结构在构建神经网络中成为了热门之选,在计算机视觉领域有众多成功案 ...
- 【读书笔记】排列研究-模式避免-续篇Pattern Avoidance
目录 多项式递归Polynomial Recursions P-recursive和c-recursive定义 例子:卡特兰数序列是P-recursive(或者说D-finite) 两个说明\(S_n ...