用深度学习模型Word2Vec探索《红楼梦》人物关系
先来看一看结果,发现:
1.贾宝玉和袭人的关系最近。
2.薛宝钗和自己的妈妈关系最近。
3.贾宝玉和林黛玉逼格比较统一,薛宝钗属于独树一帜的逼格调性。
4.大观园中可以看到邢岫烟经常出没...
还有更多秘密等你自己上手去训练模型并发现...
开始写代码!
1from tqdm import tqdm
2#tqdm用来观察进度条,非必须
3import jieba
4import sys
5import os
声明一下,这里自定义了两个词典分别命名为“renming.txt”和“diming.txt”,分别写入了红楼梦中常见人名地名,这里展示一下格式,有需要的可以添加我微信dicey0310


继续写代码!
1os.chdir("C://users//dicey//desktop")
2# 调用 jieba分词module后,添加单词本(人名等):
3jieba.load_userdict("renming.txt")
4jieba.load_userdict("diming.txt")
5
6#这里是在百度上下载的红楼梦完整版的txt
7filename = 'HongLouMeng.txt'
8text_lines = []
9with open(filename,encoding='utf-8',errors='ignore') as f:
10 for line in tqdm(f):
11 text_lines.append(line)
12print('总共读入%d行文字'% (len(text_lines)))
13
14#检查一下读入文字的正确性
15print(text_lines[17])
把红楼梦的txt版(utf-8编码)一行一行读进来,用tqdm辅助显示进度条:
1data_lines = []
2
3## 分词并添加进列表:
4for line in tqdm(text_lines):
5 one_line = [' '.join(jieba.cut(line, cut_all=False))][0].split(' ')
6 data_lines.append(one_line)
开始数据预处理,去除了标点符号、数字、停用词:
1import re
2# 标点符号 (punctuation)
3punct = set(u'''.&#:!),.:;?]}¢'"、。〉》」』】〕〗〞︰︱︳﹐、﹒﹔﹕﹖﹗﹚﹜﹞! .&# &# ),.*:;O?|}︴︶︸︺︼︾﹀﹂﹄﹏、~¢々‖•·ˇˉ―--′’”([{£¥'"‵〈《「『【〔〖([{£¥〝︵︷︹︻︽︿﹁﹃﹙﹛﹝({“‘-—_…0123456789''')
4isNumber = re.compile(r'\d+.*')
5with open('stopwords.txt',encoding='utf-8',errors='ignore') as f:
6 stopwords = f.read()
7filter_words = [w for w in data_words if (w not in punct)
8 and (not isNumber.search(w.lower()))and(w not in stopwords)]
引入gensim库,并使用Word2Vec模型构造内部字典树,和训练神经模型:
1import gensim
2model = gensim.models.Word2Vec(iter=1)
3# an empty model, no training yet
4model.build_vocab(data_lines) #传入语料,构建内部字典树
5model.train(data_lines, total_examples = len(data_lines), epochs = 100)
6#开始训练神经模型100次
7#epochs表示训练次数
注意,上面这块代码也可换做下面这样的简写法:
1import gensim
2model = gensim.models.Word2Vec(data_lines,iter=10)
3'''
4直接把data_lines喂给World2Vec模型,
510代表会调用句子迭代器运行11次(一般来说,会运行 iter+1 次,默认情况下 iter=5)。
6第一次运行负责收集单词和它们的出现频率,从而构造一个内部字典树。第二次以及以后的运行负责训练神经模型(train)。
7'''
开始读入我们关心的人名、地名,并打印结果:
1test_words = ['林黛玉','黛玉','贾宝玉','宝玉','薛宝钗','宝钗','袭人','大观园','潇湘馆','蘅芜苑','妙玉','栊翠庵']
2#开始读入
3neighbors = []
4for test_word in test_words:
5 neighbors.append(model.most_similar(test_word))
6#开始打印结果
7for i in range(len(neighbors)):
8 str = ' '.join([x[0] for x in neighbors[i]])
9 print('%s:' % test_words[i])
10 print('\t%s\n' % (str))
这里展示部分结果:(每个人名、地名之后跟的是与自己关系最密切/在100维词向量中最相近的名词)

最后我们看一下“黛玉”的坐标(100维),以及“黛玉”和“林黛玉”之间的相似度。
1print(model["黛玉"])
2print(model.similarity("黛玉",'林黛玉'))
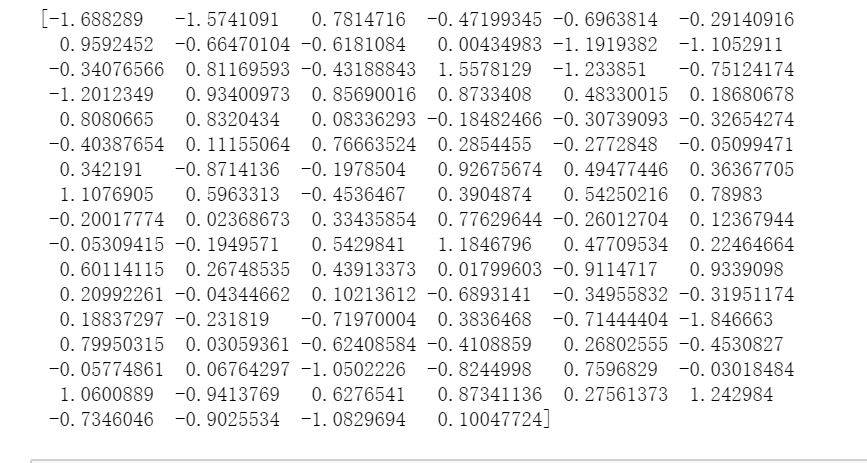

注意:相似度不为1(相似度等于1时代表词向量在每个维度上都完全相等)。是因为叫“林黛玉”时常为正式场合,直呼“黛玉”时一般属于日常情况,相信各位懂得~
用深度学习模型Word2Vec探索《红楼梦》人物关系的更多相关文章
- 红楼梦人物关系图,一代大师成绝响,下回分解待何人,kindle读书摘要
人物关系图: https://www.cnblogs.com/images/cnblogs_com/elesos/1120632/o_2033091006.jpg 红楼梦 (古典名著普及文库) ( ...
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- 深度学习模型stacking模型融合python代码,看了你就会使
话不多说,直接上代码 def stacking_first(train, train_y, test): savepath = './stack_op{}_dt{}_tfidf{}/'.format( ...
- 深度学习模型融合stacking
当你的深度学习模型变得很多时,选一个确定的模型也是一个头痛的问题.或者你可以把他们都用起来,就进行模型融合.我主要使用stacking和blend方法.先把代码贴出来,大家可以看一下. import ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
- Roofline Model与深度学习模型的性能分析
原文链接: https://zhuanlan.zhihu.com/p/34204282 最近在不同的计算平台上验证几种经典深度学习模型的训练和预测性能时,经常遇到模型的实际测试性能表现和自己计算出的复 ...
- 在NLP中深度学习模型何时需要树形结构?
在NLP中深度学习模型何时需要树形结构? 前段时间阅读了Jiwei Li等人[1]在EMNLP2015上发表的论文<When Are Tree Structures Necessary for ...
随机推荐
- win7电脑休眠后只能按重启键解决办法
一.点击"开始"后选择控制面板 二.选择"电源选项" 三.点击"更改计划设置" 四.选择"更改高级电源设置" 五.点击& ...
- (已经成功部署)配置vue+nginx+uwsgi luffy项目
2019-9-16 21:16:17 由于超哥视频翻车,应该是先改api.js中的IP 再打包 然后按照原来一步一步部署vue uwsgi Nginx 然后就可以直接访问了!!! 昨天其实就完成,只 ...
- Web Socket 长连接
服务 package com.kinth.basic.timetask.job.donghuan.socket; import java.io.IOException; import java.net ...
- 分析网络工具 Wireshark与tcpdump
一.安装使用 1. 安装 2. 选择网卡:我们的主机就是通过其中一块网卡和其他主机进行数据交互: 3. 点击开始:打开wireshark,点击左上角那个蓝色的鲨鱼鳍按钮,开始捕获新的分组并清空之前的分 ...
- PHP Array数组
PHP中的数组实际上是一个有序映射.映射是一种把values关联到keys的类型.此类型在很多方面做了优化,因此可以把它当成真正的数组,或列表(向量),散列表(是映射的一种实现),字典,集合,栈,队列 ...
- elementUI合并单元格
<el-table :data="tableDataFormat" border :header-cell-style="{background:'#FAFAFA' ...
- QT中文显示乱码
1. 环境:VS2015+QT5.10 解决:在头文件中声明 #pragma execution_character_set("utf-8") 2. QT5.10中控件显示中文 ...
- 如何理解Vue中的组件?
Vue2.6已经更新了关于内容插槽和作用域插槽的API和用法,为了不误导大家,我把插槽的内容删除了.详情请看官网 2018-07-19更新: 更新作用域插槽的属性: scope -> slot- ...
- 和为K的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的连续子数组的个数 . /** * @param {number[]} nums * @param {number} k ...
- class_man
#!/usr/bin/python # -*- coding: UTF-8 -*- class Man(): def __init__(self, name="" ...