3.7:基于Weka的K-means聚类的算法示例
〇、目标
1、使用Weka平台,并在该平台使用数据导入、可视化等基本操作;
2、对K-means算法的不同初始k值进行比较,对比结果得出结论。
一、打开Weka3.8并导入数据
二、导入数据
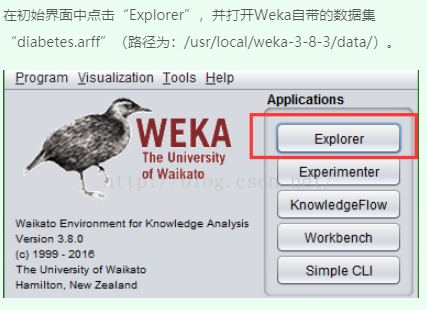
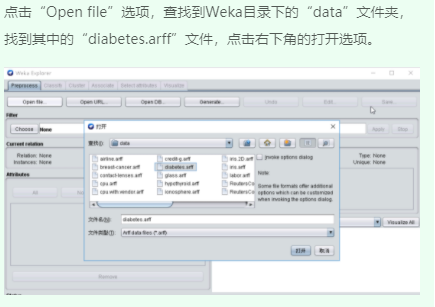
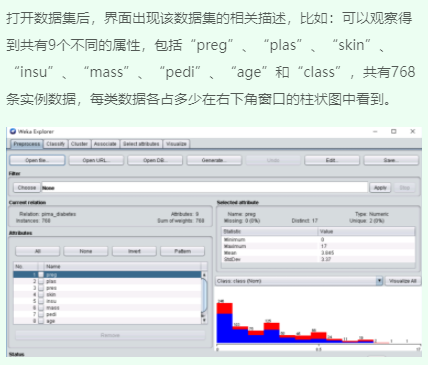
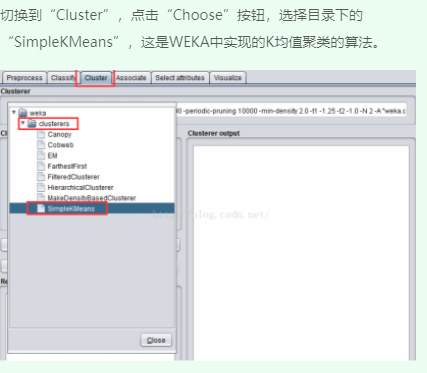
三、SimpleKMeans算法聚类
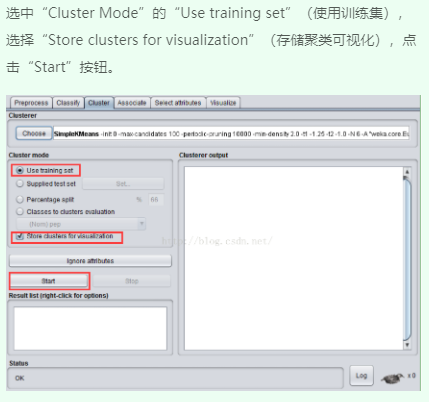
四、运行观察结果
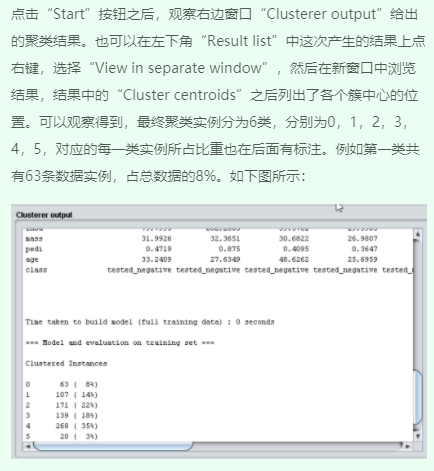
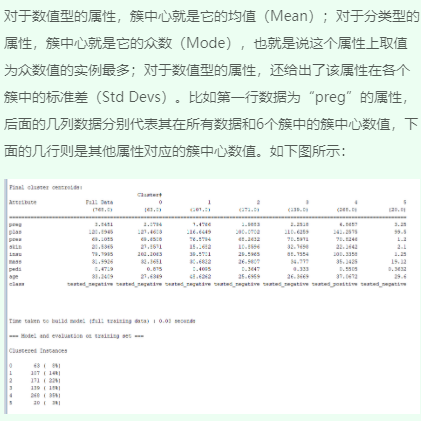
1、观察聚类输出结果
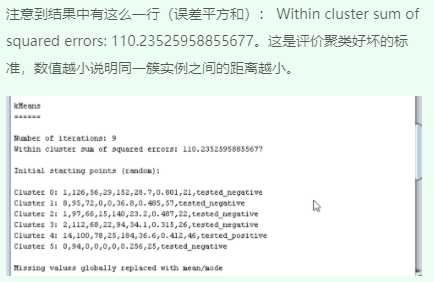
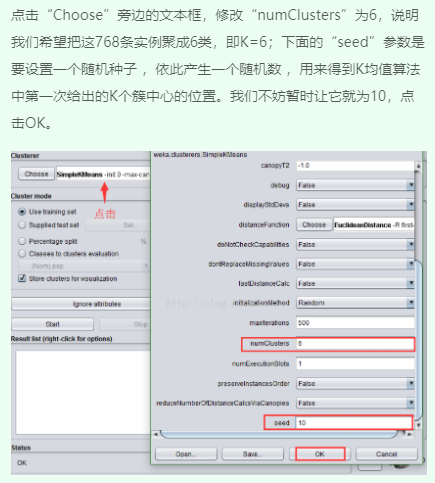
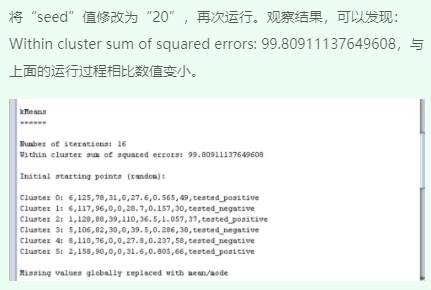
2、修改参数值重新运行并观察结果

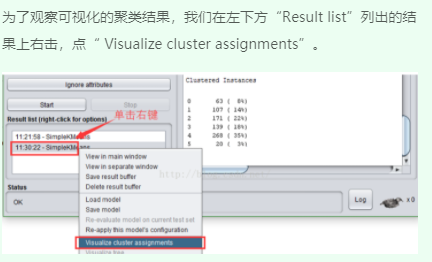
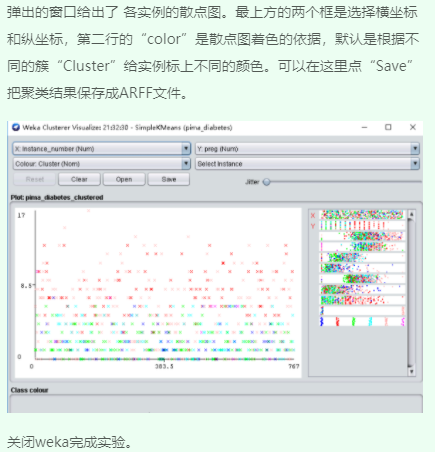
3、可视化聚类结果
3.7:基于Weka的K-means聚类的算法示例的更多相关文章
- R与数据分析旧笔记(十五) 基于有代表性的点的技术:K中心聚类法
基于有代表性的点的技术:K中心聚类法 基于有代表性的点的技术:K中心聚类法 算法步骤 随机选择k个点作为"中心点" 计算剩余的点到这个k中心点的距离,每个点被分配到最近的中心点组成 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- SciPy k均值聚类
章节 SciPy 介绍 SciPy 安装 SciPy 基础功能 SciPy 特殊函数 SciPy k均值聚类 SciPy 常量 SciPy fftpack(傅里叶变换) SciPy 积分 SciPy ...
- Sklearn K均值聚类
## 版权所有,转帖注明出处 章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Lear ...
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
随机推荐
- PostgreSQL逻辑复制解密
在数字化时代的今天,我们都认同数据会创造价值.为了最大化数据的价值,我们不停的建立着数据迁移的管道,从同构到异构,从关系型到非关系型,从云下到云上,从数仓到数据湖,试图在各种场景挖掘数据的价值.而在这 ...
- Prometheus 监控外部 Kubernetes 集群
转载自:https://www.qikqiak.com/post/monitor-external-k8s-on-prometheus/ 在实际环境中很多企业是将 Prometheus 单独部署在集群 ...
- es,logstash各版本对应要求的JDK版本,操作系统对应示意图
官网地址:https://www.elastic.co/cn/support/matrix
- Kubernetes生态架构图
图片来源于:https://gitbook.curiouser.top/ 一.kubernetes 集群架构图 二.Openshift or Kubernetes 集群架构图 三.常见的 CI/CD ...
- 如何在 Docker 之上使用 Elastic Stack 和 Kafka 可视化公共交通
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/106498568 需要掌握的知识点: 1.使用docker-compose方式部署一套 ...
- Exporter介绍
Exporter是什么 广义上讲所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter.而Exporter的一个实例称为target,如下所示,Prometheus通过轮 ...
- 12. Fluentd部署:多Workers进程模式
介绍如何使用Fluentd的多worker模式处理高访问量的日志事件.此模式会运行多个worker进程以最大利用多核CPU. 原理 默认情况下,一个Fluentd实例会运行一个监控进程和一个工作进程. ...
- 【golang】json数据解析 - 嵌套json解析
@ 目录 1. 通过结构体映射解析 2. 嵌套json解析-map 1. 通过结构体映射解析 原数据结构 解析 // 结构体 type contractJson struct { Data []tra ...
- 报时机器人的rasa shell执行流程分析
本文以报时机器人为载体,介绍了报时机器人的对话能力范围.配置文件功能和训练和运行命令,重点介绍了rasa shell命令启动后的程序执行过程. 一.报时机器人项目结构 1.对话能力范围 (1)能够 ...
- VMware安装Win11+WSA子系统和使用教程
VMware安装Win11+WSA子系统和使用教程 作者:Sna1lGo 时间:2022/9/29 下载相关文件: Win11镜像:Download Windows 11 (microsoft.com ...