面试官:MySQL一千万数据,怎么快速查询?
前言
- 面试官:来说说,一千万的数据,你是怎么查询的?
- me:直接分页查询,使用limit分页。
- 面试官:有实操过吗?
- me:肯定有呀
此刻献上一首《凉凉》
也许有些人没遇过上千万数据量的表,也不清楚查询上千万数据量的时候会发生什么。
今天就来带大家实操一下,这次是基于MySQL 5.7.26做测试
准备数据
没有一千万的数据怎么办?
创建呗
代码创建一千万?那是不可能的,太慢了,可能真的要跑一天。可以采用数据库脚本执行速度快很多。
创建表
CREATE TABLE `user_operation_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`ip` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`op_data` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr3` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr4` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr5` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr6` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr7` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr8` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr9` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr10` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr11` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr12` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
创建数据脚本
采用批量插入,效率会快很多,而且每1000条数就commit,数据量太大,也会导致批量插入效率慢
DELIMITER ;;
CREATE PROCEDURE batch_insert_log()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE userId INT DEFAULT 10000000;
set @execSql = ‘INSERT INTO `test`.`user_operation_log`(`user_id`, `ip`, `op_data`, `attr1`, `attr2`, `attr3`, `attr4`, `attr5`, `attr6`, `attr7`, `attr8`, `attr9`, `attr10`, `attr11`, `attr12`) VALUES’;
set @execData = ”;
WHILE i<=10000000 DO
set @attr = “‘测试很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长的属性'”;
set @execData = concat(@execData, “(“, userId + i, “, ‘10.0.69.175’, ‘用户登录操作'”, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “)”);
if i % 1000 = 0
then
set @stmtSql = concat(@execSql, @execData,”;”);
prepare stmt from @stmtSql;
execute stmt;
DEALLOCATE prepare stmt;
commit;
set @execData = “”;
else
set @execData = concat(@execData, “,”);
end if;
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
开始测试
哥的电脑配置比较低:win10 标压渣渣i5 读写约500MB的SSD
由于配置低,本次测试只准备了3148000条数据,占用了磁盘5G(还没建索引的情况下),跑了38min,电脑配置好的同学,可以插入多点数据测试
SELECT count(1) FROM `user_operation_log`
返回结果:3148000
返回结果:3148000
三次查询时间分别为:
- 14060 ms
- 13755 ms
- 13447 ms
普通分页查询
MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
MySQL分页查询语法如下:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
- 第一个参数指定第一个返回记录行的偏移量
- 第二个参数指定返回记录行的最大数目
下面我们开始测试查询结果:
SELECT * FROM `user_operation_log` LIMIT 10000, 10
查询3次时间分别为:
- 59 ms
- 49 ms
- 50 ms
这样看起来速度还行,不过是本地数据库,速度自然快点。
换个角度来测试
相同偏移量,不同数据量
SELECT * FROM `user_operation_log` LIMIT 10000, 10
SELECT * FROM `user_operation_log` LIMIT 10000, 100
SELECT * FROM `user_operation_log` LIMIT 10000, 1000
SELECT * FROM `user_operation_log` LIMIT 10000, 10000
SELECT * FROM `user_operation_log` LIMIT 10000, 100000
SELECT * FROM `user_operation_log` LIMIT 10000, 1000000
查询时间如下:
数量
第一次
第二次
第三次

从上面结果可以得出结束:数据量越大,花费时间越长
相同数据量,不同偏移量
SELECT * FROM `user_operation_log` LIMIT 100, 100
SELECT * FROM `user_operation_log` LIMIT 1000, 100
SELECT * FROM `user_operation_log` LIMIT 10000, 100
SELECT * FROM `user_operation_log` LIMIT 100000, 100
SELECT * FROM `user_operation_log` LIMIT 1000000, 100
偏移量
第一次
第二次
第三次

从上面结果可以得出结束:偏移量越大,花费时间越长
SELECT * FROM `user_operation_log` LIMIT 100, 100
SELECT id, attr FROM `user_operation_log` LIMIT 100, 100
如何优化
既然我们经过上面一番的折腾,也得出了结论,针对上面两个问题:偏移大、数据量大,我们分别着手优化
优化偏移量大问题
采用子查询方式
我们可以先定位偏移位置的 id,然后再查询数据
SELECT * FROM `user_operation_log` LIMIT 1000000, 10
SELECT id FROM `user_operation_log` LIMIT 1000000, 1
SELECT * FROM `user_operation_log` WHERE id >= (SELECT id FROM `user_operation_log` LIMIT 1000000, 1) LIMIT 10
查询结果如下:
sql
花费时间

从上面结果得出结论:
第一条花费的时间最大,第三条比第一条稍微好点
子查询使用索引速度更快
缺点:只适用于id递增的情况
id非递增的情况可以使用以下写法,但这种缺点是分页查询只能放在子查询里面
注意:某些 mysql 版本不支持在 in 子句中使用 limit,所以采用了多个嵌套select
SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT 1000000, 10) AS t)
采用 id 限定方式
这种方法要求更高些,id必须是连续递增,而且还得计算id的范围,然后使用 between,sql如下
SELECT * FROM `user_operation_log` WHERE id between 1000000 AND 1000100 LIMIT 100
SELECT * FROM `user_operation_log` WHERE id >= 1000000 LIMIT 100
查询结果如下:
sql
花费时间

从结果可以看出这种方式非常快
注意:这里的 LIMIT 是限制了条数,没有采用偏移量
优化数据量大问题
返回结果的数据量也会直接影响速度
SELECT * FROM `user_operation_log` LIMIT 1, 1000000
SELECT id FROM `user_operation_log` LIMIT 1, 1000000
SELECT id, user_id, ip, op_data, attr1, attr2, attr3, attr4, attr5, attr6, attr7, attr8, attr9, attr10, attr11, attr12 FROM `user_operation_log` LIMIT 1, 1000000
查询结果如下:
sql
花费时间

从结果可以看出减少不需要的列,查询效率也可以得到明显提升
第一条和第三条查询速度差不多,这时候你肯定会吐槽,那我还写那么多字段干啥呢,直接 * 不就完事了
注意本人的 MySQL 服务器和客户端是在_同一台机器_上,所以查询数据相差不多,有条件的同学可以测测客户端与MySQL分开
SELECT * 它不香吗?
在这里顺便补充一下为什么要禁止 SELECT *。难道简单无脑,它不香吗?
主要两点:
- 用 “SELECT * ” 数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
- 增大网络开销,* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。特别是MySQL和应用程序不在同一台机器,这种开销非常明显。
结束
最后还是希望大家自己去实操一下,肯定还可以收获更多!
前言
- 面试官:来说说,一千万的数据,你是怎么查询的?
- me:直接分页查询,使用limit分页。
- 面试官:有实操过吗?
- me:肯定有呀
此刻献上一首《凉凉》
也许有些人没遇过上千万数据量的表,也不清楚查询上千万数据量的时候会发生什么。
今天就来带大家实操一下,这次是基于MySQL 5.7.26做测试
准备数据
没有一千万的数据怎么办?
创建呗
代码创建一千万?那是不可能的,太慢了,可能真的要跑一天。可以采用数据库脚本执行速度快很多。
创建表
CREATE TABLE `user_operation_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`ip` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`op_data` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr3` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr4` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr5` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr6` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr7` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr8` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr9` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr10` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr11` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr12` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
创建数据脚本
采用批量插入,效率会快很多,而且每1000条数就commit,数据量太大,也会导致批量插入效率慢
DELIMITER ;;
CREATE PROCEDURE batch_insert_log()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE userId INT DEFAULT 10000000;
set @execSql = ‘INSERT INTO `test`.`user_operation_log`(`user_id`, `ip`, `op_data`, `attr1`, `attr2`, `attr3`, `attr4`, `attr5`, `attr6`, `attr7`, `attr8`, `attr9`, `attr10`, `attr11`, `attr12`) VALUES’;
set @execData = ”;
WHILE i<=10000000 DO
set @attr = “‘测试很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长的属性'”;
set @execData = concat(@execData, “(“, userId + i, “, ‘10.0.69.175’, ‘用户登录操作'”, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “,”, @attr, “)”);
if i % 1000 = 0
then
set @stmtSql = concat(@execSql, @execData,”;”);
prepare stmt from @stmtSql;
execute stmt;
DEALLOCATE prepare stmt;
commit;
set @execData = “”;
else
set @execData = concat(@execData, “,”);
end if;
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
开始测试
哥的电脑配置比较低:win10 标压渣渣i5 读写约500MB的SSD
由于配置低,本次测试只准备了3148000条数据,占用了磁盘5G(还没建索引的情况下),跑了38min,电脑配置好的同学,可以插入多点数据测试
SELECT count(1) FROM `user_operation_log`
返回结果:3148000
返回结果:3148000
三次查询时间分别为:
- 14060 ms
- 13755 ms
- 13447 ms
普通分页查询
MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
MySQL分页查询语法如下:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
- 第一个参数指定第一个返回记录行的偏移量
- 第二个参数指定返回记录行的最大数目
下面我们开始测试查询结果:
SELECT * FROM `user_operation_log` LIMIT 10000, 10
查询3次时间分别为:
- 59 ms
- 49 ms
- 50 ms
这样看起来速度还行,不过是本地数据库,速度自然快点。
换个角度来测试
相同偏移量,不同数据量
SELECT * FROM `user_operation_log` LIMIT 10000, 10
SELECT * FROM `user_operation_log` LIMIT 10000, 100
SELECT * FROM `user_operation_log` LIMIT 10000, 1000
SELECT * FROM `user_operation_log` LIMIT 10000, 10000
SELECT * FROM `user_operation_log` LIMIT 10000, 100000
SELECT * FROM `user_operation_log` LIMIT 10000, 1000000
查询时间如下:
数量
第一次
第二次
第三次
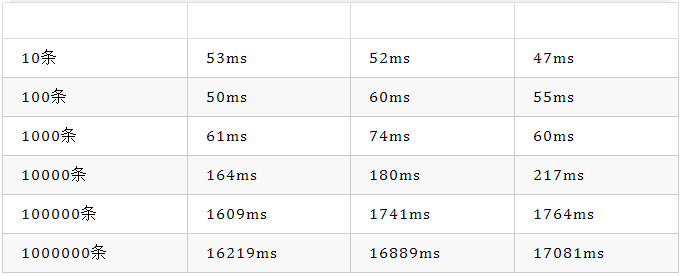 从上面结果可以得出结束:数据量越大,花费时间越长
从上面结果可以得出结束:数据量越大,花费时间越长
相同数据量,不同偏移量
SELECT * FROM `user_operation_log` LIMIT 100, 100
SELECT * FROM `user_operation_log` LIMIT 1000, 100
SELECT * FROM `user_operation_log` LIMIT 10000, 100
SELECT * FROM `user_operation_log` LIMIT 100000, 100
SELECT * FROM `user_operation_log` LIMIT 1000000, 100
偏移量
第一次
第二次
第三次
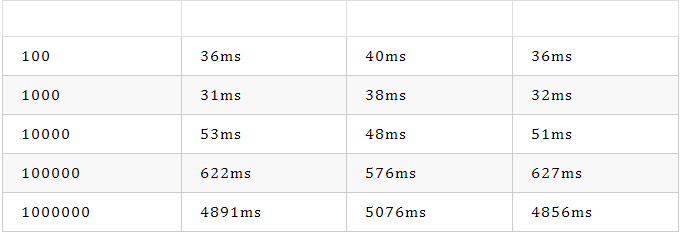 从上面结果可以得出结束:偏移量越大,花费时间越长
从上面结果可以得出结束:偏移量越大,花费时间越长
SELECT * FROM `user_operation_log` LIMIT 100, 100
SELECT id, attr FROM `user_operation_log` LIMIT 100, 100
如何优化
既然我们经过上面一番的折腾,也得出了结论,针对上面两个问题:偏移大、数据量大,我们分别着手优化
优化偏移量大问题
采用子查询方式
我们可以先定位偏移位置的 id,然后再查询数据
SELECT * FROM `user_operation_log` LIMIT 1000000, 10
SELECT id FROM `user_operation_log` LIMIT 1000000, 1
SELECT * FROM `user_operation_log` WHERE id >= (SELECT id FROM `user_operation_log` LIMIT 1000000, 1) LIMIT 10
查询结果如下:
sql
花费时间
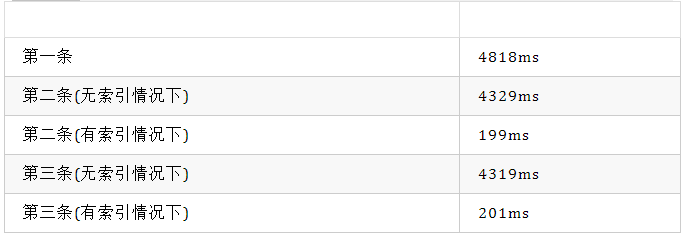 从上面结果得出结论:
从上面结果得出结论:
第一条花费的时间最大,第三条比第一条稍微好点
子查询使用索引速度更快
缺点:只适用于id递增的情况
id非递增的情况可以使用以下写法,但这种缺点是分页查询只能放在子查询里面
注意:某些 mysql 版本不支持在 in 子句中使用 limit,所以采用了多个嵌套select
SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT 1000000, 10) AS t)
采用 id 限定方式
这种方法要求更高些,id必须是连续递增,而且还得计算id的范围,然后使用 between,sql如下
SELECT * FROM `user_operation_log` WHERE id between 1000000 AND 1000100 LIMIT 100
SELECT * FROM `user_operation_log` WHERE id >= 1000000 LIMIT 100
查询结果如下:
sql
花费时间

从结果可以看出这种方式非常快
注意:这里的 LIMIT 是限制了条数,没有采用偏移量
优化数据量大问题
返回结果的数据量也会直接影响速度
SELECT * FROM `user_operation_log` LIMIT 1, 1000000
SELECT id FROM `user_operation_log` LIMIT 1, 1000000
SELECT id, user_id, ip, op_data, attr1, attr2, attr3, attr4, attr5, attr6, attr7, attr8, attr9, attr10, attr11, attr12 FROM `user_operation_log` LIMIT 1, 1000000
查询结果如下:
sql
花费时间
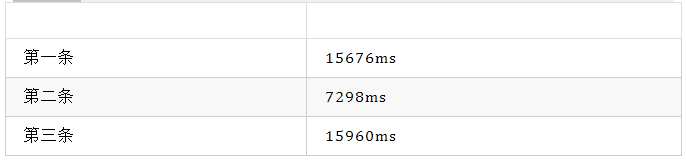
从结果可以看出减少不需要的列,查询效率也可以得到明显提升
第一条和第三条查询速度差不多,这时候你肯定会吐槽,那我还写那么多字段干啥呢,直接 * 不就完事了
注意本人的 MySQL 服务器和客户端是在_同一台机器_上,所以查询数据相差不多,有条件的同学可以测测客户端与MySQL分开
SELECT * 它不香吗?
在这里顺便补充一下为什么要禁止 SELECT *。难道简单无脑,它不香吗?
主要两点:
- 用 “SELECT * ” 数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
- 增大网络开销,* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。特别是MySQL和应用程序不在同一台机器,这种开销非常明显。
结束
最后还是希望大家自己去实操一下,肯定还可以收获更多!
面试官:MySQL一千万数据,怎么快速查询?的更多相关文章
- mysql处理大数据量的查询速度究竟有多快和能优化到什么程度
mysql处理大数据量的查询速度究竟有多快和能优化到什么程度 深圳-ftx(1433725026) 18:10:49 mysql有没有排名函数啊 横瓜(601069289) 18:13:06 无 ...
- 搞定面试官 - MySQL 中你知道如何计算一个索引的长度嘛?
大家好,我是程序员啊粥. 今天给大家分享一个我遇到过的比较少见的面试题,那就是 MySQL 中如何计算一个索引的长度. 说实话,我第一次遇到这个问题的时候想当然的以为索引长度就是我们建表时定义的字段长 ...
- C API向MySQL插入批量数据的快速方法——关于mysql_autocommit
MySQL默认的数据提交操作模式是自动提交模式(autocommit).这就表示除非显式地开始一个事务,否则每个查询都被当做一个单独的事务自动执行.我们可以通过设置autocommit的值改变是否是自 ...
- mysql的大数据量的查询
mysql的大数据量查询分页应该用where 条件进行分页,limit 100000,100,mysql先查询100100数据量,查询完以后,将 这些100000数据量屏蔽去掉,用100的量,但是如果 ...
- 数据库入门(mySQL):数据操作与查询
增删改 单表查询 多表查询 一.增删改 1.插入数据记录(增) insert into table_name(field1,field2,field3,...fieldn) valuses(value ...
- 记录一次MySQL两千万数据的大表优化解决过程,提供三种解决方案(转)
问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡死.严重影响业务 ...
- 一次MySQL两千万数据大表的优化过程,三种解决方案
问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡死.严重影响业务 ...
- Mysql学习总结(35)——Mysql两千万数据优化及迁移
最近有一张2000W条记录的数据表需要优化和迁移.2000W数据对于MySQL来说很尴尬,因为合理的创建索引速度还是挺快的,再怎么优化速度也得不到多大提升.不过这些数据有大量的冗余字段和错误信息,极不 ...
- MYSQL插入千万数据的工具类
建表语句 CREATE TABLE `test_id` ( `id` int(10) NOT NULL AUTO_INCREMENT COMMENT '主键自增非空', `name` varchar( ...
- 转载:记录一次MySQL两千万数据的大表优化解决过程
地址:https://database.51cto.com/art/201902/592522.htm 虽然是广告文,但整体可读性尚可.
随机推荐
- 23年用vuex进行状态管理out了,都开始用pinia啦!
1 Vue2项目中,Vuex状态管理工具,几乎可以说是必不可少的了.而在Vu3中,尤大大推荐我们使用pinia(拍你啊)进行状态管理,咱得听话,用就完了. 使用之前我们来看一下,使用 pinia 给我 ...
- SOJ1728 题解
题意 有一个长度为 \(n\) 的数列 \(a_0,a_1,\dots,a_{n-1}\) 以及一个长度为 \(m\) 的操作序列 \((b_0,c_0),(b_1,c_1)\dots(b_{m-1} ...
- mfc拷贝到我的电脑出现的问题
拿到工程解压打开,霍,挺好 往下面翻了翻看到了这个 再怎么错误,怎么会没有string呢?看了看头文件,包含的有,所以 我去找了一下string.h的位置 项目->属性->VC++目录-& ...
- emacs config on win10 for rust 1
native win32 (setq package-archives '(("gnu" . "http://mirrors.ustc.edu.cn/elpa/gnu/& ...
- perlist
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5 < ...
- 时间序列分析 2.X 单位根检验
单位根检验 (基于模型检验序列是否平稳) 趋势平稳序列 \(X_{t}=\beta_{0}+\beta_{1} t+Y_{t}\) \(Y_t\) 为平稳序列, 则称 \(X_t\) 为趋势平稳序列 ...
- c++练习270题:三角形个数
*270题 原题传送门:http://oj.tfls.net/p/270 题解: #include<bits/stdc++.h>using namespace std;int a,b,c, ...
- PHP常见方法封装
1.get请求 function get_curl($url, $timeout = 5) { $ch = curl_init(); curl_setopt($ch,CURLOPT_URL,$url) ...
- vue项目使用vue-amap调用高德地图api详细步骤
想要的效果如下 : 高德地图 && 信息窗体 步骤一: 申请高德key 高德开放平台 | 高德地图API (amap.com) (可参考博客: [996]如何申请高德地图用户Key ...
- jenkins目录
Jenkins目录详解: jobs目录:创建的所有jenkins工程.并含有所有构建历史记录和日志.其中config.xml为具体配置. plugins:所有插件 workspace:构建工程本机源码 ...