Python爬取全球是最大的电影数据库网站IMDb数据
在使用 Python 开发爬虫的过程中,requests 和 BeautifulSoup4(别名bs4) 应用的比较广泛,requests主要用于模拟浏览器的客户端请求,以获取服务器端响应,接收到的响应结果,如:网页HTML源码则交由 bs4 封装后再解析提取目标内容数据。
今天的案例中,我们将使用一个新库 MechanicalSoup 该库事实上是对 requests 和 bs4 的进一步封装,让请求和解析的工作进一步简化,如果你已经熟悉 requests 和 bs4 的基本操作,下面的代码理解起来应该不会很困难。
准备工作 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
mechanicalsoup 安装
终端下使用 pip 安装即可,也会自动安装相关依赖组件库
pip install mechanicalsoup网页分析 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
今天我们要请求的是全球是最大的电影数据库网站 IMDb,其官网地址是 http://www.imdb.com 首页显示效果如图所示:
我们要爬取数据的页面,可以通过“Menu“ 导航的子菜单项 "Top Rated Movies" 进入,或直接访问 https://www.imdb.com/chart/top/
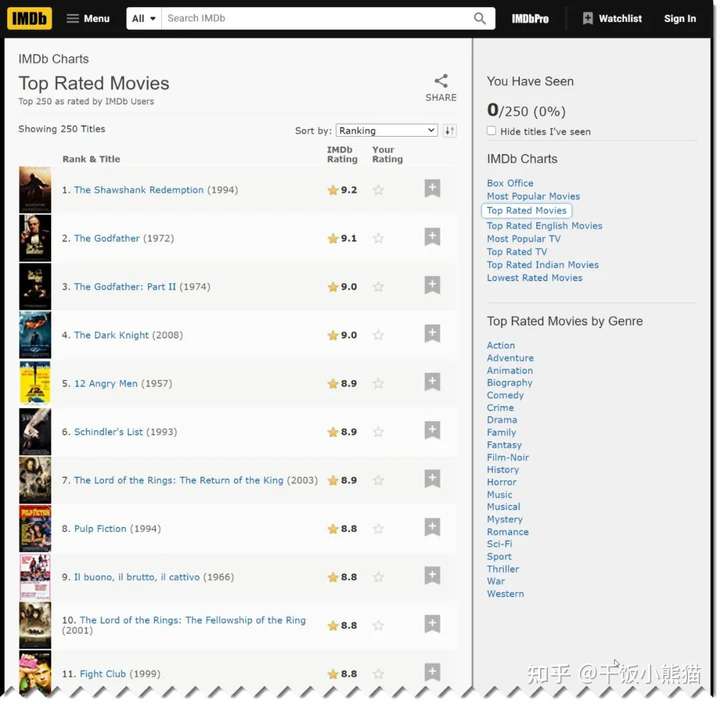
我们要采集的目标数据为左侧页面的列表,经过浏览器右键“检查”分析,得知第一条数据项均包含在一个表格行内,此时我们进一步明确要采集的数据为排名、电影标题、发行年份三列,分析得到以下HTML元素:
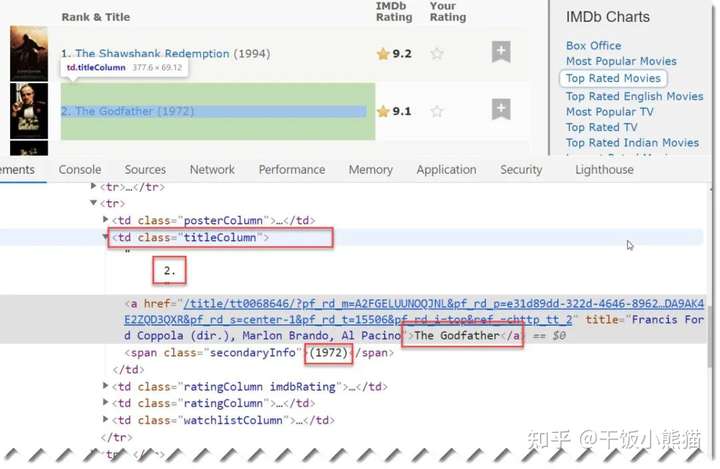
目标数据均包含在一个td class="titleColumn" 单元格内,此时只需要批量获取有该特征的批量单元格,再取出目标数据并清理即可。
编码实现 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
采集并打印
初步代码结构:
imdb.py
python答疑 咨询 学习交流群2:660193417###
import mechanical
# 数据容器
data = []
def fetch_data():
# 此处爬取页面目标数据
def main():
fetch_data()
if __name__ == "__main__":
main()重点的代码逻辑是包含在 fetch_data() 函数内,具体代码如下(含注释):
python答疑 咨询 学习交流群2:660193417###
def fetch_data():
url = "https://www.imdb.com/chart/top/"
# 构造浏览器对象
b = mechanicalsoup.StatefulBrowser()
# 请求目标网址
b.open(url)
# b.page 即为当前响应页面源码,且已封装为 BeautifulSoup 对象
# 页面中找出所有具有 class="titleColumn" 属性的 td 单元格集合
items = b.page.find_all("td", class_="titleColumn")
# 遍历所有项
for item in items:
# 取出当前单元格中所所有文本,以"\n"分隔为三个元素
row = item.text.strip().split("\n")
# 进一步清理元素值的空格
# 此时列表中三个元素对应为排名、标题、年份
row = [x.strip() for x in row]
# 将数据添加至data列表容器,便于进一步处理
data.append(row)
# 打印显示
print(row)此时代码如下:
python答疑 咨询 学习交流群2:660193417###
import mechanicalsoup
data = []
def fetch_data():
url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250"
b = mechanicalsoup.StatefulBrowser()
b.open(url)
items = b.page.find_all("td", class_="titleColumn")
for item in items:
row = item.text.strip().split("\n")
row = [x.strip() for x in row]
data.append(row)
print(row)
def main():
fetch_data()
if __name__ == "__main__":
main()此时运行代码 python imdb.py 结果如下:
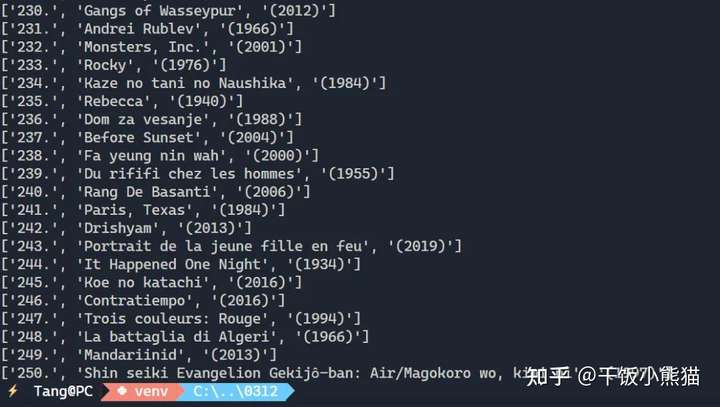
可以看到在逐行提取时打印的效果,此时数据窗口 data 中也包括了所有行250行的电影信息。
将批量数据写入Excel文件 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
如果将采集的批量电影数据(250条)一次性写入Excel 表格文件,可以安装使用 Excel 操作库,比如:openpyxl 等,在执行完前述步骤 fetch_data() 执行新建、并写入Excel 操作即可。
Python爬取全球是最大的电影数据库网站IMDb数据的更多相关文章
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- Python爬取中国票房网所有电影片名和演员名字,爬取齐鲁网大陆所有电视剧名称
爬取CBO中国票房网所有电影片名和演员名字 # -*- coding: utf-8 -*- # 爬取CBO中国票房网所有电影片名 import json import requests import ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 2019-03-20 Python爬取需要登录的有验证码的网站
当你向验证码发起请求的时候,就有session了,记录下这次session 因为每当你请求一次验证码 或者 请求一次登录首页,验证码都在变动 验证码的链接可能不是固定的,可能需要GET/POST请求, ...
- python爬取连续一字板股票及当时日期数据【原创分享】
本篇为个人测试记录,记录爬取连续一字板的股票及当时日期. import tushare as ts import pandas as pd import time # 筛选一字板的策略 def gp_ ...
- python爬取(自动化)豆瓣电影影评,并存储。
from selenium import webdriverfrom selenium.webdriver import ActionChainsimport time driver = webdri ...
- Python爬取全球疫情数据,实现可视化显示地图数据(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 武汉地区,目前已经实现住院患者清零了,国内疫情已经稳定,然而中国以外新冠确 ...
- python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图: 我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库. 因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
随机推荐
- 在vue项目中配置webpack
首先我们来看一下使用Vue-cli2与Vue-cli2之后的版本(这里以Vue-cli4版本为例)创建项目目录结构的不同: Vue-cli2(左图)与Vue-cli4(右图)创建项目的目录 从上图可以 ...
- 【Azure 环境】使用Microsoft Graph PS SDK 登录到中国区Azure, 命令Connect-MgGraph -Environment China xxxxxxxxx 遇见登录错误
问题描述 通过PowerShell 连接到Microsoft Graph 中国区Azure,一直出现AADSTS700016错误, 消息显示 the specific application was ...
- 通过 SingleFlight 模式学习 Go 并发编程
最近接触到微服务框架go-zero,翻看了整个框架代码,发现结构清晰.代码简洁,所以决定阅读源码学习下,本次阅读的源码位于core/syncx/singleflight.go. 在go-zero中Si ...
- python基础-基本数据类型(三)
一.散列类型 散列类型用来表示无序的集合类型 1.集合(set) Python中的集合与数学符号中的集合类似,都是用来表示无序不重复元素的集合. 1.1 集合的定义 集合使用一对{}来进行定义,集合中 ...
- Bugku CTF练习题---MISC---宽带信息泄露
Bugku CTF练习题---MISC---宽带信息泄露 flag:053700357621 解题步骤: 1.观察题目,下载附件 2.下载到电脑里发现是一个bin文件,二进制文件的一个种类,再看名称为 ...
- Nacos在企业生产中如何使用集群环境?
点赞再看,养成习惯,微信搜索[牧小农]关注我获取更多资讯,风里雨里,小农等你,很高兴能够成为你的朋友. 项目源码地址:公众号回复 nacos,即可免费获取源码 前言 由于在公司,注册中心和配置中心都是 ...
- ONNXRuntime学习笔记(一)
一. DL模型落地步骤 一般情况下,一个DL任务落地的流程一般包含训练和部署两大部分,具体细分我认为可以分为以下几个步骤: 1. 明确任务目标:首先要明确我们最终要达到一个什么样的效果,假设我们的DL ...
- 利用expect批量修改Linux服务器密码
一个执着于技术的公众号 背景 修改Linux系统密码,执行passwd即可更改密码.可如果有成千上百台服务器呢,通过ssh的方式逐一进行修改,对我们来说,工作量是非常大,且效率非常低下.因此采用批量修 ...
- Masa Blazor自定义组件封装
前言 实际项目中总能遇到一个"组件"不是基础组件但是又会频繁复用的情况,在开发MASA Auth时也封装了几个组件.既有简单定义CSS样式和界面封装的组件(GroupBox),也有 ...
- Redis设计与实现3.3:集群
集群 这是<Redis设计与实现>系列的文章,系列导航:Redis设计与实现笔记 集群中的节点 创建集群 通过 CLUSTER NODE 命令可以查看当前集群中的节点.刚启动时,默认每一台 ...