Python爬取全球是最大的电影数据库网站IMDb数据
在使用 Python 开发爬虫的过程中,requests 和 BeautifulSoup4(别名bs4) 应用的比较广泛,requests主要用于模拟浏览器的客户端请求,以获取服务器端响应,接收到的响应结果,如:网页HTML源码则交由 bs4 封装后再解析提取目标内容数据。
今天的案例中,我们将使用一个新库 MechanicalSoup 该库事实上是对 requests 和 bs4 的进一步封装,让请求和解析的工作进一步简化,如果你已经熟悉 requests 和 bs4 的基本操作,下面的代码理解起来应该不会很困难。
准备工作 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
mechanicalsoup 安装
终端下使用 pip 安装即可,也会自动安装相关依赖组件库
pip install mechanicalsoup网页分析 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
今天我们要请求的是全球是最大的电影数据库网站 IMDb,其官网地址是 http://www.imdb.com 首页显示效果如图所示:
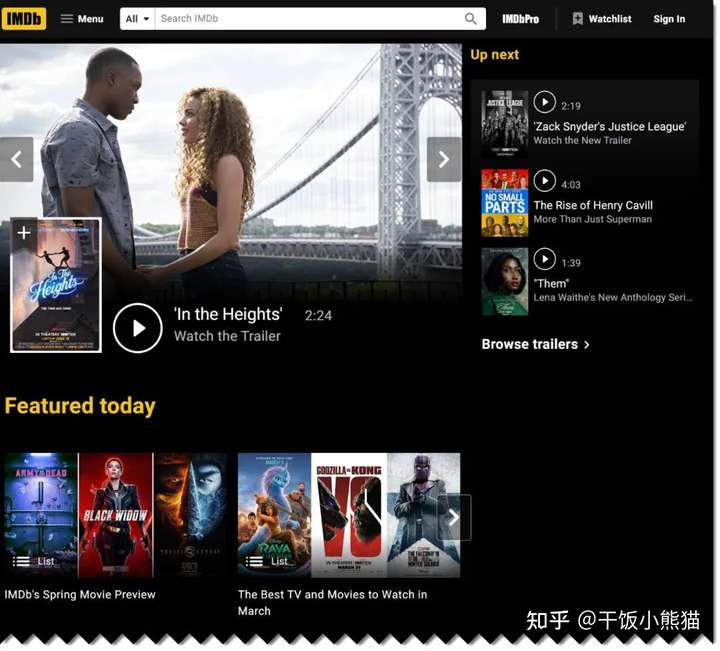
我们要爬取数据的页面,可以通过“Menu“ 导航的子菜单项 "Top Rated Movies" 进入,或直接访问 https://www.imdb.com/chart/top/
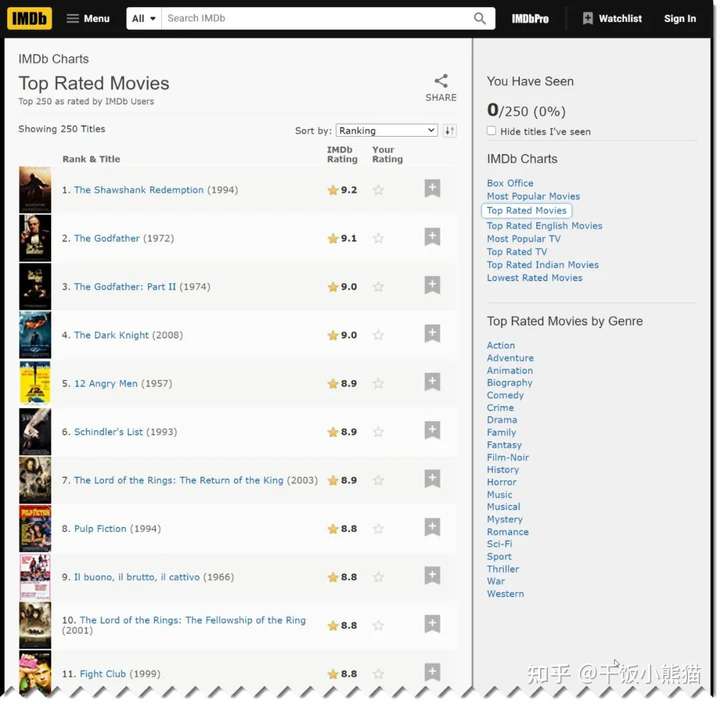
我们要采集的目标数据为左侧页面的列表,经过浏览器右键“检查”分析,得知第一条数据项均包含在一个表格行内,此时我们进一步明确要采集的数据为排名、电影标题、发行年份三列,分析得到以下HTML元素:
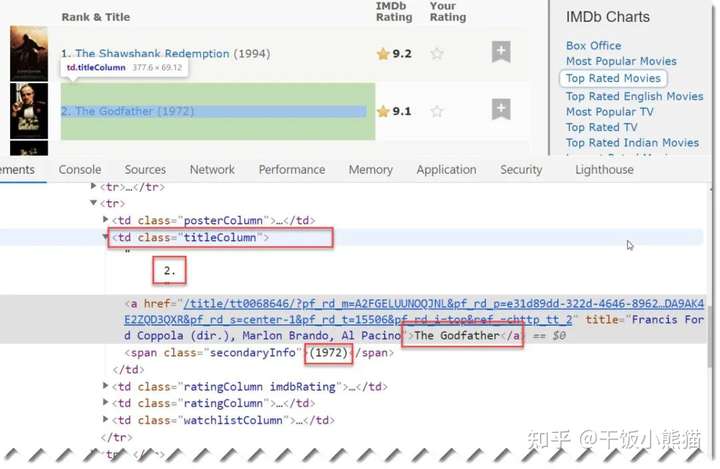
目标数据均包含在一个td class="titleColumn" 单元格内,此时只需要批量获取有该特征的批量单元格,再取出目标数据并清理即可。
编码实现 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
采集并打印
初步代码结构:
imdb.py
python答疑 咨询 学习交流群2:660193417###
import mechanical
# 数据容器
data = []
def fetch_data():
# 此处爬取页面目标数据
def main():
fetch_data()
if __name__ == "__main__":
main()重点的代码逻辑是包含在 fetch_data() 函数内,具体代码如下(含注释):
python答疑 咨询 学习交流群2:660193417###
def fetch_data():
url = "https://www.imdb.com/chart/top/"
# 构造浏览器对象
b = mechanicalsoup.StatefulBrowser()
# 请求目标网址
b.open(url)
# b.page 即为当前响应页面源码,且已封装为 BeautifulSoup 对象
# 页面中找出所有具有 class="titleColumn" 属性的 td 单元格集合
items = b.page.find_all("td", class_="titleColumn")
# 遍历所有项
for item in items:
# 取出当前单元格中所所有文本,以"\n"分隔为三个元素
row = item.text.strip().split("\n")
# 进一步清理元素值的空格
# 此时列表中三个元素对应为排名、标题、年份
row = [x.strip() for x in row]
# 将数据添加至data列表容器,便于进一步处理
data.append(row)
# 打印显示
print(row)此时代码如下:
python答疑 咨询 学习交流群2:660193417###
import mechanicalsoup
data = []
def fetch_data():
url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250"
b = mechanicalsoup.StatefulBrowser()
b.open(url)
items = b.page.find_all("td", class_="titleColumn")
for item in items:
row = item.text.strip().split("\n")
row = [x.strip() for x in row]
data.append(row)
print(row)
def main():
fetch_data()
if __name__ == "__main__":
main()此时运行代码 python imdb.py 结果如下:
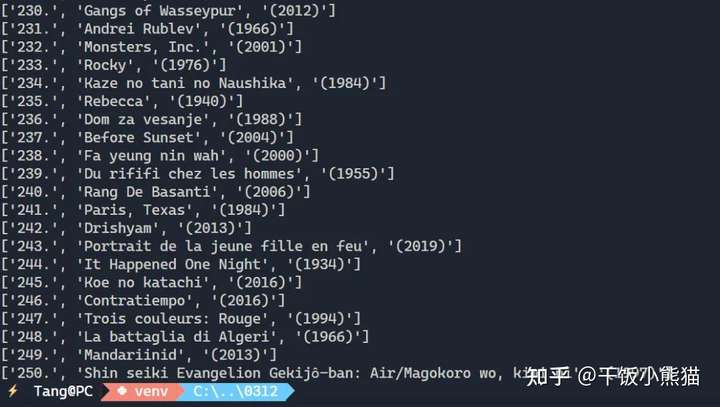
可以看到在逐行提取时打印的效果,此时数据窗口 data 中也包括了所有行250行的电影信息。
将批量数据写入Excel文件 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
如果将采集的批量电影数据(250条)一次性写入Excel 表格文件,可以安装使用 Excel 操作库,比如:openpyxl 等,在执行完前述步骤 fetch_data() 执行新建、并写入Excel 操作即可。
Python爬取全球是最大的电影数据库网站IMDb数据的更多相关文章
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- Python爬取中国票房网所有电影片名和演员名字,爬取齐鲁网大陆所有电视剧名称
爬取CBO中国票房网所有电影片名和演员名字 # -*- coding: utf-8 -*- # 爬取CBO中国票房网所有电影片名 import json import requests import ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 2019-03-20 Python爬取需要登录的有验证码的网站
当你向验证码发起请求的时候,就有session了,记录下这次session 因为每当你请求一次验证码 或者 请求一次登录首页,验证码都在变动 验证码的链接可能不是固定的,可能需要GET/POST请求, ...
- python爬取连续一字板股票及当时日期数据【原创分享】
本篇为个人测试记录,记录爬取连续一字板的股票及当时日期. import tushare as ts import pandas as pd import time # 筛选一字板的策略 def gp_ ...
- python爬取(自动化)豆瓣电影影评,并存储。
from selenium import webdriverfrom selenium.webdriver import ActionChainsimport time driver = webdri ...
- Python爬取全球疫情数据,实现可视化显示地图数据(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 武汉地区,目前已经实现住院患者清零了,国内疫情已经稳定,然而中国以外新冠确 ...
- python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图: 我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库. 因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
随机推荐
- npm 报错This is probably not a problem with npm. There is likely additional logging output above.
报错This is probably not a problem with npm. There is likely additional logging output above. 安装了一个插件后 ...
- 新手小白入门C语言第六章:C运算符
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号.C 语言内置了丰富的运算符,并提供了以下类型的运算符: 算术运算符 关系运算符 逻辑运算符 位运算符 赋值运算符 杂项运算符 小编将会为大家逐一介 ...
- ES Bridge跨链桥服务升级,新增BSC跨链网络
3月15日,Equal Sign Bridge(ES Bridge)跨链桥宣布新增BSC跨链网络,方便更多用户参与到ES Bridge的建设与发展,未来还将持续拓展更多的主流跨链币种,提升各链间的互操 ...
- Java语言学习day31--8月06日
今日内容介绍1.正则表达式的定义及使用2.Date类的用法3.Calendar类的用法 ###01正则表达式的概念和作用 * A: 正则表达式的概念和作用 * a: 正则表达式的概述 * 正则表达式也 ...
- 震惊!<string.h>、<cstring>和<string>竟然可以这么用!
为什么有这么多string相关的头文件呢,小编秦始皇今天带大家看一下: 1.[string.h] 定义如下:"C语言标准库中一个常用的头文件,在使用到字符数组时需要使用.[strin ...
- 攻防世界-MISC:掀桌子
这是攻防世界新手练习区的第八题,题目如下: 就给了一串16进制的字符串.哎,又是不懂,看了一下官方WP,说是将每两位16进制数转换为10进制,再减去128再转换为ASCII码.直接上脚本 str1 = ...
- XCTF练习题---MISC---Hidden-Message
XCTF练习题---MISC---Hidden-Message flag:Heisenberg 解题步骤: 1.观察题目,下载附件 2.拿到手以后发现是一个数据包格式,打开看一下 3.查看UDP流,并 ...
- 【CSAPP】Attack Lab实验笔记
attacklab这节玩的是利用一个字符串进行缓冲区溢出漏洞攻击,就小时候想象中黑客干的事儿. 做题的时候好几次感叹这些人的脑洞,"这都可以攻击?还能这么注入?这还可能借力打力?" ...
- Linux文本工具-cat-cut-paste;文本分析-sort-wc-uniq
1.1 查看文本文件内容 cat 1.1.1 cat可以查看文本内容 cat [OPTION]... [FILE]... 常见选项 -E: 显示行结束符$ -A: 显示所有控制符 -n: 对显示出的 ...
- 北航内核操作系统-lab1
1.实验目的. 2.实验内容. 2.1Exercise 1.1 请修改 include.mk 文件,使交叉编译器的路径正确.之后执行 make指令,如果配置一切正确,则会在gxemul 目录下生成v ...