Python第一个爬虫学习
在网上查看大神的关于Python爬虫的文章,代码如下:
#coding=utf-8
import urllib
import re def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
以下则是在运行上述代码过程中遇到的相关问题,以及解决方式,虽然不怎么高级,但是也算是一种学习思路吧。
问题1:在Python3.2的环境下,未运行时,代码会报错:
解决1:将
print getImg(html)
修改为
print (getImg(html))
问题2:代码执行后,报如下错误:
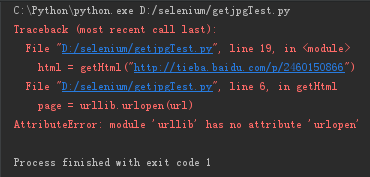
解决2:度娘进行搜索,才发现3.2不兼容2.0的,于是进入官方文档查找最新的调用方式,对这三行进行以下修改,修改前:
import urllib
page = urllib.urlopen(url)
urllib.urlretrieve(imgurl,'%s.jpg' % x)
修改后:
import urllib.request
page = urllib.request.urlopen(url)
urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
问题3:运行代码,提示以下错误:
C:\Python\python.exe D:/selenium/getjpgTest.py
Traceback (most recent call last):
File "D:/selenium/getjpgTest.py", line 20, in <module>
print (getImg(html))
File "D:/selenium/getjpgTest.py", line 13, in getImg
imglist = re.findall(imgre,html)
File "C:\Python\lib\re.py", line 213, in findall
return _compile(pattern, flags).findall(string)
TypeError: cannot use a string pattern on a bytes-like object
Process finished with exit code 1
解决3:百度之后,很容易得到答案,加上下面一句代码即可解决:
html=html.decode('utf-8')
最终得到以下代码:
#coding=utf-8
import urllib.request
import re def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
html = html.decode('utf-8')
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866")
print (getImg(html))
执行结果如下:
参考文章:1、http://www.cnblogs.com/fnng/p/3576154.html
2、http://blog.csdn.net/lxh199603/article/details/53192883
Python第一个爬虫学习的更多相关文章
- Python 简单网页爬虫学习
#coding=utf-8 # 参考文章: # 1. python实现简单爬虫功能 # http://www.cnblogs.com/fnng/p/3576154.html # 2. Python 2 ...
- python第一个爬虫的例子抓取数据到mysql,实测有数据
python3.5 先安装库或者扩展 1 requests第三方扩展库 pip3 install requests 2 pymysql pip3 install pymysql 3 lxml pip3 ...
- Python爬虫学习第一记 (翻译小助手)
1 # Python爬虫学习第一记 8.24 (代码有点小,请放大看吧) 2 3 #实现有道翻译,模块一: $fanyi.py 4 5 import urllib.request 6 import u ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python项目之我的第一个爬虫----爬取豆瓣图书网,统计图书数量
今天,花了一个晚上的时间边学边做,搞出了我的第一个爬虫.学习Python有两个月了,期间断断续续,但是始终放弃,今天搞了一个小项目,有种丰收的喜悦.废话不说了,直接附上我的全部代码. # -*- co ...
- python爬虫__第一个爬虫程序
前言 机缘巧合,最近在学习机器学习实战, 本来要用python来做实验和开发环境 得到一个需求,要爬取大众点评中的一些商户信息, 于是开启了我的第一个爬虫的编写,里面有好多心酸,主要是第一次. 我的文 ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- asp.net 动态添加多个用户控件
动态添加多个相同用户控件,并使每个用户控件获取不同的内容. 用户控件代码: 代码WebControls using System; using System.Collections.Generic; ...
- python3----输出所有大小写字母及数字
1. 用一行输出所有大(小)写字母,以及数字 print([chr(i) for i in range(65, 91)]) # 所有大写字母 print([chr(i) for i in range( ...
- Using XSLT and Open XML to Create a Word 2007 Document
Summary: Learn how to transform XML data into a Word 2007 document by starting with an existing docu ...
- php求数学对数
php的对数函数并不是很强大 有自然对数 有10的对数的函数,不过没有自定义底的对数函数,所以自己写了一个 <?php function xsqrt($x, $value) { $count = ...
- 第一个内核模块hello world
1.源码树的下载和编译(只是研究内核模块的话,应该不需要源码树的) 下载很简单,压缩包解压 编译:make menuconfig make bzImage -j4 参考 2. cd /usr/src ...
- Myeclipse下使用Maven搭建spring boot项目
开发环境:Myeclipse2017.JDK1.6.Tomcat 8.0.Myeclipse下使用Maven搭建spring boot项目,详细过程如下: 1. New -> Project.. ...
- poj_2559 单调栈
题目大意 给出一个柱形图中柱子的高度,每个柱子的宽度为1,柱子相邻.求出柱形图中可能形成的矩形的最大面积. 题目分析 以每个柱子(高度为h[i])为中心,向两边延展求出以该h[i]为高度的矩形的最大宽 ...
- c#基础 第六讲
烧开水 先询问:“是否要烧开水(Y/N)” 是的话执行--0°--100°(30°---水温了,50°---水热了,80°---水快开了,100°---水已经开了, 结束.) 判断 循环 选择 跳转 ...
- 【BZOJ4598】[Sdoi2016]模式字符串 树分治+hash
[BZOJ4598][Sdoi2016]模式字符串 Description 给出n个结点的树结构T,其中每一个结点上有一个字符,这里我们所说的字符只考虑大写字母A到Z,再给出长度为m的模式串s,其中每 ...
- 【BZOJ1895】Pku3580 supermemo Splay
[BZOJ1895]Pku3580 supermemo Description 给出一个初始序列fA1;A2;:::Ang,要求你编写程序支持如下操作: 1. ADDxyD:给子序列fAx:::Ayg ...