Python爬虫实例(二)使用selenium抓取斗鱼直播平台数据
程序说明:抓取斗鱼直播平台的直播房间号及其观众人数,最后统计出某一时刻的总直播人数和总观众人数。
过程分析:
一、进入斗鱼首页http://www.douyu.com/directory/all
进入平台首页,来到页面底部点击下一页,发现url地址没有发生变化,这样的话再使用urllib2发送请求将获取不到完整数据,这时我们可以使用selenium和PhantomJS来模拟浏览器点击下一页,这样就可以获取完整响应数据了。
首先检查下一页元素,如下:
<a href="#" class="shark-pager-next">下一页</a>
使用selenium和PhantomJS模拟点击,代码如下:
from selenium import webdriver
# 使用PhantomJS浏览器创建浏览器对象
driver = webdriver.PhantomJS()
# 使用get方法加载页面
driver.get("https://www.douyu.com/directory/all")
# class="shark-pager-next"是下一页按钮,click() 是模拟点击
driver.find_element_by_class_name("shark-pager-next").click()
# 打印页面页面查看
print driver.page_source
这样就可以通过设置一个循环条件,一直点击下去,直到页面加载完。循环终止的条件为最后一页,进入最后一页,检查下一页元素:
<a href="#" class="shark-pager-next shark-pager-disable shark-pager-disable-next">下一页</a>
对比发现:当出现"shark-pager-disable-next",下一页无法点击,这就是循环停止的条件。
# 如果在页面源码里没有找到"shark-pager-disable-next",其返回值为-1,可依次作为判断条件
driver.page_source.find("shark-pager-disable-next")
二,对要提取的内容进行分析
查看直播房间名称的元素,得到如下结果:
<span class="dy-name ellipsis fl">AI冬Ming</span>
使用BeatuifulSoup获取元素,代码如下:
# 房间名
names = soup.find_all("span", {"class" : "dy-name ellipsis fl"})
查看观看人数的元素,得到如下结果:
<span class="dy-num fr">75.6万</span>
使用BeatuifulSoup获取元素,代码如下:
# 观众人数
numbers = soup.find_all("span", {"class" :"dy-num fr"})
具体过程大概如此,下面是完整代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*- from selenium import webdriver
from bs4 import BeautifulSoup as bs
import sys
reload(sys)
sys.setdefaultencoding("utf-8") class Douyu(): def __init__(self):
self.driver = webdriver.PhantomJS()
self.num = 0
self.count = 0 def douyuSpider(self):
self.driver.get("https://www.douyu.com/directory/all")
while True:
soup = bs(self.driver.page_source, "lxml")
# 房间名, 返回列表
names = soup.find_all("span", {"class" : "dy-name ellipsis fl"})
# 观众人数, 返回列表
numbers = soup.find_all("span", {"class" :"dy-num fr"}) for name, number in zip(names, numbers):
print u"观众人数: -" + number.get_text().strip() + u"-\t房间名: " + name.get_text().strip()
self.num += 1
count = number.get_text().strip()
if count[-1]=="万":
countNum = float(count[:-1])*10000
else:
countNum = float(count)
self.count += countNum # 一直点击下一页
self.driver.find_element_by_class_name("shark-pager-next").click()
# 如果在页面源码里找到"下一页"为隐藏的标签,就退出循环
if self.driver.page_source.find("shark-pager-disable-next") != -1:
break print "当前网站直播人数:%s" % self.num
print "当前网站观众人数:%s" % self.count if __name__ == "__main__":
d = Douyu()
d.douyuSpider()
运行结果(部分展示):
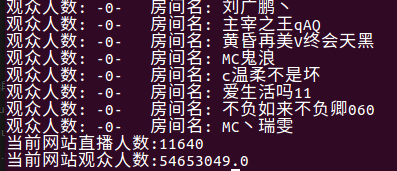
Python爬虫实例(二)使用selenium抓取斗鱼直播平台数据的更多相关文章
- Python爬虫实战:使用Selenium抓取QQ空间好友说说
前面我们接触到的,都是使用requests+BeautifulSoup组合对静态网页进行请求和数据解析,若是JS生成的内容,也介绍了通过寻找API借口来获取数据. 但是有的时候,网页数据由JS生成,A ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
- Python爬虫入门教程 46-100 Charles抓取手机收音机-手机APP爬虫部分
1. 手机收音机-爬前叨叨 今天选了一下,咱盘哪个APP呢,原计划是弄荔枝APP,结果发现竟然没有抓到数据,很遗憾,只能找个没那么圆润的了.搜了一下,找到一个手机收音机 下载量也是不错的. 2. 爬虫 ...
- Python爬虫入门教程 45-100 Charles抓取兔儿故事-下载小猪佩奇故事-手机APP爬虫部分
1. Charles抓取兔儿故事背景介绍 之前已经安装了Charles,接下来我将用两篇博客简单写一下关于Charles的使用,今天抓取一下兔儿故事里面关于小猪佩奇的故事. 爬虫编写起来核心的重点是分 ...
- Python 爬虫实例(8)—— 爬取 动态页面
今天使用python 和selenium爬取动态数据,主要是通过不停的更新页面,实现数据的爬取,要爬取的数据如下图 源代码: #-*-coding:utf-8-*- import time from ...
- PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)
利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB 目标站点分析 淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐.所以我们可 ...
- 使用Selenium模拟浏览器抓取斗鱼直播间信息
获取斗鱼直播间每个房间的名称.观看人数.tag.主播名字 代码: import time from multiprocessing import Pool from selenium import w ...
- Python 爬虫实例(15) 爬取 汽车之家(汽车授权经销商)
有人给我吹牛逼,说汽车之家反爬很厉害,我不服气,所以就爬取了一下这个网址. 本片博客的目的是重点的分析定向爬虫的过程,希望读者能学会爬虫的分析流程. 一:爬虫的目标: 打开汽车之家的链接:https: ...
随机推荐
- C++中常函数内部的this指针也是const类型的
代码中碰到一个奇怪的现象,在同样的函数中调用this指针,结果却有一个无法通过编译 // 读取连接信息 void ThirdWizardPage::ReadConnection() { QFile f ...
- SAP ECC6安装系列二:安装前的准备工作
原作者博客 http://www.cnblogs.com/Michael_z/ ======================================== 安装 Java 1,安装 Java, ...
- Golang 中操作 Mongo Update 的方法
Golang 和 MongoDB 中的 ISODate 时间交互问题 2018年02月27日 11:28:43 独一无二的小个性 阅读数:357 标签: GolangMongoDB时间交互时间转换 更 ...
- Latex之希腊字母表 花体字母 实数集
花体字母 \mathcal{x} 实数集字母 \mathbb{R} 转自:http://blog.csdn.net/lanchunhui/article/details/49819445 拉丁字母是2 ...
- 【BZOJ】1101: [POI2007]Zap(莫比乌斯+分块)
http://www.lydsy.com/JudgeOnline/problem.php?id=1101 无限膜拜数论和分块orz 首先莫比乌斯函数的一些性质可以看<初等数论>或<具 ...
- Think Python: How to Think Like a Computer Scientist
Think Python: How to Think Like a Computer Scientist:http://greenteapress.com/thinkpython/html/index ...
- nginx php文件上传的大小配置问题
- MathType怎么编辑双箭头
很多的数学相关工作者在写文章或论文的时候常常会用到数学公式编辑器.MathType就是一款深受大家欢迎的公式编辑器.很多的用户在使用过程中会用到双箭头符号来表示推理过程,但是怎么编辑又不知道,下面本教 ...
- js实现jquery的offset()
用过jQuery的offset()的同学都知道 offset().top或offset().left很方便地取得元素相对于整个页面的偏移. 而在js里,没有这样直接的方法,节点的属性offsetTop ...
- 配置使用TargetFrameworks输出多版本类库
1.类库右键 2.修改配置 修改前: <Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <Targe ...