Python 爬虫实例(8)—— 爬取 动态页面
今天使用python 和selenium爬取动态数据,主要是通过不停的更新页面,实现数据的爬取,要爬取的数据如下图
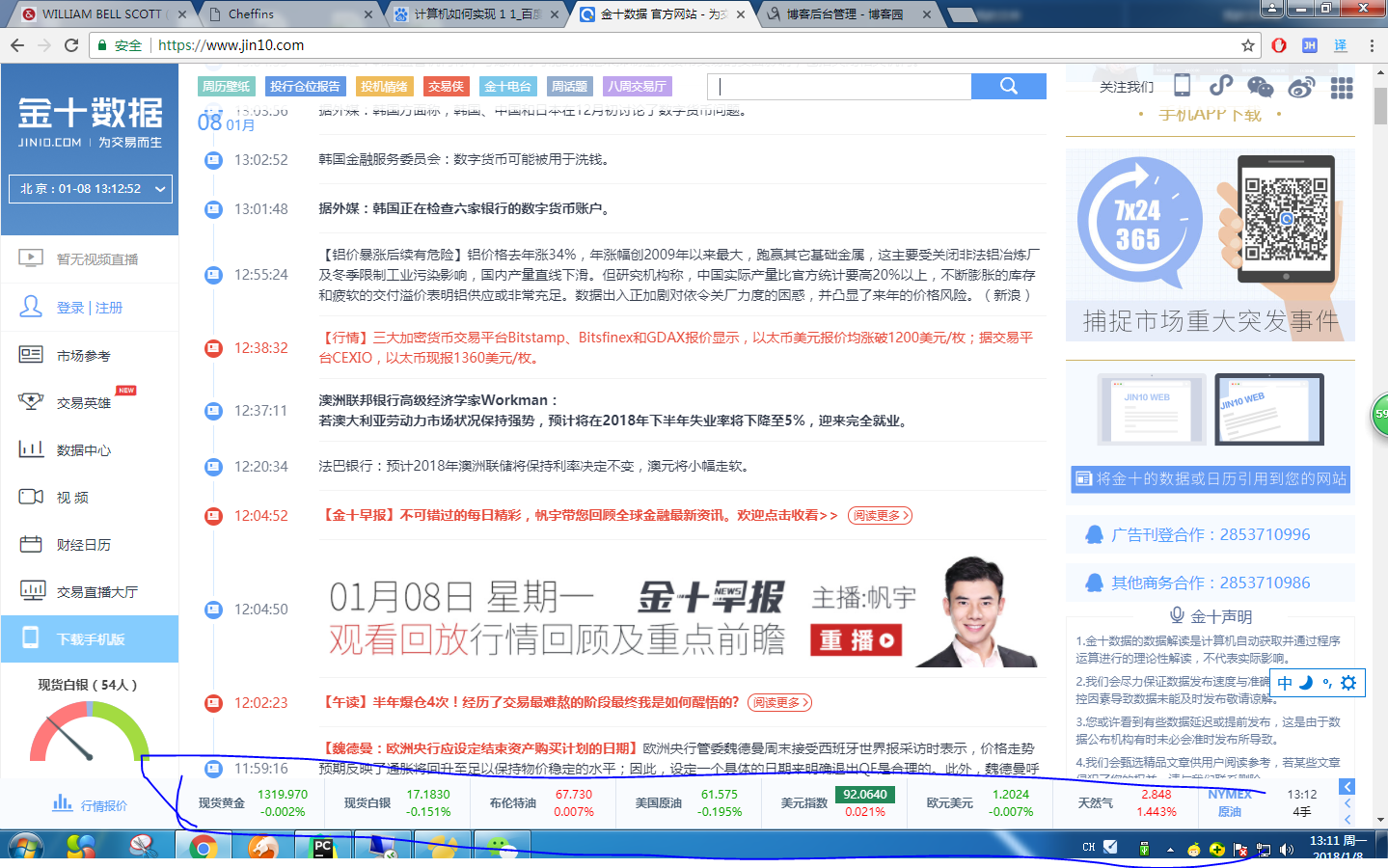
源代码:
#-*-coding:utf-8-*-
import time
from selenium import webdriver
import os
import re
#引入chromedriver.exe
chromedriver = "C:/Users/xuchunlin/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver) #设置浏览器需要打开的url
url = "https://www.jin10.com/"
# 使用for循环不停的刷新页面,也可以每隔一段时间刷新页面
for i in range(1,100000):
browser.get(url)
result= browser.page_source
gold_price = ""
gold_price_change = ""
try:
gold_price = re.findall('<div id="XAUUSD_B" class="jin-price_value" style=".*?">(.*?)</div>',result)[0]
gold_price_change = re.findall('<div id="XAUUSD_P" class="jin-price_value" style=".*?">(.*?)</div>',result)[0]
except:
gold_pric = "------"
gold_price_change = "------" print gold_price
print gold_price_change
time.sleep(1)
Python 爬虫实例(8)—— 爬取 动态页面的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
随机推荐
- HDU3339 In Action 【最短路】+【01背包】
<题目链接> 题目大意: 给出一个0-n组成的图,1-n的点上分布着值为pow的电站,给出图的m条边以及距离,从0出发到n个点中的x个点的行走距离和最小(因为是每炸一个点派出一辆坦克),且 ...
- Powershell极速教程-如何在三分钟内编写项目编译脚本
分析及思路 来看一下项目目录结构 炒鸡正常的三板斧src+docs+tests.咦,怎么会多出一个build的文件夹呢,这就是我们今天要研究的目录.今天我会带着大家在五分钟之内编写一个极简的编译脚本. ...
- spring boot整合servlet、filter、Listener等组件方式
创建一个maven项目,然后此项目继承一个父项目:org.springframework.boot 1.创建一个maven项目: 2.点击next后配置父项目及版本号 3.点击finish后就可查看p ...
- Linux学习笔记9
管道 pipe 如 : ls |less -MN 含义把ls 结果输出到less ls=|=more ls 命令 ls -a 展示隐藏的文件 隐藏文件一般以.开始 ls -t 以时间戳排序 ls - ...
- linux 学习笔记 groupadd创建组
1> groupadd -g test2 2>usermod -d /home/test -G test2 test 3>su user 4>groups 注意:root用户才 ...
- js发送邮件 不会调用客户端。
方式三:使用node中nodemail 首先需要安装node的环境,然后安装nodemailer: npm install nodemailer --save npm install nodemail ...
- DWM1000 定位数据收发以及定位算法
蓝点DWM1000 模块已经打样测试完毕,有兴趣的可以申请购买了,更多信息参见 蓝点论坛 正文: DWM1000 定位数据 官方定位程序,建议先学习基础API程序 参考手册: 在手册上提到,目前双向定 ...
- MySQL连接缓慢,打开缓慢原因
问题状况:最近由于服务器变换了网段,导致IP地址变换,变化后使用MySQL客户端连接MySQL服务器和在客户端中打开表的速度非常慢(无论表的大小),甚至连接超时,但是直接登录到服务器在本地连接MySQ ...
- 潭州课堂25班:Ph201805201 django框架 第六课 模型类增删改查,常用 的查询矣查询条件 (课堂笔记)
在视图函数中写入增删改查的方法 增: 在 urls 中配置路径 : 查: 1: 在后台打印数据 在模型类中添加格式化输出 : QuerySet,反回的是个对象,可以按索引聚会,用 for 循环,, 找 ...
- Wooden Sticks [POJ1065] [DP]
Description 有N根木棍等待处理.机器在处理第一根木棍时需要准备1分钟,此后遇到长宽都不大于前一根木棍的木棍就不需要时间准备,反之则需要1分钟重新准备.比如木棍按照(3,3).(1,3).( ...