Beautiful Soup解析网页
使用前步骤:
1.Beautiful Soup目前已经被移植到bs4,所以导入Beautiful Soup时先安装bs4库。
2.安装lxml库:如果不使用此库,就会使用Python默认的解析器,而lxml具有功能更加强大、速度更快的特点。
爬取:http://www.cntour.cn/
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import requests
from bs4 import BeautifulSoup
import re url="http://www.cntour.cn/" #需要爬取的网址
strhtml = requests.get(url); #使用GET方式,获取网页数据 soup = BeautifulSoup(strhtml.text,'lxml') #HTML文档将被转换成Unicode
# 编码格式,然后BeautifulSoup选择最适合的解析器来解析文档,此处指定
# lxml解析器,解析后转换成属性结构,每个节点都是Python对象,保存在变量soup中
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a') #采用select选择器定位数据
for item in data: #数据清洗和组织数据
result = {
'title':item.get_text(), #获得a标签的文本内内容
'link':item.get('href'), #获得a标签的href属性
'ID':re.findall('\d+',item.get('href')) #使用正则匹配其中的数字,\d匹配数字,+匹配一个字符一次或多次
}
print(result)
结果:
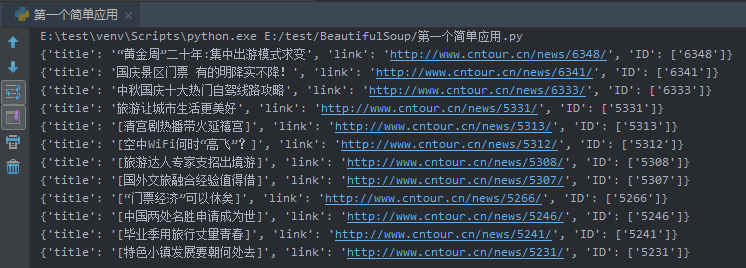
Beautiful Soup解析网页的更多相关文章
- Python Beautiful Soup 解析库的使用
Beautiful Soup 借助网页的结构和属性等特性来解析网页,这样就可以省去复杂的正则表达式的编写. Beautiful Soup是Python的一个HTML或XML的解析库. 1.解析器 解析 ...
- 爬虫5_python2_使用 Beautiful Soup 解析数据
使用 Beautiful Soup 解析数据(感谢东哥) 有的小伙伴们对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Beautiful Soup,有了它我们可以很方便地提取出HT ...
- Beautiful Soup解析库的安装和使用
Beautiful Soup是Python的一个HTML或XML的解析库,我们可以用它来方便地从网页中提取数据.它拥有强大的API和多样的解析方式.官方文档:https://www.crummy.co ...
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- 用Beautiful Soup解析html源码
#xiaodeng #python3 #用Beautiful Soup解析html源码 html_doc = """ <html> <head> ...
- Python爬虫系列(四):Beautiful Soup解析HTML之把HTML转成Python对象
在前几篇文章,我们学会了如何获取html文档内容,就是从url下载网页.今天开始,我们将讨论如何将html转成python对象,用python代码对文档进行分析. (牛小妹在学校折腾了好几天,也没把h ...
- 爬虫(五)—— 解析库(二)beautiful soup解析库
目录 解析库--beautiful soup 一.BeautifulSoup简介 二.安装模块 三.Beautiful Soup的基本使用 四.Beautiful Soup查找元素 1.查找文本.属性 ...
- Beautiful Soup 解析html表格
from bs4 import BeautifulSoup import urllib.request doc = urllib.request.urlopen('http://www.bkzy.or ...
- Python3编写网络爬虫06-基本解析库Beautiful Soup的使用
二.Beautiful Soup 简介 就是python的一个HTML或XML的解析库 可以用它来很方便的从网页中提取数据 0.1 提供一些简单的 python式的函数来处理导航,搜索,修改分析树等功 ...
随机推荐
- 15-I hate it (HDU1754:线段树)
http://acm.hdu.edu.cn/showproblem.php?pid=1754 相似例题: 敌兵布阵 http://www.cnblogs.com/zhumengdexiao ...
- Idea安装lombok插件及使用
安装lombok插件:File-settings 具体步骤如下图:1 2.找到Plugins 然后在搜索栏里搜索lombok 点击下放的Search in repositories 3.选中lombo ...
- 908G New Year and Original Order
传送门 分析 代码 #include<iostream> #include<cstdio> #include<cstring> #include<string ...
- 掌握所有IO口的外部中断
外部中断配置流程 1.初始化IO口工作在普通IO.上拉输入状态. 2.首先开IO口组中断(P0IE=1.P1IE=1.P2IE=1): 3.开组内对应的具体某IO口中断(P0IEN.P1IEN.P2I ...
- es学习-索引配置
1.创建一个新的索引并且添加一个配置 2.更新索引配置:(更新分词器为例子) 更新分词器前,一定要关闭索引,然后更新,最后再次开启索引 url:PUT http://127.0.0.1:9200/su ...
- C#中继承和构造函数
一个类继承自另外一个类,他们的构造函数改怎么办? 首先必须先声明:构造函数是不能继承的 我们先看一段代码:第一段代码没有构造函数,第二段有一个,第三段有两个.从他们的MSIL可以看出,有几个构造函数就 ...
- Cannot evaluate the property expression "$([MSBuild]::ValueOrDefault('$(VCTargetsPath)','$(MSBuildExtensionsPath32)\Microsoft.Cpp\v4.0\V140\'))" found at "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSBuil
Cannot evaluate the property expression "$([MSBuild]::ValueOrDefault('$(VCTargetsPath)','$(MSBu ...
- VC:GetWindowRect、GetClientRect、ScreenToClient与ClientToScreen
GetWindowRect是取得窗口在屏幕坐标系下的RECT坐标(包括客户区和非客户区),这样可以得到窗口的大小和相对屏幕左上角(0,0)的位置. GetClientRect取得窗口客户区(不包括非客 ...
- sudo -s/sodo -i/su root
sudo : 暂时切换到超级用户模式以执行超级用户权限,提示输入密码时该密码为当前用户的密码,而不是超级账户的密码.不过有时间限制,Ubuntu默认为一次时长15分钟.su : 切换到某某用户模式,提 ...
- EasyUI combobox动态增加选择项
有需求需要动态的为combobox增加可选项,后来解决方案如下 html如下 <select id="workerList"></select> js 如下 ...