hadoop2.6.0集群配置
1.修改机器名
集群的搭建最少需要三个节点,机器名分别修改为master,slave1,slave2。其中以master为主要操作系统。
修改hostname:
sudo gedit /etc/hostname
紧接着执行:
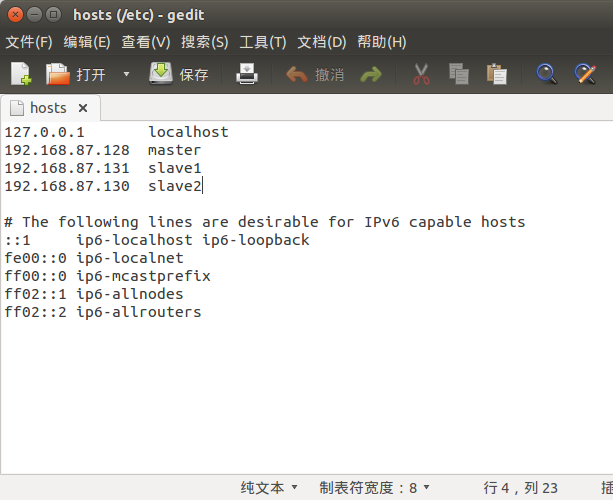
sudo gedit /etc/hosts
在hosts文件中更改原来的机器名为想要的,之后注销重新登陆,注销不成功就重启吧
现在验证是否更改成功,执行:
hostname
2.添加ip地址
查看本机ip,执行:
ifconfig
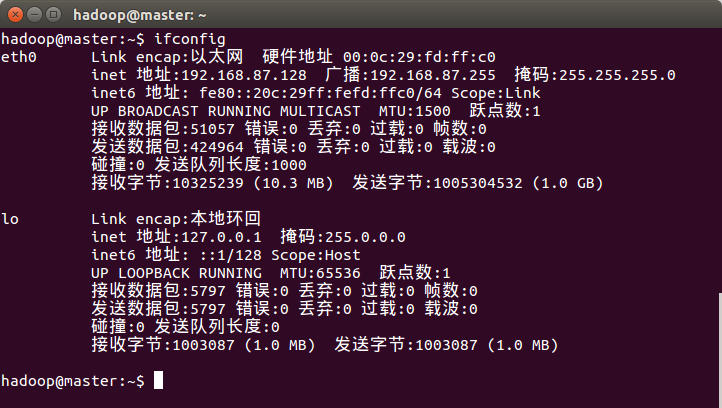
修改为静态ip后更方便记忆。每台机器在 etc/hosts 文件中添加所有机器(master、slave1和slave2)的ip地址。
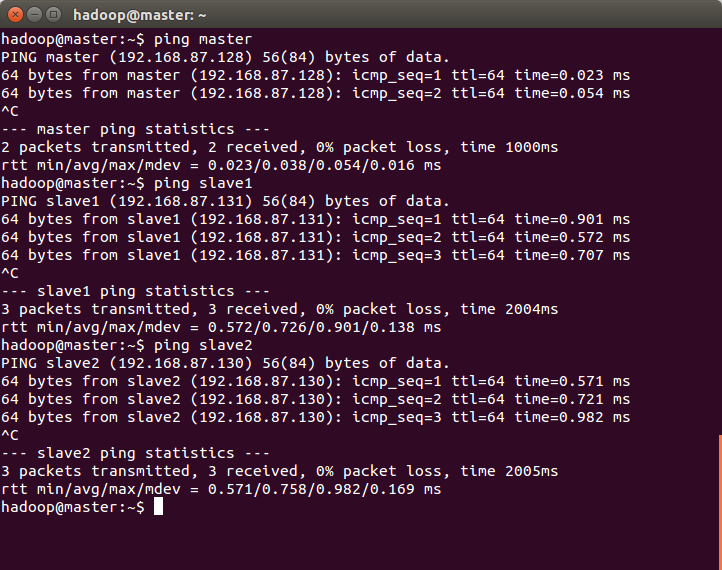
再各个机器间测试能否ping通:ping <hostname或者ip地址>
3.通过ssh实现免密码登陆,连接各个机器
1.首先在master中生成公钥、密钥,导入公钥,见伪分布配置中相关内容(http://www.cnblogs.com/zhangduo/p/4592749.html)
2.在其它机器上生成公钥、密钥,并将公钥文件发送(scp命令)到master
3.将master上的公钥导入authorized_keys,并将其发送到其它机器
4.验证,执行:
ssh <hostname>
4.修改配置文件
每台机器所有配置文件和安装文件都要求一致。
其中yarn-site.xml文件:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
</configuration>
其中hdfs-site.xml文件中dfs.replication的值不超过除master外机器的数量,故设为2。
slaves:
slave1
slave2
其他配置文件保持不变。
5.测试:
在master机器中进入hadoop目录,执行:
sbin/start-all.sh
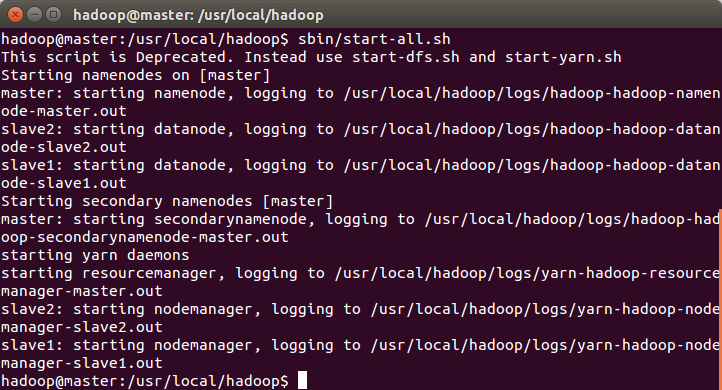
分别在master、slave1和slave2中执行:jps
master中:

slave1中:

slave2中:

通过Mahout运行kmeans实例:http://www.cnblogs.com/zhangduo/p/4679907.html
hadoop2.6.0集群配置的更多相关文章
- Hadoop-2.6.0 集群的 安装与配置
1. 配置节点bonnie1 hadoop环境 (1) 下载hadoop- 2.6.0 并解压缩 [root@bonnie1 ~]# wget http://apache.fayea.com/had ...
- hadoop-2.6.0集群开发环境配置
hadoop-2.6.0集群开发环境配置 一.环境说明 1.1安装环境说明 本例中,操作系统为CentOS 6.6, JDK版本号为JDK 1.7,Hadoop版本号为Apache Hadoop 2. ...
- Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作
前言 安装Apache Hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可,安装前需保证Hadoop已启(动文中用到了hadoop的hdfs命 ...
- Ubuntu12.04-x64编译Hadoop2.2.0和安装Hadoop2.2.0集群
本文Blog地址:http://www.cnblogs.com/fesh/p/3766656.html 本文对Hadoop-2.2.0源码进行重新编译(64位操作系统下不重新编译会有版本问题) ...
- 分布式Hbase-0.98.4在Hadoop-2.2.0集群上的部署
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3898991.html Hbase 是Apache Hadoop的数据库,能够对大数据提 ...
- 在Hadoop-2.2.0集群上安装 Hive-0.13.1 with MySQL
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3872872.html 软件环境 操作系统:Ubuntu14.04 JDK版本:jdk1 ...
- CentOS6.4上搭建hadoop-2.4.0集群
公司Commerce Cloud平台上提供申请主机的服务.昨天试了下,申请了3台机器,搭了个hadoop环境.以下是机器的一些配置: emi-centos-6.4-x86_64medium | 6GB ...
- redis5.0集群配置
介绍 redis自3.0版本以来支持主从模式的集群,可用哨兵监控集群健康状态,但这种方式的集群很不成熟,数据备份需要全量拷贝.在之后的版本才真正支持集群分片. 在redis5.0中去除了以redis- ...
- hadoop2.6.0集群搭建
p.MsoNormal { margin: 0pt; margin-bottom: .0001pt; text-align: justify; font-family: Calibri; font-s ...
随机推荐
- zzUbuntu安装配置Qt环境
zz from http://blog.csdn.net/szstephenzhou/article/details/28407417 安装 QT4.8.6库+QT Creator 2.5.0 下载地 ...
- Oracle trigger 触发器
触发器使用教程和命名规范 目 录触发器使用教程和命名规范 11,触发器简介 12,触发器示例 23,触发器语法和功能 34,例一:行级触发器之一 45,例二:行级触发器之二 46,例三:INSTEA ...
- 打开关闭oracle自动表分析
oracle 表的统计信息,跟他的执行计划很有关联 执行计划的正常是否,跟SQL的执行速度很有关系 首先讲解一下如何查看一个数据库的是否开启自动统计分析 1.查看参数:STATISTICS_LEV ...
- matlab 保存图片的几种方式
最近在写毕业论文, 需要保存一些高分辨率的图片. 下面介绍几种MATLAB保存图片的 方式. 一. 直接使用MATLAB的保存按键来保存成各种格式的图片 你可以选择保存成各种格式的图片, 实际上对于 ...
- python全栈开发从入门到放弃之装饰器函数
什么是装饰器#1 开放封闭原则:对扩展是开放的,对修改是封闭的#2 装饰器本身可以是任意可调用对象,被装饰的对象也可以是任意可调用对象#3 目的:''' 在遵循 1. 不修改被装饰对象的源代码 2. ...
- XE6移动开发环境搭建之IOS篇(2):安装虚拟机(有图有真相)
XE6移动开发环境搭建之IOS篇(2):安装虚拟机(有图有真相) 2014-08-15 22:04 网上能找到的关于Delphi XE系列的移动开发环境的相关文章甚少,本文尽量以详细的内容.傻瓜式的表 ...
- yii2 商品上下架
视图层 <td><?php if($value['is_on_sale'] == 1) {?><img src="../web/images/yes.gif&q ...
- Maven详解(转)
原文出自: http://www.cnblogs.com/hongwz/p/5456578.html http://ifeve.com/maven-1/ Maven介绍: Maven是一个强大的Jav ...
- C/C++之Qt正则表达式
引言 正则表达式(regular expression)就是用一个“字符串”来描述一个特征,然后去验证另一个“字符串”是否符合这个特征.比如 表达式“ab+” 描述的特征是“一个 'a' 和 任意个 ...
- Greatest Common Increasing Subsequence
/*HDU1423 最长公共递增*/ #include <stdio.h> #include <string.h> #include <iostream> usin ...